lm专题

NLP-预训练模型-2017:ULMFiT(Universal LM Fine-tuning for Text Classification)【使用AWD-LSTM;模型没有创新;使用多个训练小技巧】
迁移学习在计算机视觉有很大的影响,但现在的NLP中的方法仍然需要特定任务的修改和 从头开始的训练。我们提出通用语言模型微调,一种可以应用NLP任何任务中的迁移学习方法。我们模型在分类任务中都表现得良好,并且在小数据集上的表现优异。 一、ULMFiT (Universal Language Model Fine- tuning)组成步骤: a) General-domain LM pretr
![[论文笔记] eval-big-refactor lm_eval 每两个任务使用一个gpu,并保证端口未被使用](/front/images/it_default.gif)
[论文笔记] eval-big-refactor lm_eval 每两个任务使用一个gpu,并保证端口未被使用
1.5B在eval时候两个任务一个gpu是可以的。 7B+在eval belebele时会OOM,所以分配时脚本不同。 eval_fast.py: import subprocessimport argparseimport osimport socket# 参数列表task_name_list = ["flores_mt_en_to_id","flores_mt_en_to_vi"
![[论文笔记] lm_eval 每两个任务使用一个gpu,并保证端口未被使用](/front/images/it_default.jpg)
[论文笔记] lm_eval 每两个任务使用一个gpu,并保证端口未被使用
1.5B在eval时候两个任务一个gpu是可以的。 7B+在eval belebele时会OOM。 eval_fast.py: import subprocessimport argparseimport os# 参数列表task_name_list = ["flores_mt_en_to_id","flores_mt_en_to_vi","flores_mt_en_to_th","f

【论文速读】LM的文本生成方法,Top-p,温度,《The Curious Case of Neural Text Degeneration》
论文链接:https://arxiv.org/abs/1904.09751 https://ar5iv.labs.arxiv.org/html/1904.09751 这篇文章,描述的是语言模型的文本生成的核采样的方法,就是现在熟知的top-p 大概看看,还有几个地方比较有趣,值得记录一下。 摘要 尽管神经语言建模取得了相当大的进步,但从语言模型生成文本(例如生成故事)的最佳解码策略是什么仍然

LM Studio语言大模型部署软件搜索语言模型报错“Error searching for models ‘Network error‘”解决办法
我们利用 LM Studio 这款软件来可视化部署 Llama3语言大模型软件,官网选择好对应的操作系统下载安装包,在下载好之后进行安装。在安装好之后我们就可以打开软件并使用了,我们在搜索框内来搜索并安装 llama 系列的模型,不过在进行搜索时会发现搜索功能失效了,并且报错“Error searching for models ‘Network error’” 虽然有很多解决办法,但对于大

mybatis异常:Invalid bound statement (not found): com.lm.mapper.ArticleMapper.list
现象: 原因: 无效绑定,应该是mybatis最常见的一个异常了,接口与XML文件没绑定。首先,mapper接口并没有实现类,所以框架会通过JDK动态代理代理模式获取接口的代理实现类,进而根据接口全限定类名+id去一一绑定xml中的sql。 排查思路: 1)XML中的id 方法名与mapper接口的方法名是否一致,parameterType类型 与 resultType类型
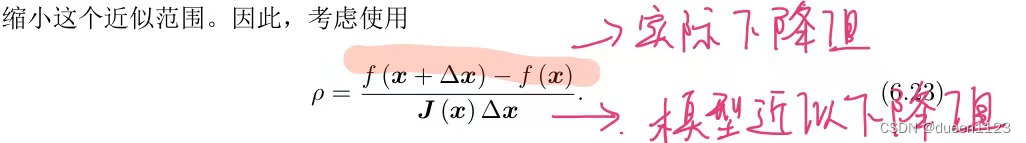
线性/非线性最小二乘 与 牛顿/高斯牛顿/LM 原理及算法
最小二乘分为线性最小二乘和非线性最小二乘 最小二乘目标函数都是min ||f(x)||2 若f(x) = ax + b,就是线性最小二乘;若f(x) = ax2 + b / ax2 + bx 之类的,就是非线性最小二乘; 1. 求解线性最小二乘 【参考】 2. 求解非线性最小二乘 需要用到牛顿法,高斯牛顿法,或者LM法 目标函数都是min F(x) = min ||f(x)||2
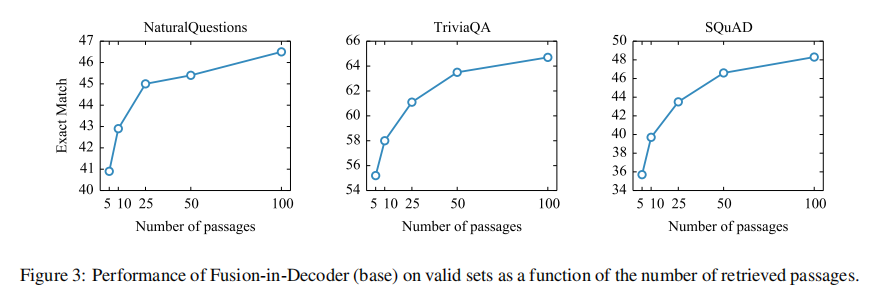
【RAG 论文】FiD:一种将 retrieved docs 合并输入给 LM 的方法
论文: Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering ⭐⭐⭐⭐ EACL 2021, Facebook AI Research 论文速读 在 RAG 中,如何将检索出的 passages 做聚合并输入到生成模型是一个问题,本文提出了一个简单有效的方案:FiD。

stata空间计量模型基础+检验命令LM检验、sem、门槛+arcgis画图
目录 怎么安装stata命令 3怎么使用已有的数据 4数据编辑器中查看数据 4怎么删除不要的列 4直接将字符型变量转化为数值型的命令 4改变字符长度 4描述分析 4取对数 5相关性分析 5单位根检验 5权重矩阵标准化 6计算泰尔指数 6做核密度图 7Moran’s I 指数 8空间计量模型 9LM检验 10Hausman 检验 11LR 检验 11检验是否退化 13Wald 检验 14交互效应
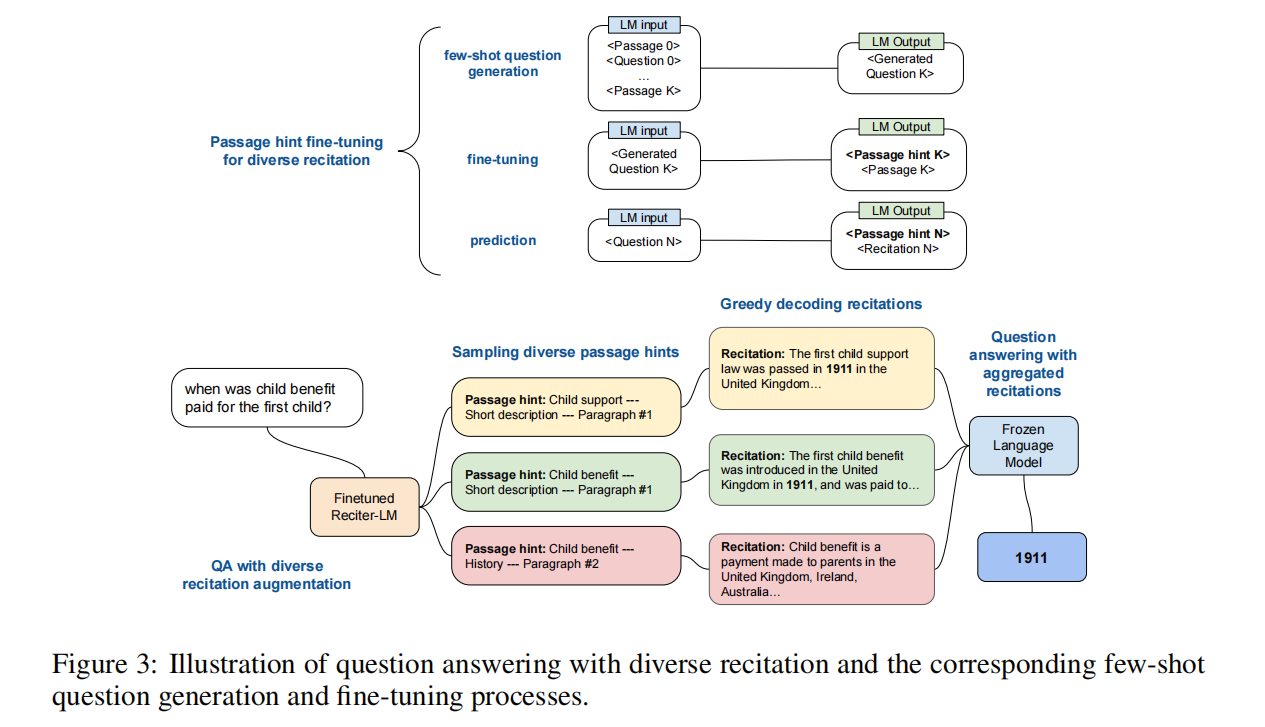
【LLM 论文】背诵增强 LLM:Recitation-Augmented LM
论文:Recitation-Augmented Language Models ⭐⭐⭐ ICLR 2023, Google Research, arXiv:2210.01296 Code:github.com/Edward-Sun/RECITE 文章目录 论文速读 论文速读 论文的整体思路还是挺简单的,就是让 LLM 面对一个 question,首先先背诵(recita

用LM Studio搭建微软的PHI3小型语言模型
什么是 Microsoft Phi-3 小语言模型? 微软Phi-3 模型是目前功能最强大、最具成本效益的小型语言模型 (SLM),在各种语言、推理、编码和数学基准测试中优于相同大小和更高大小的模型。此版本扩展了客户高质量模型的选择范围,在客户编写和构建生成式 AI 应用程序时提供了更实用的选择。 Phi-3 系列将增加更多型号,以在整个质量成本曲线上为客户提供更大的灵活性。Phi-3-smal

Levenberg-Marquardt (LM) 算法进行非线性拟合
目录 1. LM算法2. 调包实现3. LM算法实现4. 源码地址 1. LM算法 LM算法是一种非线性最小二乘优化算法,用于求解非线性最小化问题。LM主要用于解决具有误差函数的非线性最小二乘问题,其中误差函数是参数的非线性函数,需要通过调整参数使误差函数最小化。算法的基本思想是通过迭代的方式逐步调整参数,使得误差函数在参数空间中逐渐收敛到最小值。在每一次迭代中,算法通过

用 LM Studio 1 分钟搭建可在本地运行大型语言模型平台替代 ChatGPT
📌 简介 LM Studio是一个允许用户在本地离线运行大型语言模型(LLMs)的平台,它提供了一种便捷的方式来使用和测试这些先进的机器学习模型,而无需依赖于互联网连接。以下是LM Studio的一些关键特性: 脱机:用户可以在自己的笔记本电脑上运行LLMs,完全不需要在线连接。 用户界面:LM Studio提供了一个应用内聊天界面,用户可以通过这个界面与模型交互,或者使用一个与Open

Megatron-LM 验证1F1B interleaved的效果
Megatron-LM 验证1F1B interleaved的效果 1.创建容器2.安装Megatron-LM,准备数据集3.准备解析脚本4.PP4测试5.PP4 VP2 测试6.NCCL带宽测试 本文测试1F1B interleaved是否能挤掉空泡。因为所用的服务器不支持P2P,且PCIE为GEN1 X16 NCCL all_reduce_perf测试的性能仅为1.166GB
LM Studio:一个桌面应用程序,旨在本地计算机上运行大型语言模型(LLM),它允许用户发现、下载并运行本地LLMs
LM Studio是一个桌面应用程序,旨在本地计算机上运行大型语言模型(LLM)。它允许用户发现、下载并运行本地LLMs,支持在Windows、Linux和Mac等PC端部署2510。LM Studio的安装过程涉及访问其官网并选择相应操作系统的版本进行下载安装。安装成功后,用户可以通过该软件选择并运行心仪的模型,这些模型一般在huggingface上找到,重要因素包括模型的大小或参数量910。L

LM小型可编程控制器软件(基于CoDeSys)笔记二十一:错误3703
写程序的时候,无意在全局变量里输入了了两个新变量,而且都没有改默认名字,它们的名字都是name,所以会报这个错误。 这段英文的是:several declarations with the same identifier "name" 几个声明有着同样的标识符号“name” 意思就是有两个变量的名称是相同的。 要改过来很简单,把其中一个变量删掉就行了。
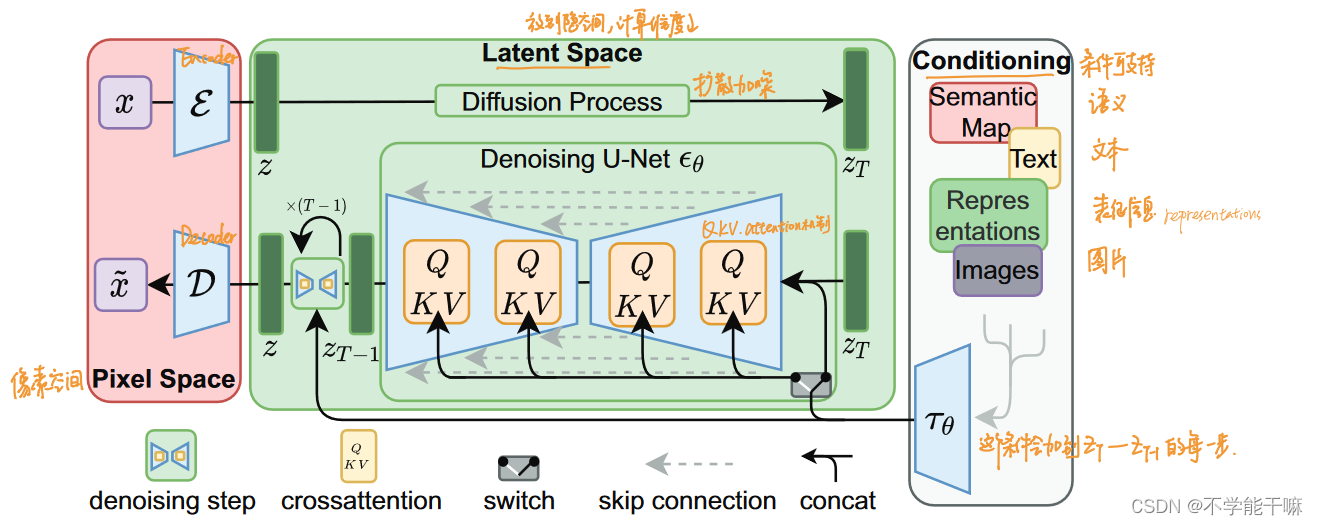
扩散模型的发展过程梳理 多个扩散模型理论知识总结/DDPM去噪扩散概率/IDDPM/DDIM隐式去噪/ADM/SMLD分数扩散/CGD条件扩散/Stable Diffusion稳定扩散/LM
前言 1.最近发现自己光探索SDWebUI功能搞了快两个月,但是没有理论基础后面科研路有点难走,所以在师兄的建议下,开始看b站视频学习一下扩散模型,好的一看一个不吱声,一周过去了写个博客总结一下吧,理理思路。不保证下面的内容完全正确,只能说是一个菜鸟的思考和理解,有大佬有正确的理解非常欢迎评论告知,不要骂我不要骂我。 2.这里推荐up主,deep_thoughts投稿视频-deep_thoug
一文读懂「LM,Large Model / Foundation Model」大模型
近年来,随着计算机技术和大数据的快速发展,深度学习在各个领域取得了显著的成果。为了提高模型的性能,研究者们不断尝试增加模型的参数数量,从而诞生了大模型这一概念。 一、什么是大模型? 1.1 概念介绍 一句话介绍就是:大模型,也称基础模型,是指具有大规模参数和复杂计算结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。。 这些模型通常由深度神经网
自然语言处理之语言模型(LM):用c++通过自然语言处理技术分析语音信号音高
要通过自然语言处理技术分析语音信号音高,我们可以采用以下步骤: 首先,我们需要获取语音信号的原始音频数据。可以使用C++中的音频处理库(例如PortAudio或ALSA)来捕获音频输入并将其转换为数字音频数据。 接下来,我们可以使用C++中的信号处理技术(例如傅里叶变换)将音频数据转换为频谱数据。频谱数据表示音频信号中不同频率的能量分布。 然后,我们可以使用自然语言处理库(例如NLTK或s
自然语言处理 | 语言模型(LM) 浅析
自然语言处理(NLP)中的语言模型(Language Model, LM)是一种统计模型,它的目标是计算一个给定文本序列的概率分布,即对于任意给定的一段文本序列(单词序列),语言模型能够估算出这段文本在某种语言中的出现概率。以下是语言模型的核心概念、作用、挑战及应用场景的解释: 核心概念 概率计算: 在自然语言处理的语言模型中,概率计算是指模型试图量化一个特定词序列出现的可能性。比如,对于一个
自然语言处理之语言模型LM的概念以及应用场景
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个分支,旨在让机器理解和生成人类语言。语言模型(Language Model, LM)是NLP中的一个核心组件,它用于评估一个句子或文本序列的概率分布,通常用于生成文本或进行文本分类。 语言模型(LM)的概念: 语言模型是一个可以预测给定文本序列中下一个词或符号的模型。它基于统计或机器学习的方法,
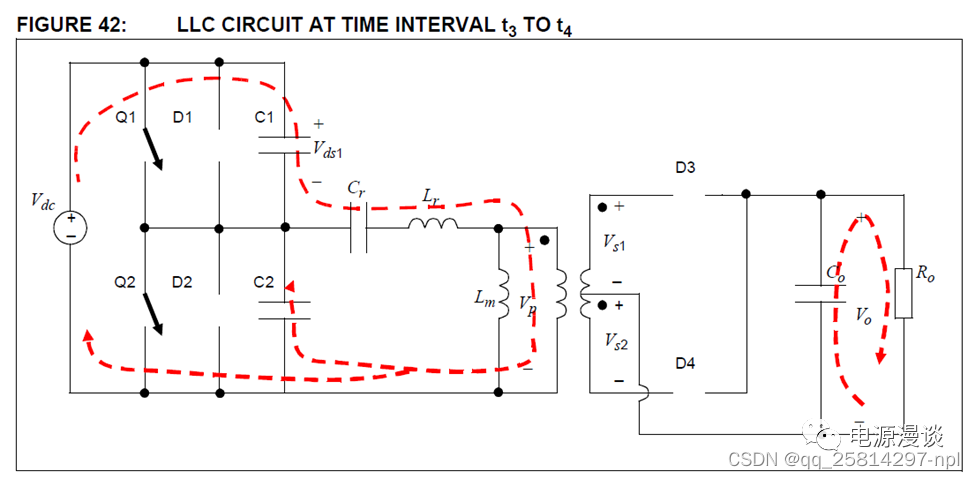
Cr,Lr,Lm构成谐振腔(Resonant tank),即所谓的LLC,Cr起隔直电容的作用,同时平衡变压器磁通,防止饱和。LLC电路的谐振工作模态浅析(通俗容易理解)原链接有图纸更易理解
在传统的开关电源中,通常采用磁性元件实现滤波,能量储存和传输。开关器件的工作频率越高,磁性元件的尺寸就可以越小,电源装置的小型化、轻量化和低成本化就越容易实现。但是,开关频率提高会相应的提升开关器件的开关损耗,因此软开关技术应运而生。 要实现理想的软开关,最好的情况是使开关在电压和电流同时为零时关断和开通(ZVS,ZCS),这样损耗才会真正为零。要实现这个目标,必须采用谐振技术。 二、LLC串联

冻结Prompt微调LM: T5 PET
T5 paper: 2019.10 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer Task: Everything Prompt: 前缀式人工prompt Model: Encoder-Decoder Take Away: 加入前缀Prompt,所有NLP任务都可
ChatGPT高效提问—基础知识(LM、PLM以及LLM)
ChatGPT高效提问—基础知识(LM、PLM以及LLM) 了解语言模型(language model, LM)、预训练语言模型(pre-trained language model, PLM)和大型语言模型(large language model, LLM)对于优化prompt非常重要。这些模型属于自然语言处理领域中最强大、最先进的技术之列,并广泛用于各种NLP任务,例如文本生成、文本分
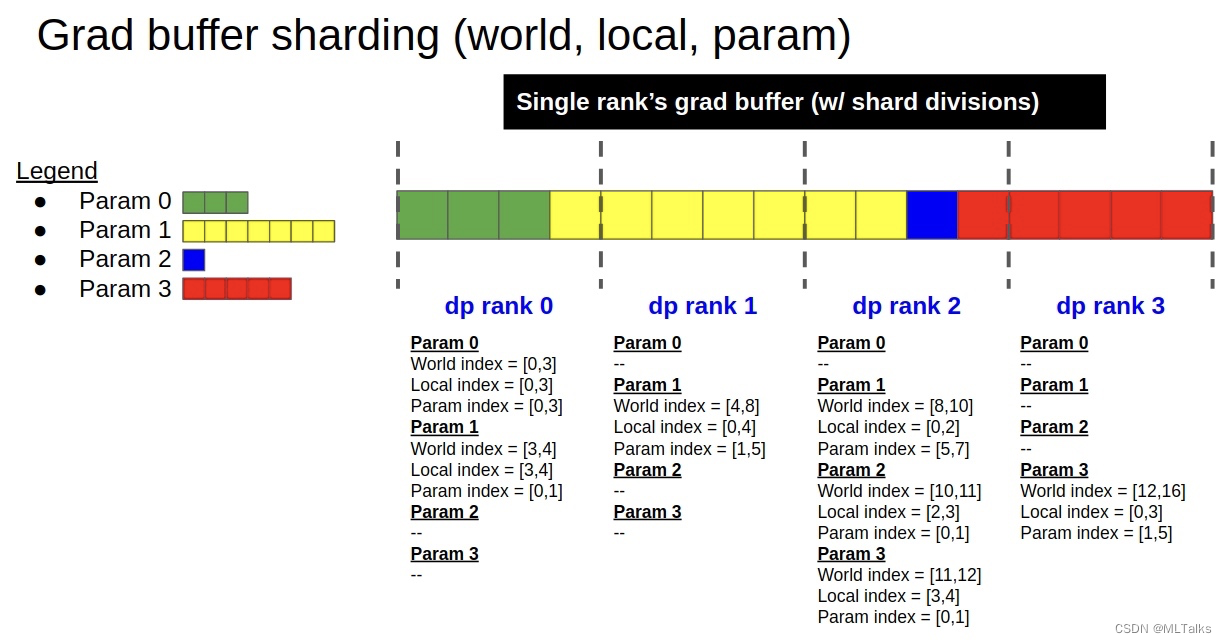
Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2
1. 使用入口 DistributedOptimizer类定义在megatron/optimizer/distrib_optimizer.py文件中。创建的入口是在megatron/optimizer/__init__.py文件中的get_megatron_optimizer函数中。根据传入的args.use_distributed_optimizer参数来判断是用DistributedOpti