本文主要是介绍基于YOLO的车牌与车型识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
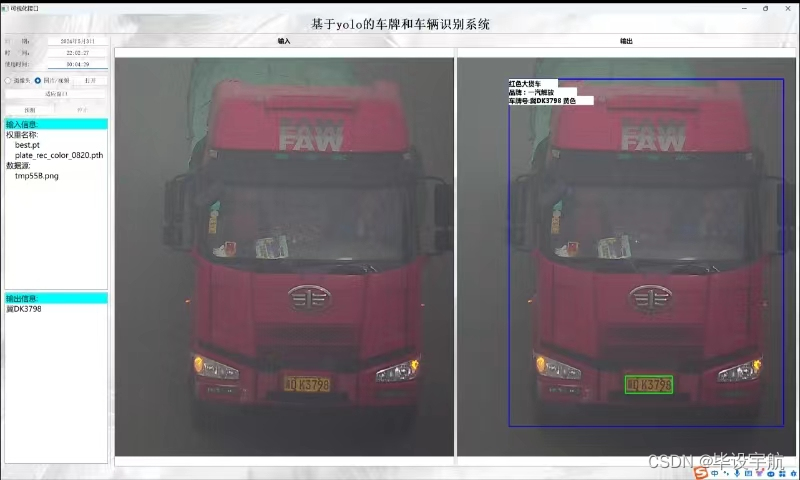
一、项目背景与意义
随着智能交通系统的快速发展,车辆识别技术在交通管理、安防监控、自动收费、停车管理等领域发挥着至关重要的作用。车牌识别和车型识别作为车辆识别技术的核心组成部分,能够有效提升交通运营效率,加强公共安全监控,促进智慧城市的建设。YOLO(You Only Look Once),作为一种先进的实时目标检测算法,以其高速度和高精度的特点,在物体检测领域展现了巨大潜力。本项目旨在结合YOLO算法的优越性能,开发一套高效、准确的车牌与车型识别系统。

二、项目概述
本项目旨在设计并实现一个集成化的系统,该系统能够从视频流或静态图像中实时检测、定位并识别出车辆的车牌号码及车型信息。系统主要分为以下几个核心模块:
- 数据预处理:对采集到的图像进行去噪、增强等预处理操作,以提高后续识别的准确性。
- 车辆检测:利用YOLO算法快速检测图像中的车辆,输出车辆的边界框位置。通过调整YOLO模型或使用特定于车辆的训练数据集,优化车辆检测的精确度和速度。
- 车牌定位与识别:在车辆检测的基础上,采用图像分割、边缘检测等方法精确定位车牌区域,并利用OCR(光学字符识别)技术识别车牌号码。此环节可引入深度学习模型进一步提高识别率。
- 车型识别:通过分析车辆的外观特征(如车头形状、车身比例等),结合深度学习分类器(如卷积神经网络CNN),实现对车辆型号的准确识别。
- 结果输出与应用:将识别出的车牌号码和车型信息整合,以用户友好的界面展示或通过API接口形式提供给其他系统使用,支持车辆追踪、交通流量分析等多种应用场景。
三、技术亮点
- 实时性与高效性:借助YOLO算法的高效推理能力,系统能在保证高识别准确率的同时,实现实时处理大量视频流数据。
- 自适应性:系统设计考虑了不同光照条件、角度变化、遮挡等因素,通过算法优化和数据增强提高在复杂环境下的识别稳定性。
- 深度学习模型优化:针对车牌和车型识别任务,对YOLO及后续识别模型进行定制化训练,提升模型的泛化能力和识别精度。
- 可扩展性:系统架构设计灵活,易于接入新的识别模型或功能模块,支持未来技术升级和功能扩展。
四、应用展望
本项目开发的车牌与车型识别系统,不仅能够应用于城市交通监控、停车场管理系统,还能服务于车辆违章检测、智能物流跟踪、保险定损等多个领域,为智慧城市建设和交通智能化管理提供强有力的技术支撑。随着技术的不断迭代与优化,该系统有望成为推动交通运输行业向更加智能化、高效化方向发展的重要工具。
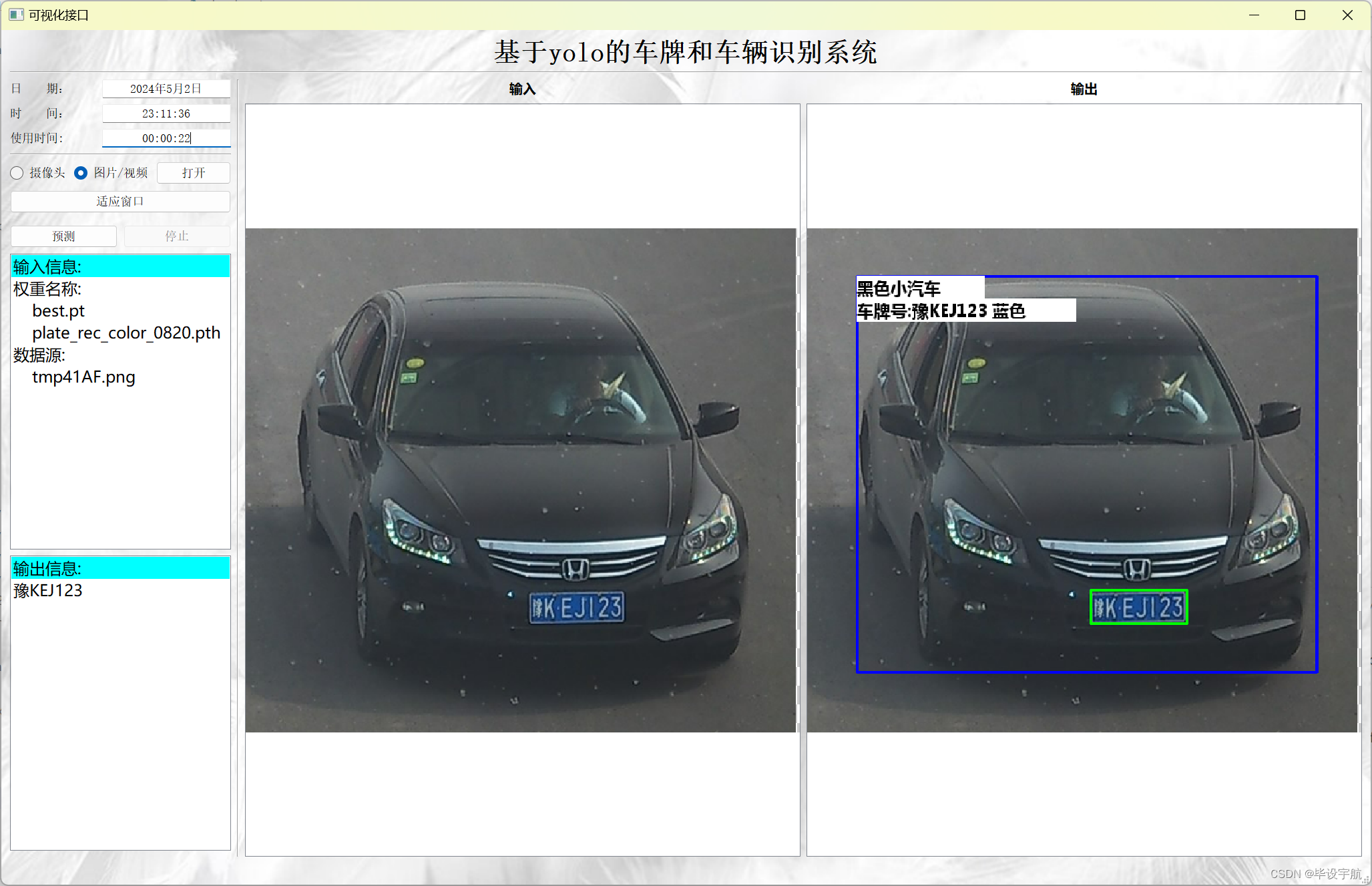
1. 导入所需库
import cv2
import numpy as np
from yolov5 import YOLOv5 # 假设使用的是YOLOv5库
from easyocr import Reader # 用于车牌识别的OCR库2. 初始化YOLOv5模型
yolo_model = YOLOv5('yolov5s') # 加载预训练的YOLOv5模型,这里以'yolov5s'为例,根据需求可选择其他模型变体3. 初始化OCR识别器
ocr_reader = Reader(['en']) # 初始化OCR,这里只使用英文,根据车牌语言可调整4. 车辆检测
def detect_vehicles(image):detections = yolo_model.detect(image)vehicle_boxes = [] # 存储车辆的边界框for detection in detections:if detection['class'] == 'car' or detection['class'] == 'truck': # 假设类别ID对应于车辆box = detection['box']vehicle_boxes.append(box)# 可以在这里直接绘制边界框,或者返回所有车辆的框用于后续处理return vehicle_boxes5. 车牌定位与识别
def locate_and_read_license_plate(image, vehicle_box):# 根据车辆框裁剪图像plate_region = image[vehicle_box[1]:vehicle_box[3], vehicle_box[0]:vehicle_box[2]]# 进一步处理以定位车牌(这部分可能需要更复杂的图像处理逻辑)# 假设已找到车牌区域,此处简化处理直接尝试OCRplate_text = ocr_reader.readtext(plate_region)# 简单处理识别结果,取置信度最高的结果if plate_text:plate_text = plate_text[0][1] # 通常第一个元素是置信度,第二个是文本return plate_text6. 车型识别
车型识别通常涉及更复杂的模型训练和分类,这里仅简述概念,实际实现可能包括特征提取、模型训练等步骤,这超出了简单示例的范畴。
7. 主循环处理视频流或图片
def process_video(video_path):cap = cv2.VideoCapture(video_path)while True:ret, frame = cap.read()if not ret:breakvehicles = detect_vehicles(frame)for box in vehicles:plate = locate_and_read_license_plate(frame, box)print(f"Detected Plate: {plate}")# 在图像上绘制边界框和车牌号(根据需要实现)# ...# 显示处理后的帧(如果需要)cv2.imshow('Vehicle Detection', frame)if cv2.waitKey(1) & 0xFF == ord('q'):breakcap.release()cv2.destroyAllWindows()这篇关于基于YOLO的车牌与车型识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)
![[数据集][目标检测]智慧农业草莓叶子病虫害检测数据集VOC+YOLO格式4040张9类别](https://i-blog.csdnimg.cn/direct/4a9ca83db964467783f221a1fd15ab5b.png)


![[数据集][目标检测]抽烟检测数据集VOC+YOLO格式22559张2类别](https://i-blog.csdnimg.cn/direct/cda7c7a3ea8348c5a8f4cddff90c679c.png)
![[数据集][目标检测]人脸口罩佩戴目标检测数据集VOC+YOLO格式8068张3类别](https://i-blog.csdnimg.cn/direct/088e80f82eb14e728a652ec9ba9fc6d4.png)
