本文主要是介绍2024 年,向量数据库的性能卷到什么程度了?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于数据库(尤其是向量数据库)而言,“性能”是一个十分关键的指标,其用于衡量数据库是否能够在有限资源内,高效处理大量用户请求。对于向量数据库用户而言,尽管可能在某些情况下对延时的要求不高,但对性能指标的高要求却一如既往,从未改变。
这也很好理解,原因在于:
-
基于近似最近邻搜索(ANNS)的向量搜索,可能会为了提高性能而牺牲一点精度。但性能的提高却可以让用户在满足相同业务需求场景下,扩大搜索、提高准确度。
-
在查询延迟相同,使用资源相同的情况下,数据库性能越高、吞吐量越高,可以适应更大的用户数量。
-
相同场景下,性能越高意味着需要更少的计算资源。
向量数据库本质上是计算密集型的数据库,在计算向量距离时需要使用大量资源——通常超过总体资源的 80%。因此,负责处理向量搜索任务的向量搜索引擎,是决定向量数据库整体性能的关键因素。
Zilliz 一直致力于提升向量数据库性能,无论是 Milvus(https://github.com/milvus-io/milvus) 还是全托管的 Zilliz Cloud(https://zilliz.com.cn/cloud),与竞品相比都展现出了卓越的性能。其中,Milvus 的向量搜索引擎 Knowhere(https://github.com/zilliztech/knowhere),发挥了重要作用,为新一代的向量搜索引擎奠定了基础。而 Zilliz Cloud 最近发布的核心向量搜索引擎 Cardinal,直接将搜索引擎的性能比原来提升了 3 倍,搜索性能(QPS)是 Milvus 的 10 倍。
我们通过开源向量数据库性能测试工具(https://github.com/zilliztech/VectorDBBench)评估了新版 Zilliz Cloud 的性能,并将其与使用旧引擎的 Milvus 和 Zilliz Cloud 进行了比较,评估结果如下图所示:
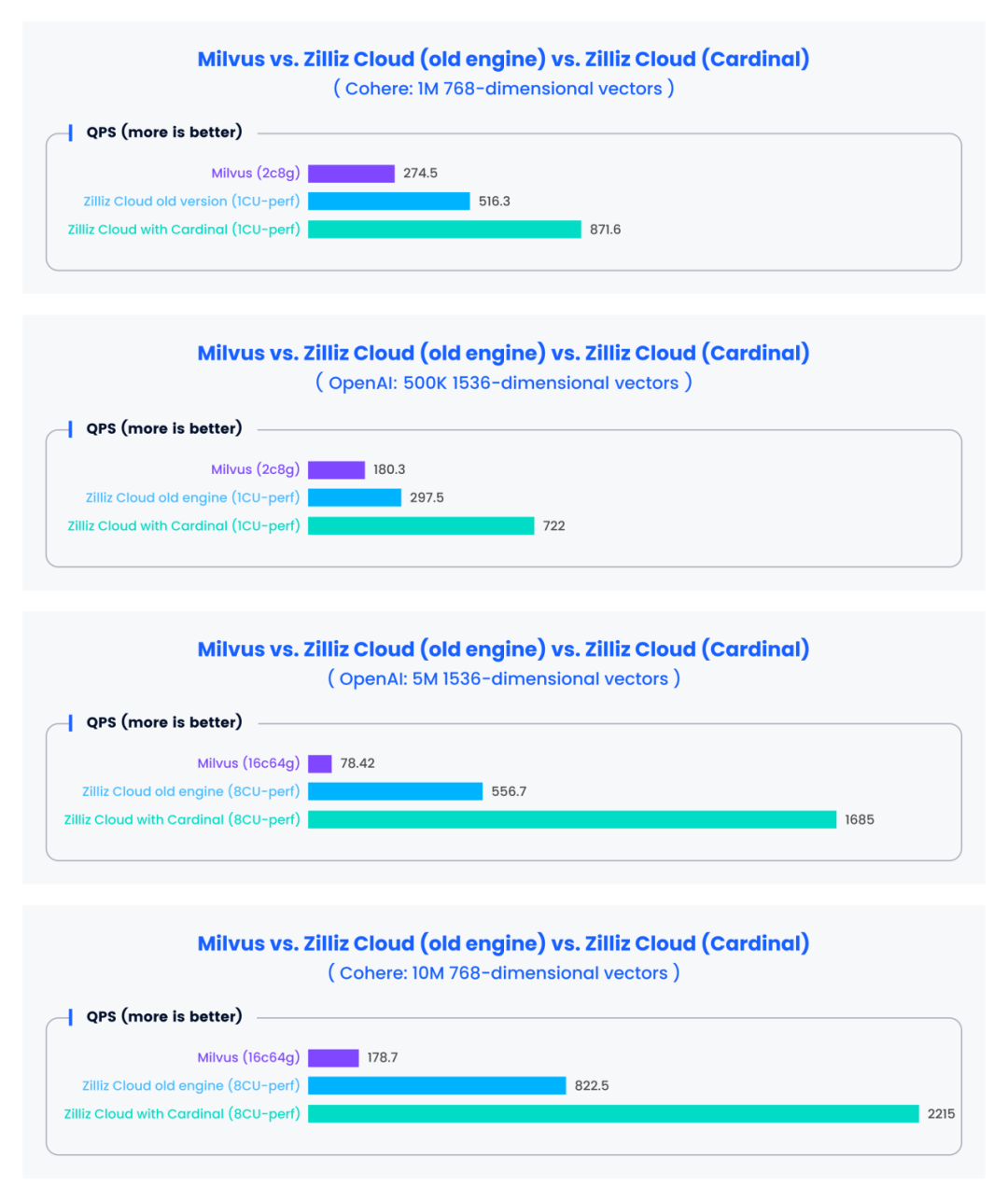
Cardinal 究竟是何方神圣?为何能有如此出色的表现?底层逻辑是什么?本文将一一揭晓。
01.Cardinal 是什么?
Cardinal 是 Zilliz 专门研发的多线程、基于 C++ 语言开发的向量搜索引擎,其整合了最实用、最流行的 ANNS 方法,使用 Cardinal 可以实现高效的计算资源使用率。
Cardinal 能够:
-
执行暴搜
-
创建和修改 ANNS 索引
-
执行索引 Top-K 和索引范围搜索(Range Search)
-
处理包括 FP32、FP16 和 BF16 在内的各种输入数据格式
-
使用内存中数据或提供基于内存、磁盘和 MMap 等不同方式的索引
-
根据用户提供的标准在搜索过程中过滤结果
Cardinal 的能力包括:
-
Zilliz internal 的高性能 ANN 算法实现,通过大量可调整参数适配多种场景。默认会自动调整参数适配不同的场景,在保持合理精度(召回率)的同时最大化搜索速度(QPS,每秒查询数)。
-
高效实现支持 ANNS 的各种算法,例如,提供样本过滤功能的算法。
-
为搜索或索引构建过程中大多数计算密集型操作优化的专用 low-level 内核,支持多种硬件平台。除了各种相似度类型外,Cardinal 还包含 fused 内核和数据预处理内核。
-
支持异步操作、内存映射 I/O 能力、缓存、内存分配器、日志记录等功能。
02.Knowhere vs Cardinal
Knowhere 是 Milvus 的内部核心引擎,负责向量搜索,是基于行业标准开源库(如 Faiss、DiskANN 和 hnswlib 等)的增强版本。
以下为 Knowhere 和 Cardinal 的比较结果:
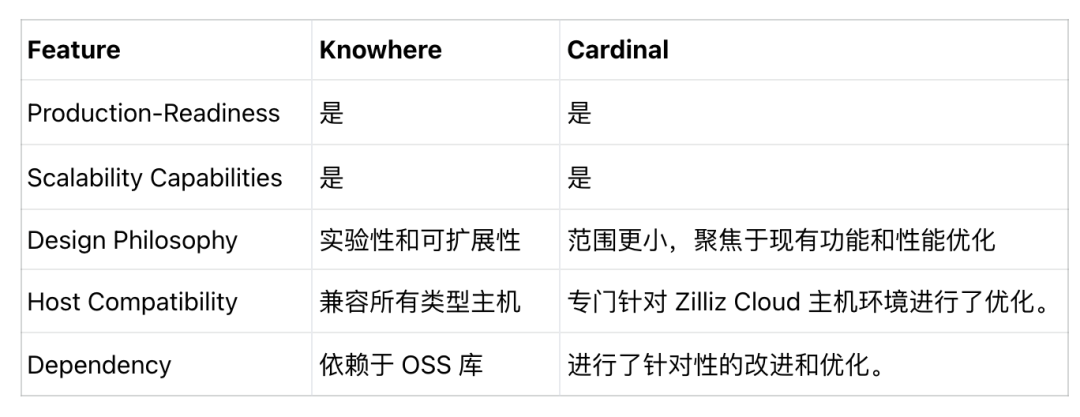
可以看到:
-
两者均已生产就绪,并提供 Milvus 和 Zilliz Cloud 所需的所有可扩展性。
-
Knowhere 设计时考虑到实验性和灵活性;Cardinal 的范围更狭窄,优先考虑增强现有功能以提高速度和性能,而不是引入广泛的新功能。
-
由于 Knowhere 属于开源,其部署环境更多样,可在所有主机类型上运行;Cardinal 则专门针对 Zilliz Cloud 主机环境进行了优化。
-
Knowhere 依赖于 OSS 库(如 Faiss、DiskANN 和 hnswlib);Cardinal 则进行了针对性的改进和优化。
03.Cardinal 高性能的原因
Cardinal 实现了各种与算法相关的工程优化,它引入了 AUTOINDEX 机制,自动选择适合于数据集最佳的搜索策略和索引。开发者无需手动调优,能够节省时间和精力。
算法优化
算法的优化显著提高了搜索过程的准确性和有效性,Cardinal 内部算法优化具体包括:
-
搜索算法,包括基于 IVF 和基于图的方法
-
帮助搜索保持所需召回率的算法,不论过滤样本的百分比如何
-
更高效的 Best-First 搜索算法迭代方法
-
定制了优先队列数据结构中的算法
将算法参数化帮助开发者灵活权衡性能与 RAM 使用率。因此,Cardinal 的算法优化还涉及在参数范围内选择最佳操作点。
工程优化
虽然算法最初是针对抽象的图灵机设计的,但真正实现时却面临着网络延迟、云提供商对 IOPS 的限制以及机器 RAM 限制等挑战(RAM 是一种宝贵而有限的资源)。
工程优化可以确保 Cardinal 的向量搜索 Pipeline 保持实用,并符合计算、RAM 和其他资源限制。在 Cardinal 的开发中,Zilliz 融合了标准实践和创新技术。这种方法使 C++ 编译器能够生成计算上最优的编译代码,同时保持标准化的性能测试、易于扩展的源代码,便于快速添加新功能。
以下是在 Cardinal 中工程优化的具体示例:
-
专门的内存分配器和内存池
-
合理的多线程代码
-
组件的层次结构,便于将元素组合成各种搜索 Pipeline
-
针对特定、关键用例的定制化代码
其他优化
-
搜索时间大部分都花在称为内核的相对较小的代码片段上,最简单的例子是计算两个向量之间 L2 距离的内核。Cardinal 中包括为不同目的编写和优化的众多计算内核,每个内核都针对特定的硬件平台和用例进行了特别优化。
-
Cardinal 支持 x86 和 ARM 硬件平台,同时也可以轻松添加其他平台。
其中,对于 x 86 平台,Cardinal 内核使用 AVX-512 的F、CD、VL、BW、DQ、VPOPCNTDQ、VBMI、VBMI2、VNNI、BF16 和 FP16 扩展。此外,我们还在探索使用新的 AMX 指令集。对于 ARM 平台,Cardinal 内核支持 NEON 和 SVE 指令集。
-
确保 Cardinal 为计算内核获取最优的代码。
为了实现这一点,我们不仅依赖现代 C++ 编译器,还使用专用工具,如 Linux perf 来分析热点和 CPU 指标;同时使用机器代码分析工具,如 GodBolt Compiler Explorer 和 uiCA,以确保最佳使用硬件“资源”,如 RAM/缓存访问次数、使用的CPU指令、寄存器、计算端口。此外,还使用迭代方法,交错进行设计、性能测试、性能分析和汇编代码分析阶段。
-
优化后的计算内核可能比一个简单但未优化的内核速度提升 2-3 倍,这可能进一步转化为 2 倍的 QPS 值,又或是在云主机机器上降低 20% 的内存要求。
AutoIndex:搜索策略选择
向量搜索是一个涉及许多独立组件的复杂过程,包括量化、索引构建、搜索算法、数据结构等。每个组件都有大量可调参数,它们共同形成了高度多样化的向量搜索策略范围,不同的数据集和场景需要不同的搜索策略。
为了更好地挖掘性能改进的潜力,Cardinal 除了支持每个组件中的多种策略外,还实现了一套基于 AI 的动态策略选择机制,称为 AUTOINDEX。它根据给定数据集的分布、提供的查询和硬件配置自适应选择最合适的策略,可以满足用户对搜索质量的需求的同时实现最佳性能。
04.Cardinal 性能测试
我们测试环境中采用了 ANN-benchmarks(https://github.com/erikbern/ann-benchmarks)。ANN benchmarks 是一个标准的性能测试工具,用于评估 ANNS 实现,并在使用不同距离度量的几个标准数据集上运行。每次性能评估都限定在单线程的 docker 容器内进行;指标基于多次评估迭代,并使用了大量单一查询请求;每个评估框架的结果汇总成一个“召回率 vs QPS”帕累托边界(Pareto frontier)。
所有测试都在与 ann-benchmarks 相同的机器类型上进行,即 Amazon EC2 r6i.16xlarge(https://aws.amazon.com/cn/ec2/instance-types/r6i/) 机器,配置如下:
-
CPU: Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz
-
CPU core: 32 核
-
禁用超线程
-
RAM: 512 GB
-
操作系统: Ubuntu 22.04.3 LTS , Linux 内核 6.2.0-1017-aws;未启用 huge page;测试使用--parallelism=31选项运行;使用 clang 17.0.6 compiler 编译 Cardinal。
下面呈现的性能测试结果仅针对 Cardinal 引擎,不包括 Zilliz Cloud 提供的其他非索引优化(包含 Zilliz Cloud 特定优化的结果可在文章开头获取)。
以下图表是通过 ANN-benchmark GitHub 页面上呈现的图表结果,并添加一个 Cardinal 曲线而生成的:
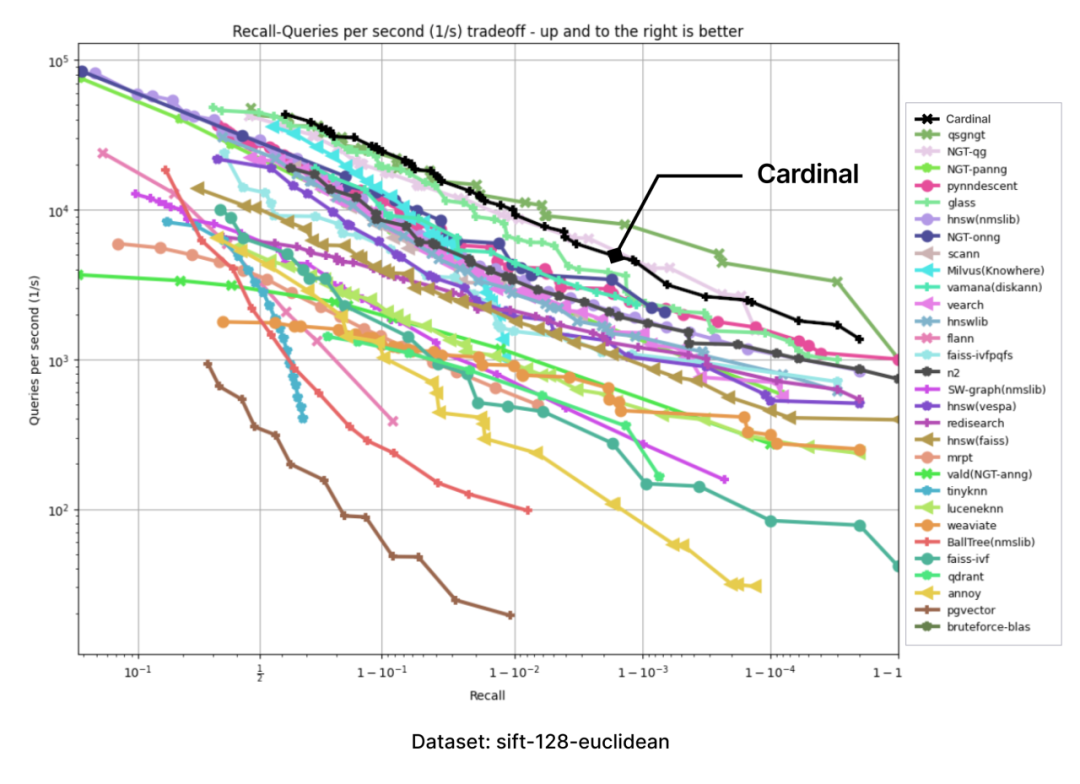
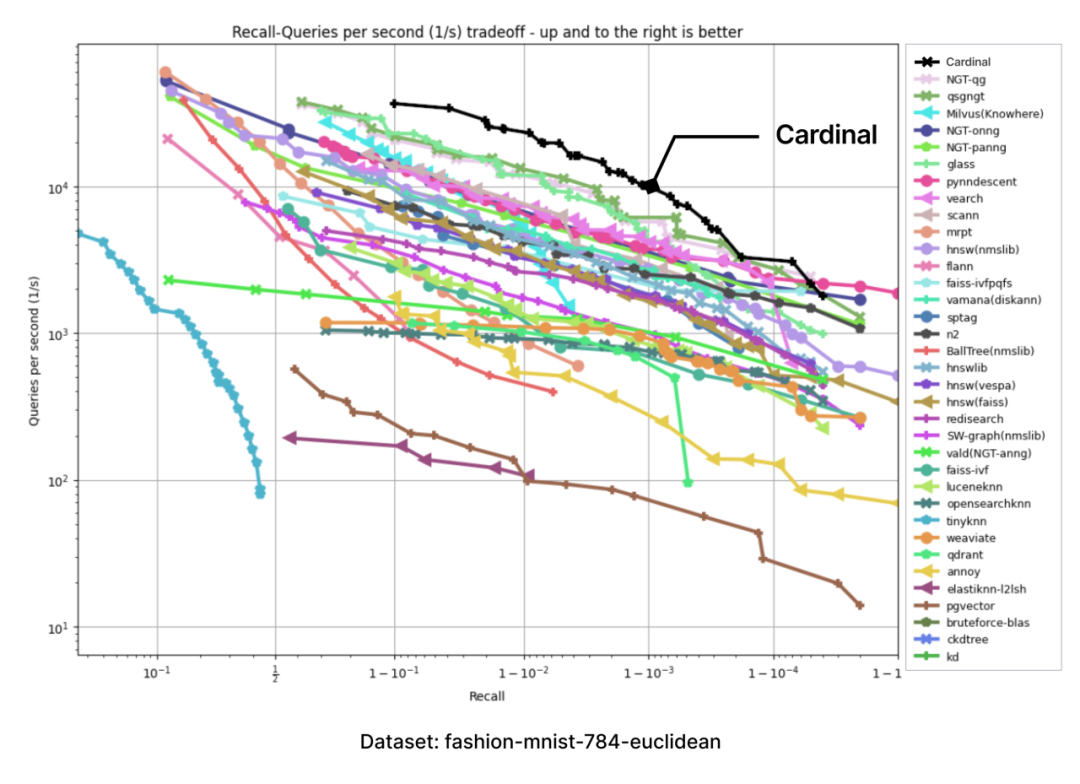
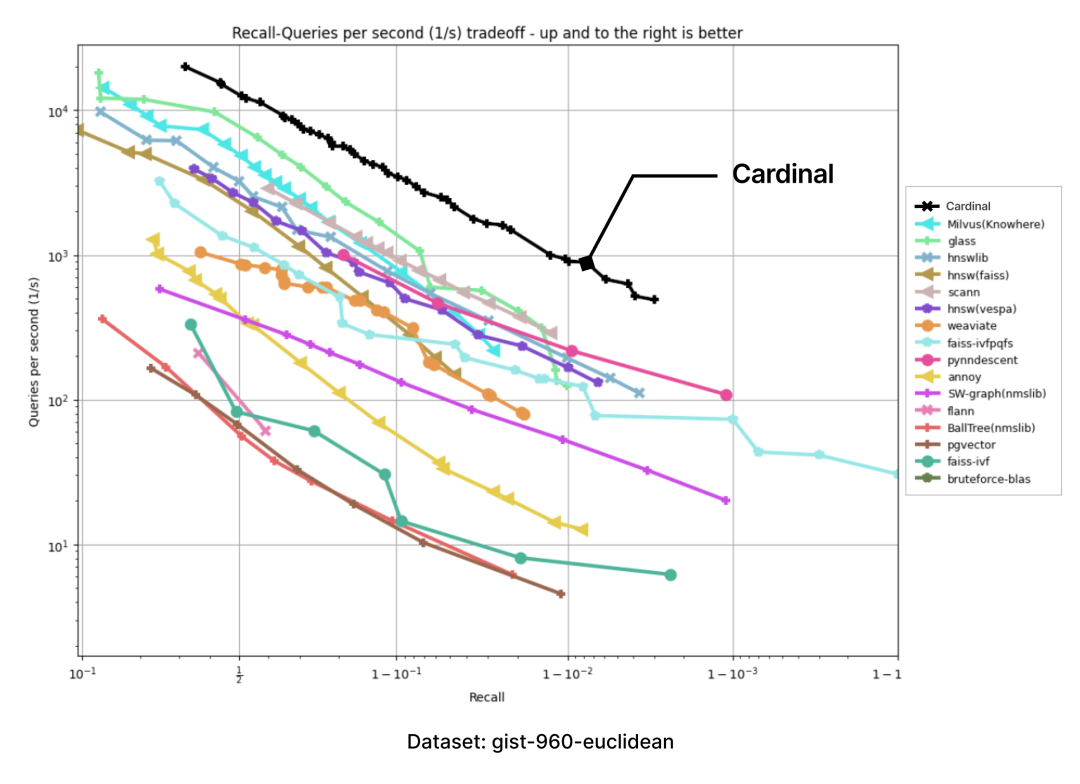
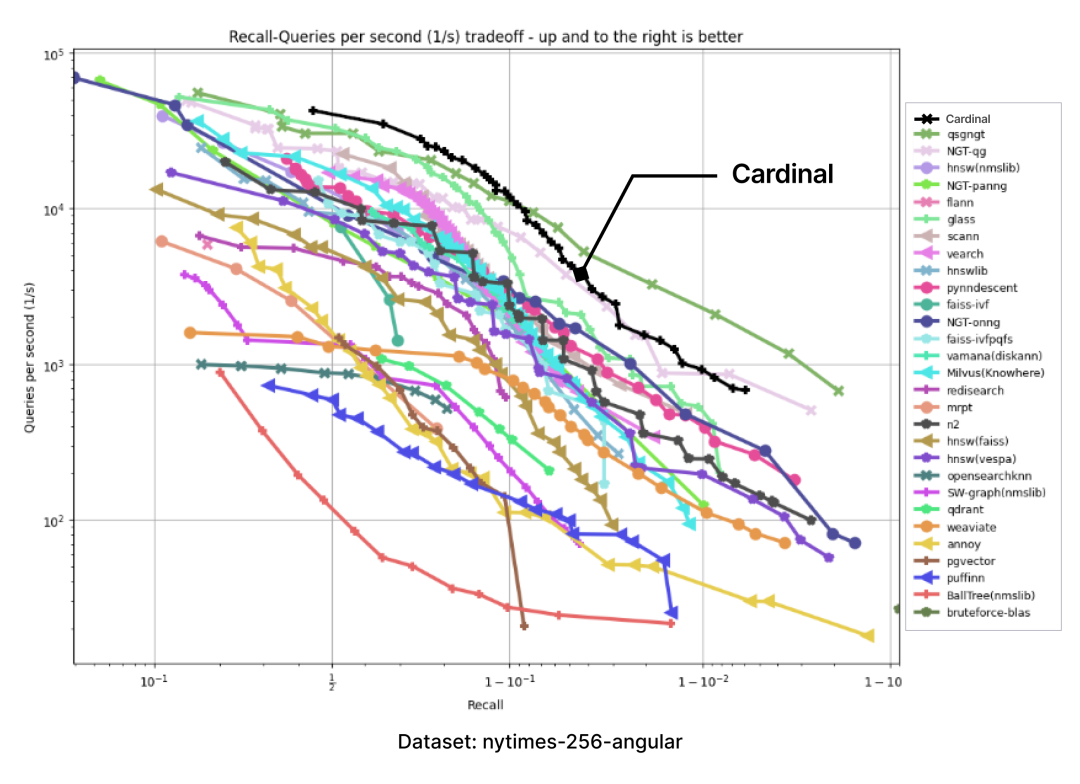
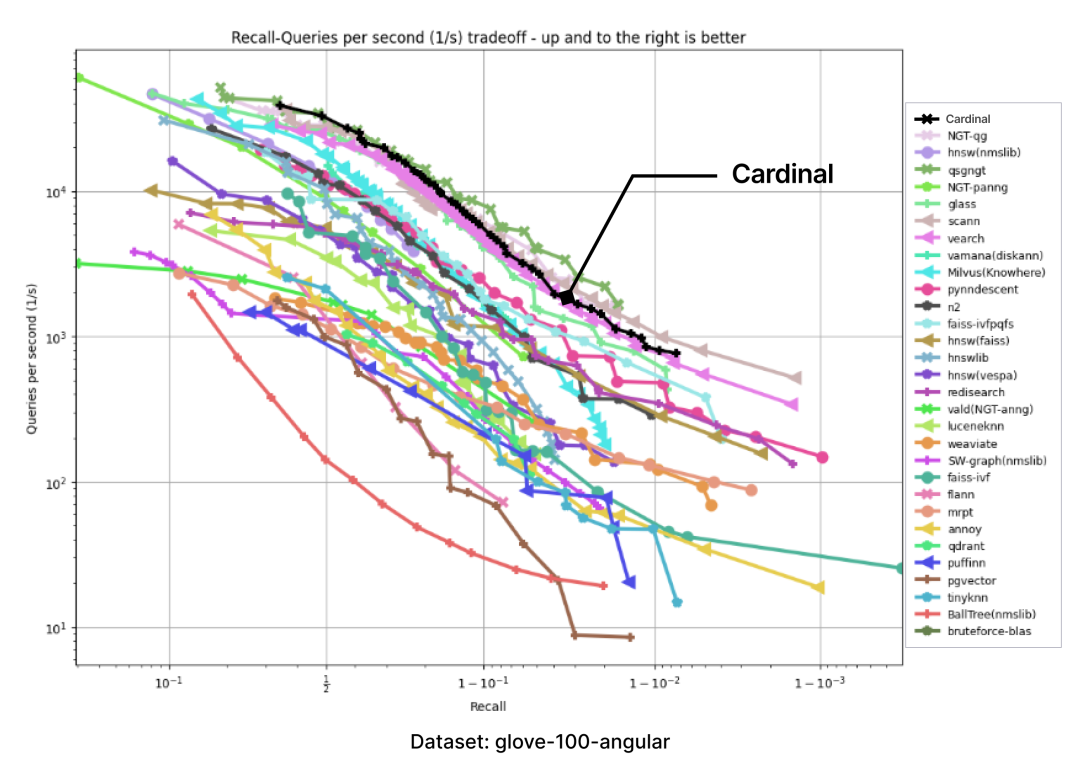
在所有性能测试中,Cardinal 的表现都十分出色。当然,我们未来还会面临更多挑战,例如要处理用户不同的需求、更大的数据集等,Cardinal 也需进一步成长,请大家拭目以待。
本文由 mdnice 多平台发布
这篇关于2024 年,向量数据库的性能卷到什么程度了?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





