datawhale专题

【深度学习详解】Task2 分段线性模型-引入深度学习 Datawhale X 李宏毅苹果书 AI夏令营
前言 《苹果书》第一章的内容包括 机器学习基础 -> 线性模型 -> 分段线性模型 -> 引入深度学习 这一篇章我们继续后续内容 ~ 其中涉及到“激活函数”的作用理解: 除了 开源项目 - 跟李宏毅学深度学习(入门) 之外, 还有 @3Blue1Brown 的神经网络 和 @StatQuest 的深度学习 视频内容辅助。 🍎 🍎 系列文章导航 【深度学习详解】Task1 机器学习基础-

Datawhale X 李宏毅苹果书 AI夏令营 - 跟李宏毅学深度学习(入门之线性模型)
文章目录 一、线性模型是什么?二、线性模型的特点三、简单举例理解3.1、预测未来某一天点击量3.2、分段线性曲线 总结 一、线性模型是什么? 在深度学习中,线性模型是一种简单但基础且广泛应用的数学模型。它的基本形式是一个线性方程,如y = wx + b,其中y是预测输出,x是输入特征,w是权重参数,b是偏置项(也称为截距)。 线性模型假设输入与输出之间存在线性关系,即输出是输

【无标题】【Datawhale X 李宏毅苹果书 AI夏令营】批量归一化
1、批量归一化的作用 批量归一化(Batch Normalization,BN)的把误差曲面变得平滑,使训练能够得到快速收敛; 训练过程的优化:使用自适应学习率等比较进阶的优化训练方法; 训练对象的优化:批量归一化可以改变误差表面,让误差表面比较不崎岖 参数 w i w_i wi是指训练参数或者训练的目标 1.1 特征归一化 当输入的特征,每一个维度的值,它的范围差距很大的时候,我们就可能

Datawhale X 李宏毅苹果书 AI夏令营-深度学习基础-Task3
# Datawhale AI 夏令营 夏令营手册:向李宏毅学深度学习 批量归一化 如果误差表面很崎岖,它比较难训练。而**批量归一化(Batch Normalization,BN)**的作用是把误差表面变得平滑,能够更好地训练。 在一个线性的的模型里面,当输入的特征,每一个维度的值,它的范围差距很大的时候,我们就可能产生像这样子的误差表面,就可能产生不同方向,斜率非常不同,坡度非常不同的误

【2024】Datawhale X 李宏毅苹果书 AI夏令营 Task3
本文是关于李宏毅苹果书”第2章 实践方法论“学习内容的记录。 模型在测试集上表现不佳,可能是因为模型没有充分学习训练集。模型不能充分学习训练集的原因: 模型偏差优化问题过拟合不匹配 一、模型偏差 模型偏差是指:由于模型过于简单,即便找到该模型的最优参数,模型的损失函数值实际还未达到最小。(想在海里捞针,但实际针不在海中) 此时可以通过重新设计模型、赋予模型更大灵活性降低模型偏差。 增加

Datawhale X 李宏毅苹果书 AI夏令营(深度学习 之 实践方法论)
1、模型偏差 模型偏差是指的是模型预测结果与真实值之间的差异,这种差异不是由随机因素引起的,而是由模型本身的局限性或训练数据的特性所导致的。 简单来讲,就是由于初期设定模型,给定的模型计算能力过弱,导致在通过梯度下降法进行优化以得到损失最小的函数过程中,模型表现太差,结果如同想要在大海里面捞针(一个损失低的函数),结果针根本就不在海里。 1.1、解决方案: 重新设计一个模型,给模型更大的

【Datawhale X 李宏毅苹果书 AI夏令营】《深度学习详解》Task3 打卡
文章目录 前言学习目标一、优化策略二、模型偏差三、优化问题三、过拟合增加训练集给模型一些限制 四、交叉验证五、不匹配总结 前言 本文是【Datawhale X 李宏毅苹果书 AI夏令营】的Task3学习笔记打卡。 学习目标 李宏毅老师对应视频课程:https://www.bilibili.com/video/BV1JA411c7VT?p=4 《深度学习详解》第二章主要介绍

Datawhale X 李宏毅苹果书 AI夏令营 入门 Task3-机器学习框架
目录 实践方法论1.模型偏差2.优化问题3.过拟合4.交叉验证5.不匹配 实践方法论 1.模型偏差 当一个模型由于其结构的限制,无法捕捉数据中的真实关系时,即使找到了最优的参数,模型的损失依然较高。可以通过增加输入特征、使用更复杂的模型结构或采用深度学习等方法来新设计模型,增加模型的灵活性。 2.优化问题 在机器学习模型训练过程中,即使模型的灵活性足够高,也可能由于优化算
Datawhale X 李宏毅苹果书 AI夏令营 进阶 Task3-批量归一化+卷积神经网络
目录 1.批量归一化1.1 考虑深度学习1.2 测试时的批量归一化1.3 内部协变量偏移 2.卷积神经网络2.1 观察 1:检测模式不需要整张图像2.2 简化 1:感受野2.3 观察 2:同样的模式可能会出现在图像的不同区域2.4 简化 2:共享参数2.5 简化 1 和 2 的总结2.6 观察 3:下采样不影响模式检测2.7 简化 3:汇聚2.8 卷积神经网络的应用:下围棋 1.

卷积神经网络(Datawhale X 李宏毅苹果书AI夏令营)
卷积神经网络(Datawhale X 李宏毅苹果书AI夏令营) 卷积神经网络是一种非常典型的网络 架构,常用于图像分类等任务。 一张图像是一个三维的张量,其中一维代表图像的 宽,另外一维代表图像的高,还有一维代表图像的通道(channel)的数目 通道:彩色图像的每个像素都可以描述为红色(red)、绿色(green)、蓝色(blue)的组 合,这 3 种颜色就称为图像的 3 个色彩通道。这种

DataWhale AI夏令营-《李宏毅深度学习教程》笔记-task3
DataWhale AI夏令营-《李宏毅深度学习教程》笔记-task2 第五章 循环神经网络5.1 独热编码5.2 RNN架构5.3 其他RNN5.3.1 Elman 网络 &Jordan 网络5.3.2 双向循环神经网络 第五章 循环神经网络 循环神经网络RNN,RNN在处理序列数据和时间依赖性强的问题上具有独特的优势,尤其是在自然语言处理和时间序列预测领域。 由图可知RN
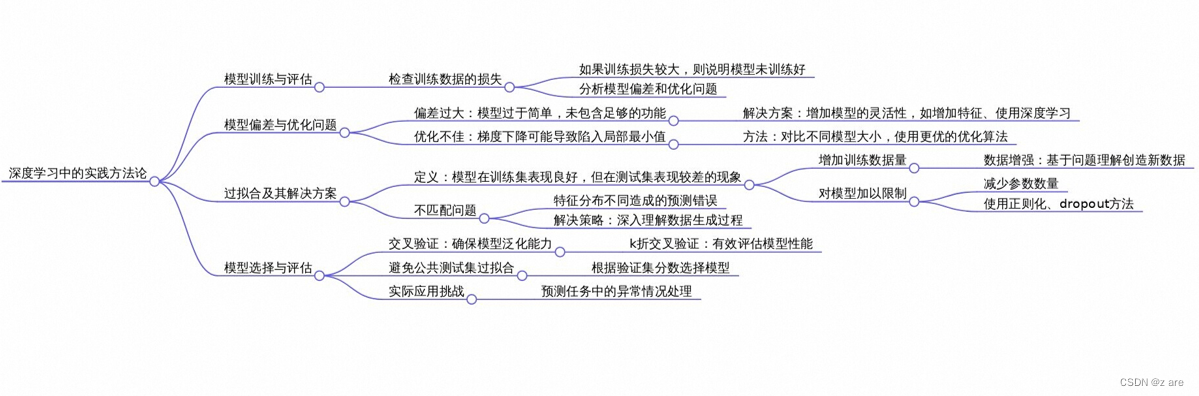
Datawhale x李宏毅苹果书AI夏令营深度学习详解入门 Task3
在深度学习中,模型偏差、优化问题和过拟合是我们经常会遇到的挑战。理解这些问题并找到合适的解决方法对于提高模型的性能至关重要。 第一章:模型偏差 1.1 模型过于简单可能导致模型偏差 在应用机器学习算法时,如果模型过于简单,就可能无法包含能够让损失变低的函数。例如,一个有未知参数的函数集合可能太小,无法涵盖最优的函数,导致即使找到了最优的参数,损失仍然不够低。

Datawhale X 李宏毅苹果书 AI夏令营 Task3打卡
实践方法论 1 模型偏差 1.1 基本概念 模型偏差(Model Bias),也称为“偏差误差”或“系统误差”,是指模型预测值与真实值之间的差异,这种差异并不是由随机误差引起的,而是由模型本身的结构或假设导致的。模型偏差通常反映了模型对数据的拟合程度不足。 高偏差模型的特征 在训练集和验证集上都有较高的误差。模型的预测结果与真实数据相差较大。模型对新数据的泛化能力差。

Datawhale X 李宏毅苹果书 AI夏令营 Task2打卡
线性模型(Linear model) 通常模型的修改来自于对问题的理解,即领域知识 基本定义:把输入特征x乘上一个权重,再加上一个偏置就可以得到预测的结果。 优点:简单易理解,可理解性好(权重w可以直观表达了各属性在预测中的重要性) 1 分段线性曲线 1.1 线性模型的局限性 Linear(线性)的Model太过简单,对于绝大多数的实际情况来说x1与y的关系不是简单的线

Datawhale X 李宏毅苹果书AI夏令营 学习笔记
学习日志 日期: 2024年8月30日 今日学习内容: 今天,我继续学习了深度学习中的优化算法,并且着重理解了如何利用动量法、RMSProp以及Adam等高级优化器来提高模型训练的效率和效果。 1. 动量法的理解: 我学习了动量法如何通过在参数更新时考虑之前的梯度方向,使得模型能够更快地朝着全局最优解的方向前进。动量法可以有效防止模型陷入局部最小值,并能够在陡峭的下降方向上加快收敛速度。

Datawhale X 李宏毅苹果书 AI夏令营 《深度学习详解》第三章 深度学习基础
3.1 局部极小值与鞍点 1、临界点及其种类 在我们的训练中是会存在梯度下降失效的问题的 提到梯度为零的时候,大家最先想到的可能就是局部极小值(local minimum) ,但其实损失不是只在局部极小值的梯度是零,还有其他可能会让梯度是零的点,比如鞍点(saddle point)。鞍点其实就是梯度是零且区别于局部极小值和局部极大值(lo
Datawhale X 李宏毅苹果书 AI夏令营|机器学习基础之线性模型
1. 线性模型 线性模型是机器学习中最基础和常见的模型之一。在线性模型中,预测变量(输入特征)和目标变量(输出)之间的关系被建模为一个线性组合。数学形式可以表示为: 其中:x 是输入特征向量,w 是权重向量,b 是偏置项,y 是模型的输出。 线性回归:线性回归是一种典型的线性模型,用于预测连续的数值型输出。它直接使用线性关系来进行预测,目标是找到一组权重 w 和偏置 b,使得模型

【Datawhale AI夏令营】从零上手CV竞赛Task3
文章目录 前言一、数据集增强二、设置 YOLO 模型训练参数三、模型微调总结 前言 本文的Task3对Task1的baseline代码继续进行优化的过程。 一、数据集增强 数据增强是机器学习和深度学习中常用的技术,用于通过从现有数据集中生成新的训练样本来提高模型的泛化能力。 常见的增强技术包括翻转、旋转、缩放和颜色调整。例如 Albumentations、Img

Datawhale AI 夏令营 第五期 CV Task3
活动简介 活动链接:Datawhale AI 夏令营(第五期) 以及CV里面的本次任务说明:Task 3 上分思路——数据集增强与模型预测 链接里的教程非常详细,主要是从三个方面(数据集增强、设置 YOLO 模型训练参数、设置 YOLO 模型预测行为和性能)来教我们在比赛中上分的技巧。 具体细节我就不赘述了,参看教程即可,这次我主要就Task3里的知识点做一下笔记,里面有些知识整理得真是非常

深度学习-HW3(CNN)卷积神经网络-图像分类-【Datawhale X 李宏毅苹果书 AI夏令营】
分类实际上是一个回归问题。 登录阿里云的账号,才发现有3个账号,要认证学生身份,试遍了3个账号后才试出学生认证号。打开看了一下,居然还有高校教师优惠申请,努力搞一个(最近是想薅一把教师资格证的福利,bushi)。 新建【交互式建模(DSW)】: 【打开】镜像: 打开Terminal:(真的使用命令行很少,很少) git clone https://www.modelscope.cn/da

【2024】Datawhale AI夏令营-从零上手Mobile Agent-Task2笔记
【2024】Datawhale AI夏令营-从零上手Mobile Agent-Task2笔记 本文介绍通义实验室最新的多模态手机智能体工作——Mobile-Agent。 一、大模型智能体背景 1.1 大模型智能体的优势 随着大模型的高速发展,大模型智能体成为热门研究方向,受到工业界和学术界的广泛关注。 在大模型智能体诞生之前,智能体主要基于强化学习(RL)设计,如OpenAI Five和
Datawhale X 李宏毅苹果书 AI夏令营 进阶 Task2-自适应学习率+分类
目录 1.自适应学习率1.1 AdaGrad1.2 RMSProp1.3 Adam1.4 学习率调度1.5 优化策略的总结 2.分类2.1 分类与回归的关系2.2 带有 softmax 的分类2.3 分类损失 1.自适应学习率 传统的梯度下降方法在优化过程中常常面临学习率设置不当的问题。固定的学习率在训练初期可能过大,导致模型训练不稳定,而在后期可能过小,导致训练速度缓慢。为了
Datawhale AI 夏令营-CV竞赛-Task3
# Datawhale AI 夏令营 夏令营手册:从零上手CV竞赛 比赛:2024“大运河杯”数据开发应用创新大赛——城市治理赛道 代码运行平台:厚德云 赛题任务 本赛题的任务是开发智能识别系统,用于自动检测和分类城市管理中的违规行为。通过对摄像头捕获的视频进行分析,自动准确识别违规行为,并及时向管理部门发出告警,以实现更高效的城市管理。 数据集增强 数据增强是机器学习和深度学习中常

Datawhale AI夏令营 第五期 CV方向 Task3笔记
Task3:上分思路——数据集增强与模型预测 Part1:数据增强 数据增强是机器学习和深度学习中的一种技术,通过在原始数据集上应用一系列变换来人工地增加数据样本的数量和多样性,从而提高模型的泛化能力,减少过拟合,并通过模拟不同的数据变化来增强模型对新数据的适应性。 以下是对几种数据增强方法的简单介绍: Mosaic Augmentation: 这种方法通过将四张不同的训练图像组

DataWhale AI夏令营 2024大运河杯-数据开发应用创新赛-task3
DataWhale AI夏令营 2024大运河杯-数据开发应用创新赛 数据增强数据收集打标签 多的不说少的不唠,之前说过初赛基本就是比谁的数据好了,因为原始数据的质量太低了想跑到0.25都很难所以需要使用一些数据增强策略以及收集一些新的数据集。 数据增强 计算机视觉中有一个应用比较广泛的包,来进行数据增强transforms,其中包含了一些图像增强的常见策略比如调整大小、裁剪、

Datawhale X 李宏毅苹果书 AI夏令营 Task 2
课程内容 (一)术语解释 一 . Sigmoid函数与Hard Sigmoid 函数 (1)Sigmoid函数 Sigmoid函数,也称为逻辑函数(Logistic function),是一种在数学、生物学、信息科学、神经网络等领域广泛应用的激活函数。也就是高中生物中所学的S型增长曲线。 它的数学表达式为: Sigmoid函数的图像呈现出S形的曲