本文主要是介绍批量生成大量附件(如:excel,txt,pdf)压缩包等文件时前端超时,采用mq+redis异步处理和多线程优化提升性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.首先分析一下场景:项目中我需要从财务模块去取单证模块的数据来生成一个个excel文件
在单证那个一个提单号就是一个excel文件,我们这边一个财务发票可能会查出几千个提单,也就是会生成几百个excel,然后压缩为一个压缩包,这个时候在前端的话肯定是会超时,从而导致无法下载附件压缩包。
二.解决方案:mq+Redis+多线程异步处理
我们废话不多说,直接上代码思路,代码有些是封装的,所以可能大家不一定能用,大家在流的处理和压缩上可以用自己熟悉的,我们主要讲这个优化的过程和思路。poi和Redis和mq的大家自己选着用就行,poi我的4.1.2版本。
三.分案分为三大步:
1.创建批次号,将这个下载的参数和状态存入Redis中,然后用mq异步调用下载方法,返回批次号给到前端
2.mq消费消息进行文件下载本地或服务器进行保存
3.前端设置一个监听器触发器和监听处理器,去拿到这个第一步返回的批次号进行状态查询,这里的查询时到Redis中去查询,因为状态会存在Redis中,如果已经下载完成,会返回这个状态true,这个时候我们再去调用第三个接口,下载附件并压缩返回给浏览器
多线程的异步处理优化可以加在第二步,对附件进行生成并保存的时候。
四、具体实现代码如下(仅供参考):
1.首先你得创建一个存放批次号的类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class FinAutoDownloadParamDTO implements Serializable {/*** 批次号*/private String batchNo;/***后续用于查询数据用的参数*/private List<Long> invoiceIds;
}
2.这里是第一步的方法,用雪花算法创建出一个唯一的批次号,然后作为Redis的key,将下载的信息状态存入其中,将paramsDto插入mq调用的方法中,这个Redis大家可以spring的或者引入的Redis依赖,注入对象get()和set()就行
public FinAutoDownloadFrResultVo exportFInToBookingExcelMQ(List<FinInvoiceReceiptVo> finInvoiceReceipts) {List<Long> invoiceIds = finInvoiceReceipts.stream().map(FinInvoiceReceiptVo::getFinInvoiceReceiptId).collect(Collectors.toList());if (CollectionUtils.isEmpty(invoiceIds)) {throw LocalizedExceptions.illegalArgument("Exception.data-no-select");}// 批次号,需保证该批次业务唯一String batchNo = snowFlakeGenerator.next().toString();String redisKey = FinConstant.FR_DOWN_PREFIX + batchNo;//校验批次号状态,如若正在计费则抛出异常Cache cache = FreightUtils.getCache();FinAutoDownloadParamDTO paramsDto = FinAutoDownloadParamDTO.builder().batchNo(batchNo).invoiceIds(invoiceIds).build();// 插入下载状态cache.put(redisKey, FinAutoDownloadStatus.builder().batchNo(batchNo).params(paramsDto).status(FinConstant.FinDownLoadStatus.PENDING).build());log.info("准备进行mq的舱单导出");finMqProducer.finManifestattachmentDown(paramsDto);log.info("财务舱单附件下载触发,参数:{}", com.gillion.ec.core.utils.JsonMapperHolder.jsonMapper.toJson(paramsDto));return FinAutoDownloadFrResultVo.builder().batchNo(batchNo).calcing(true).build();}
3.下面是mq来消费消息,获取Redis中的对象,来判断是否需要进行下载,下载过程创建线程池通过多线去下载,提高系统的响应速度,最后保存到你本地文件夹或者远程服务器
public void exportFInToBookingExcelMQDown(FinAutoDownloadParamDTO paramsDto) {// redis锁,防止重复String batchNo = paramsDto.getBatchNo();Cache cache = FreightUtils.getCache();String redisKey = FinConstant.FR_DOWN_PREFIX + batchNo;//获取redis中的对象,判断是否进行下载FinAutoDownloadStatus downloadStatus = cache.get(redisKey);if (Objects.isNull(downloadStatus)) {downloadStatus = FinAutoDownloadStatus.builder().batchNo(batchNo).params(paramsDto).status(FinConstant.FinDownLoadStatus.PENDING).build();}if (FinConstant.FinDownLoadStatus.RUNNING.equals(downloadStatus.getStatus())) {log.info("该业务批次正在下载,不能重复下载:{}", batchNo);return;}//这里我是获取业务数据进行后续附件的构造,你们按自己的需求去获取自己的数据就行//获取明细数据 拿到船名航次+提单号List<FinFreightItemR> execute = QFinFreightItemR.finFreightItemR.select().where(QFinFreightItemR.xsInvoiceId.in$(paramsDto.getInvoiceIds()).and(QFinFreightItemR.vesselNameEn.ne$(FinConstant.TOTAL_VESSELNAME))).limit(Integer.MAX_VALUE).execute();List<FinReceiveFreightFileVo> finFreightItems = CglibUtil.copyList(execute, FinReceiveFreightFileVo::new);Map<String, List<FinReceiveFreightFileVo>> finFreightsMap = finFreightItems.stream().collect(Collectors.groupingBy(item -> String.format("%s%s%s",item.getVesselNameEn(),item.getVoyageNo(),item.getSettlementCode())));List<VesselVoyageBlNoVo> vesselVoyageBlNoVoList =Lists.newArrayList();finFreightsMap.forEach((key,values)->{VesselVoyageBlNoVo vesselVoyageBlNoVo =new VesselVoyageBlNoVo();List<String> blNoList = finFreightItems.stream().map(FinReceiveFreightFileVo::getBlNo).distinct().collect(Collectors.toList());vesselVoyageBlNoVo.setBlNoList(blNoList);vesselVoyageBlNoVo.setOwnerCompany(values.get(0).getOwnerCompanyCode());vesselVoyageBlNoVo.setVesselCode(values.get(0).getVesselCode());vesselVoyageBlNoVo.setVoyageNo(values.get(0).getVoyageNo());vesselVoyageBlNoVo.setSettlementName(values.get(0).getSettlementName());vesselVoyageBlNoVoList.add(vesselVoyageBlNoVo);});//这个size很关键,是后续用于多线程等待的用的int size = vesselVoyageBlNoVoList.size();//创建CountDownLatch对象用于多线程计数final CountDownLatch latch =new CountDownLatch(size);String fileKey = null;String fileNameResult = null;String filePath = null;Long sysFileInfoId = null;Map<String, Object> resultMap = new HashMap<>();try {//压缩包名称String fileName = execute.get(0).getSettlementNameEn();String path = FileUtil.getTmpDirPath() + File.separator + UUID.randomUUID();String tempPath = path + File.separator + fileName;//创建一级文件夹FileUtil.mkdir(tempPath);for (VesselVoyageBlNoVo vesselVoyageBlNoVo : vesselVoyageBlNoVoList) {//设置正在下载setRuningStatus(cache, redisKey, downloadStatus);//线程池获取线程异步分批进行下载threadPoolTaskExecutor.execute(()->{List<DocBookingHeadToFinVo> docBookingHeadToFinVos = docBookingHeadInterface.queryBookingHeadByFin(Collections.singletonList(vesselVoyageBlNoVo));log.info("财务舱单导出查询结果集docBookingHeadToFinVos大小:{}",docBookingHeadToFinVos.size());log.info("财务舱单导出查询结果集docBookingHeadToFinVos:{}",JsonMapperHolder.jsonMapper.toJson(docBookingHeadToFinVos));if(CollectionHelper.isNotEmpty(docBookingHeadToFinVos)){Map<String, List<DocBookingHeadToFinVo>> docBookingHeadToFinVosMap = docBookingHeadToFinVos.stream().collect(Collectors.groupingBy(item -> String.format("%s%s%s", item.getVesselNameEn(), item.getVoyageNo(), item.getManifestOwner())));log.info("财务舱单导出查询结果集docBookingHeadToFinVosMap大小:{}",docBookingHeadToFinVosMap.size());docBookingHeadToFinVosMap.forEach((key,values)->{//二级附件文件夹String tempPathForSecAttch = tempPath + File.separator + key;FileUtil.mkdir(tempPathForSecAttch);Map<String, List<DocBookingHeadToFinVo>> docBookingMap = values.stream().collect(Collectors.groupingBy(DocBookingHeadToFinVo::getPol));for (Map.Entry<String, List<DocBookingHeadToFinVo>> entry : docBookingMap.entrySet()) {List<DocBookingHeadToFinVo> value = entry.getValue();try {exportCommExcel(value, tempPathForSecAttch,null, null);} catch (IOException e) {e.printStackTrace();}}});}//计数器减一latch.countDown();});}//线程等待,等待所有的异步线程都执行完后,才继续进行下一步latch.await();//压缩文件为zip tempath为我的一级目录File zipFile = ZipUtil.zip(tempPath);//将文件和路径存放于map中resultMap = getResultMap(zipFile, path);if(!resultMap.containsKey(EXPORT_FILE)){log.info("文件不存在:批次号{}", batchNo);return;}File zipFile2 = (File)resultMap.get(EXPORT_FILE);if(!FileUtil.exist(zipFile2)){log.info("文件导出失败:批次号{}", batchNo);return;}fileNameResult = zipFile.getName();filePath = zipFile.getAbsolutePath();//这里我们项目是将文件资源的byte流存远程,但是文件名和下载的关键key是放在数据库表中的,所有我这里会保存进去MultipartFile file = new MockMultipartFile(fileNameResult, fileNameResult, "", FileUtil.readBytes(zipFile));SysFileInfoDTO sysFileInfoDTO = sysFileInfoInterface.uploadFileForParam(FinConstant.ExcelUploadParam.UPLOAD_STRATEGY_ID,"Manifest_attachment_CW",Long.valueOf(paramsDto.getBatchNo()), file);fileKey = sysFileInfoDTO.getFileKey();sysFileInfoId = sysFileInfoDTO.getSysFileInfoId();}catch (Exception e) {log.error("文件下载失败:{}", e);} finally {//这里的fileKey,fileNameResult,sysFileInfoId就是我最后一步下载附件要用到的downloadStatus.setFileKey(fileKey);downloadStatus.setFileName(fileNameResult);downloadStatus.setSysFileInfoId(sysFileInfoId);setFinishStatus(cache, redisKey, downloadStatus);//我这里是建立的临时文件夹所有会把它删除掉FileUtil.del(filePath);if(resultMap.containsKey(EXPORT_FILE_TEMP_PATH)){String tempPath = (String)resultMap.get(EXPORT_FILE_TEMP_PATH);FileUtil.del(tempPath);}}}
5.设置下载的状态
```java
//正在下载
private void setRuningStatus(Cache cache, String redisKey, FinAutoDownloadStatus downloadStatus) {downloadStatus.setStatus(FinConstant.FinDownLoadStatus.RUNNING);cache.put(redisKey, downloadStatus);}
//下载完成private void setFinishStatus(Cache cache, String redisKey, FinAutoDownloadStatus downloadStatus) {downloadStatus.setStatus(FinConstant.FinDownLoadStatus.FINISH);cache.put(redisKey, downloadStatus);}//将文件和路径存放于map中private Map<String, Object> getResultMap(File zipFile, String path) {Map<String,Object> resultMap = Maps.newHashMap();resultMap.put(EXPORT_FILE,zipFile);resultMap.put(EXPORT_FILE_TEMP_PATH,path);return resultMap;}
5.查询是否附件以及全部生成并保存,没下载完FinReportDownoadVo 对象的FinishFlag字段值为false,给到前端去判断,然后继续调用查询,如果是true,则调用最后的下载方法```javapublic FinReportDownoadVo queryDownFrStatus(String batchNo) {FinReportDownoadVo frReportDownoadVo = new FinReportDownoadVo();if (StringUtils.isEmpty(batchNo)) {throw LocalizedExceptions.illegalArgument("Exception.fin.auto-freight.batch-no-is-empty");}String redisKey = FinConstant.FR_DOWN_PREFIX + batchNo;Cache cache = FreightUtils.getCache();FinAutoDownloadStatus status = cache.get(redisKey);if (Objects.isNull(status)) {throw LocalizedExceptions.illegalArgument("Exception.fin.down.batch-no-unmatch", batchNo);}log.info("FR 报表下载查询状态key={}状态为{}", batchNo, status.getStatus());if (!FinConstant.FinDownLoadStatus.FINISH.equals(status.getStatus())) {// 如若为空,则认定为MQ暂未消费// 如若不为空且状态不为完成,则认定为仍在消费中frReportDownoadVo.setFinishFlag(false);return frReportDownoadVo;} else {cache.del(redisKey);}frReportDownoadVo.setFinishFlag(true);frReportDownoadVo.setFileKey(status.getFileKey());frReportDownoadVo.setFileName(status.getFileName());frReportDownoadVo.setSysFileInfoId(status.getSysFileInfoId());return frReportDownoadVo;}
6.我这里前面说了下载资源已经保存到远程服务器,所以在查询状态的那步成功后会拿到这个filekey,我就你去远程下载这个压缩包的资源,在本地的在下载完那步不要删除,然后传文件的路径,通过IO流去本地获取是一样的。最后返回给页面就好了
public void downloadFile(FinReportDownoadVo downloadParam, HttpServletRequest request, HttpServletResponse response) {if(StrUtil.isBlank(downloadParam.getFileKey())){throw LocalizedExceptions.illegalArgument("Exception.fin.down-report.file-not-exist");}ResponseEntity<byte[]> downFile = sysFileInfoInterface.downloadFileByKey(downloadParam.getFileKey());if(Objects.isNull(downFile) || Objects.isNull(downFile.getBody())){throw LocalizedExceptions.illegalArgument("Exception.fin.down-report.file-not-exist");}log.info("舱单附件下载filename:{}",downloadParam.getFileName());try {Servlets.setFileDownloadHeader(request, response,downloadParam.getFileName());IOUtils.write(downFile.getBody(), response.getOutputStream());} catch (IOException e) {throw new RuntimeException(e);}finally {sysFileInfoInterface.deleteFile(downloadParam.getSysFileInfoId());}}
看看执行效果图吧:
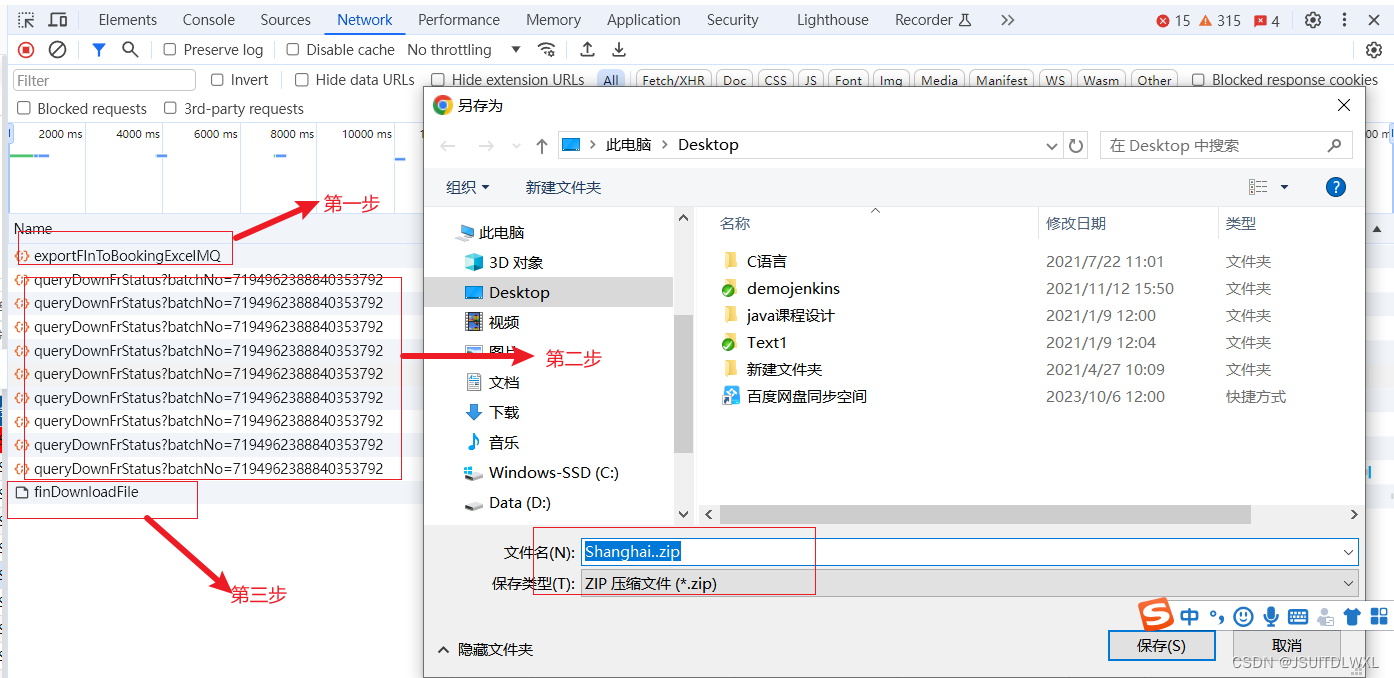
这篇关于批量生成大量附件(如:excel,txt,pdf)压缩包等文件时前端超时,采用mq+redis异步处理和多线程优化提升性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






