本文主要是介绍借助ArangoDB,带你玩转Google图算法引擎Pregel,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 借助ArangoDB,带你玩转Google图算法引擎Pregel |
| |
| |
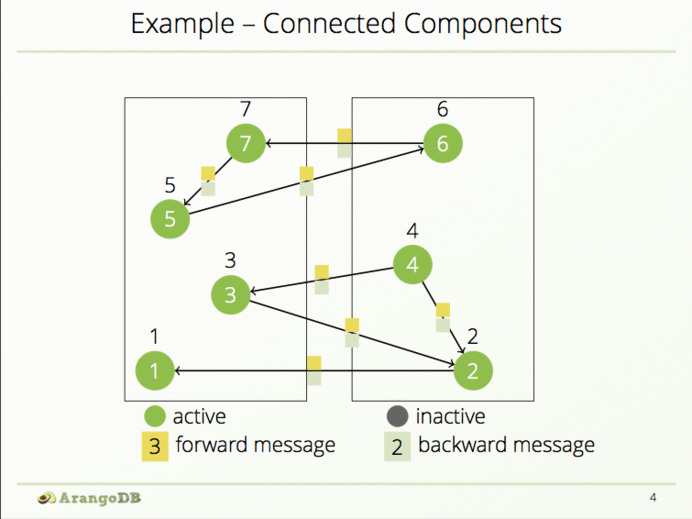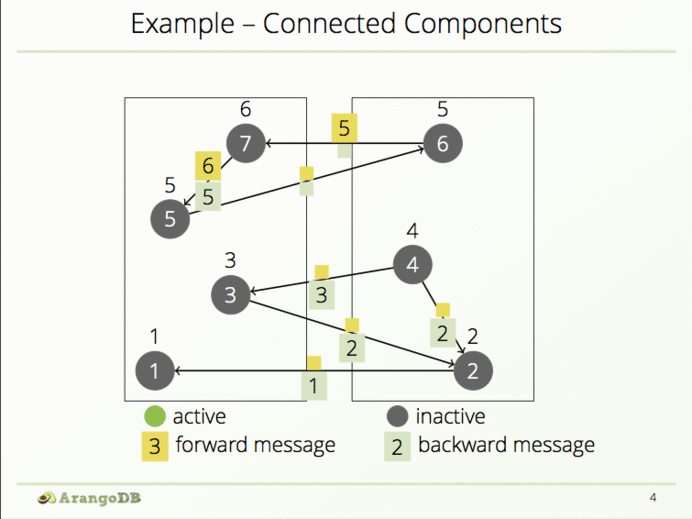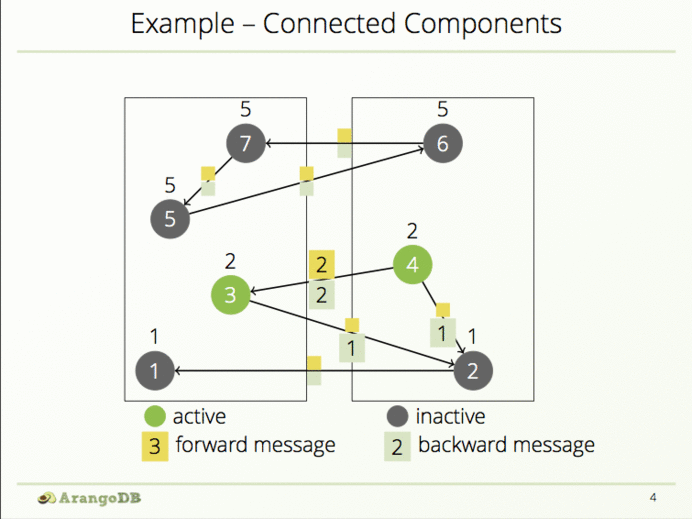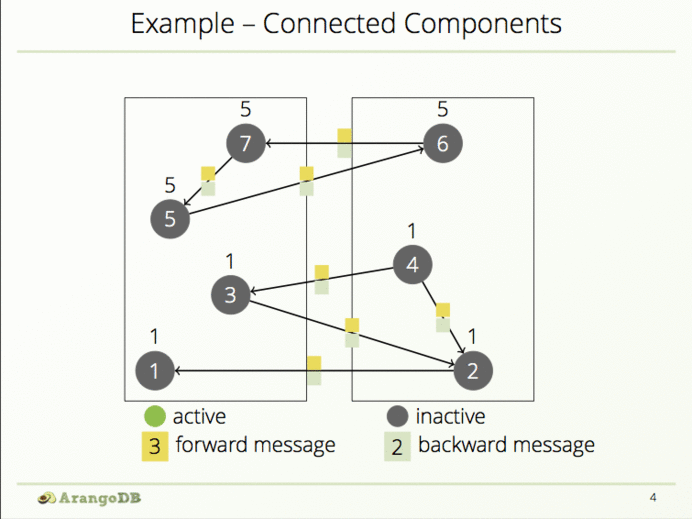
| ArangoDB团队研究出一种算法,能够在一个图中识别出已连接的子图,文中以国家为例;在ArangoDB中引入Pregel框架,通过Worker算法、合成算法、pregelRunner模块来执行不同的实现方式。来试试吧! ArangoDB团队研究出一种算法,能够在一个图中识别出已连接的子图,文中以国家为例;在ArangoDB中引入Pregel框架,通过Worker算法、合成算法、pregelRunner模块来执行不同的实现方式。开发者也可以自行编写算法,编程世界魅力无穷! 译文如下: Pregel作为Google推出的一种面向图算法的分布式编程框架,主要用于处理大规模的图算法计算。比如,图遍历(BFS)、最短路径(SSSP)、PageRank计算等。 检测“已连接节点”的算法 为了解决已连接节点的问题,ArangoDB团队研究出一种算法,能够在一个图中识别出已连接的子图。这里以国家为例子,下图包含10个国家,互相之间的关系定义为边界接壤(hasBorderWith),其形成的4种已连接节点组分别为: - 德国,奥地利,瑞士
- 摩洛哥,阿尔及利亚,突尼斯
- 巴西,阿根廷,乌拉圭
- 澳大利亚
要导入该图,请点击这里进行下载,然后打开ArangoShell并执行如下语句: 
Worker算法 Worker算法执行于图中每个顶点之上,每个顶点有一个相关的消息游标和一个global对象,里面含有步长信息和用户定义的Global数据。该算法定义如下: 
为了检测所有的节点组,这里使用了一种非常直接的方法: 每个节点组有一个字母标识符,存有其顶点最后的_key属性信息。所以,第0步的时候,每个顶点存储的是其自身的key信息以及初始邻近接壤节点信息。要访问源顶点需要使用_get(“someAttribute”)方法: 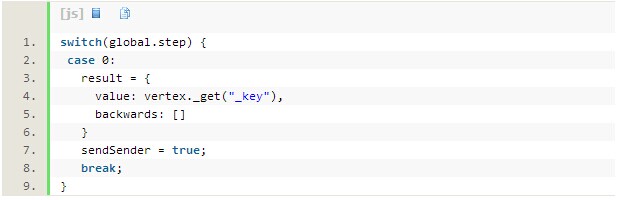
一个顶点只能访问其外部边界,因此在第1步的时候要记得把它所有接收到的消息放入数组中,以便进行向后通信,同时要根据传入的消息来更新节点组。 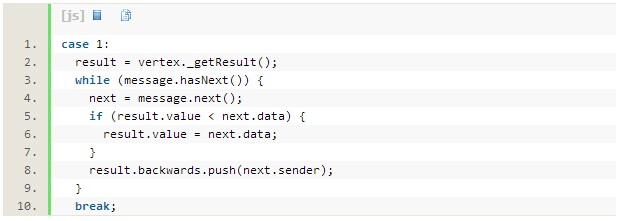
所以前两步的操作开启了向前和向后通信,接着执行算法直到每个顶贴都接收到其顶点组标识信息。因此,当接收到邻近标识符信息后,每个顶点需要更新顶点组标识信息: 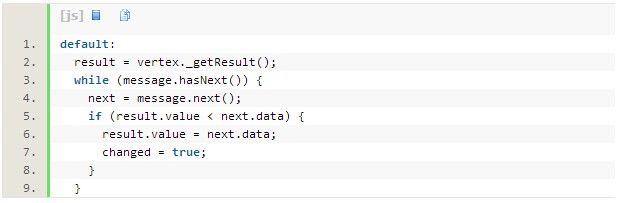
当一个顶点不再接收到新的消息或新的组标识时,要使它暂时失效。仅当再从邻近顶点接收新消息的时候进行激活: 
如果接收到新的组标识时要把结果进行存储: 
接着要通知邻近顶点,包括向前与向后: 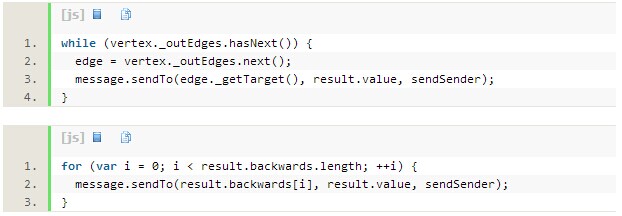
然后失效该顶点直到接收到新的消息: 
合成算法 为了减少冗余的消息使得工作者算法更加高效,ArangoDB团队引入了消息合成算法。比方说在该示例中,德国节点可能会收到来自奥地利和瑞士的消息;由于按字母排序,奥地利的消息可以忽略,从而减少不必要的消息接收。在Pregel中的消息合成器可定义为: 
合成器会筛选冗余消息,然后发送有效的标识信息: 
引入该算法后,德国节点虽然有两个接壤点,但是只会收到一个消息。 pregelRunner模块 首先创建Runner实例: 
Pregel算法的具体实现请点击这里进行下载。在Shell中载入该文件,使Runner可以实现相关函数: 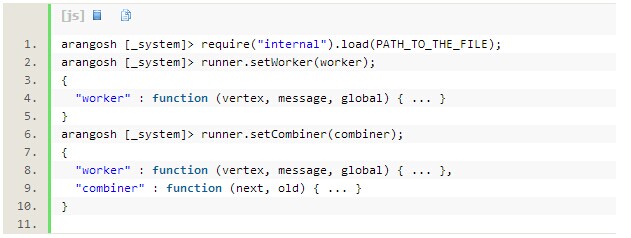
然后在图中启动Pregel: 
启动后会接收到唯一的执行码,可以使用runner来查阅当前运行状态: 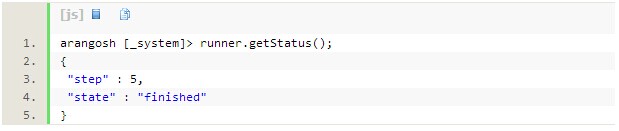
执行完毕后可以得到图的结果名: 
要检查该结果是否符合要求,可以载入全部顶点进行校对: 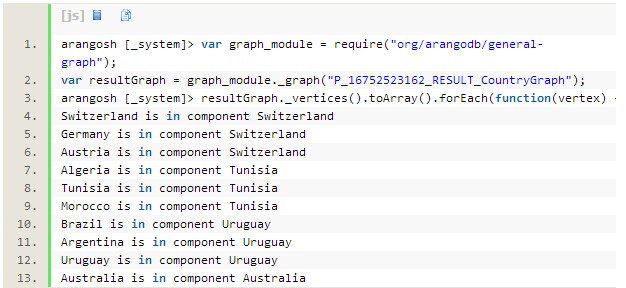
结果是正确的,算法能正确识别出4个子图(瑞士,突尼斯,乌拉圭,澳大利亚)。最后要做好收尾工作: 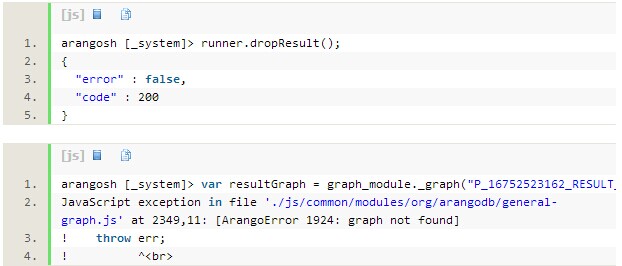
写在最后: ArangoDB仍在进一步完善pregelRunner以满足更大规模图处理的需求。很多受时间和内存限制的大型图问题在Pregel系统中都可逐步解决,例如:最短路径,图着色,最小生成树等。 |
|
这篇关于借助ArangoDB,带你玩转Google图算法引擎Pregel的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








