本文主要是介绍数据设计:通过微调来优化SLM(小模型)的性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文地址:data-design-for-fine-tuning-to-improve-small-language-model-behaviour
2024 年 4 月 17 日
通过使用创造性的数据格式来微调数据,教授小语言模型进行自我纠正和推理。通过提示删除和部分答案屏蔽。

小语言模型通常缺乏自我意识,并且往往对其生成的响应表现出更大的信心。采用提示擦除和部分答案屏蔽 (PAM) 方法可显着提高 SLM 响应的质量。
介绍
似乎在最近的过去,当谈到语言模型(LLM 和 SLM)时,焦点一直集中在数据交付部分。换句话说,如何在推理时将专有数据引入语言模型。
数据传输过程可以分为两种主要方法:梯度方法和非梯度方法。非梯度方法因其透明而不是像梯度/微调方法那样不透明而受到广泛关注。
到目前为止,最流行的非梯度数据传输方法是 RAG 及其所有变体。
我发现有趣的是,一些微调/梯度方法的主要目的并不是将企业或领域特定数据注入语言模型。而是通过微调数据的结构、特定任务来改变模型的行为并教授模型。这些任务包括推理和自我纠正等功能。
数据设计
重点从数据交付转向数据设计,其中数据格式的设计方式是为模型赋予特定的行为能力。
推理
微软研究院训练 Orca-2 的主要重点是创建一个擅长推理的开源小语言模型 (SLM) 。这是通过分解问题并逐步解决它来实现的,这增加了可观察性和可解释性。
为了实现这一目标,必须创建细致入微的培训数据,向LLMs提出复杂的提示,其设计目的是引出策略推理模式,从而产生更准确的结果。
此外,在训练阶段,较小的模型会接受任务以及LLMs的后续输出。LLMs的输出数据定义了LLMs如何解决问题。
但这里有一个问题,原始提示不会显示给 SLM。这种“即时擦除”方法是一种将 Orca-2 变成谨慎推理机的技术,因为它不仅学习如何执行特定的推理步骤,还学习如何在更高层次上制定如何完成特定任务的策略。
LLMs不是天真地模仿强大的LLMs,而是被用作行为的储存库,从中为当前任务的方法做出明智的选择。
自我修正
最近的一项研究通过提出一种称为部分答案屏蔽(PAM)的方法,提出了构建自校正训练数据的管道,旨在通过微调使模型具有内在的自校正能力。
部分答案屏蔽的目标是指示语言模型进行自我纠正。
答案屏蔽
本研究通过在两项任务中使用参数大小从 60 亿到 130 亿不等的语言模型进行实验。
该研究引入了一种增强小语言模型自我纠正能力的方法,提出了内在自我纠正(ISC),这是一种依赖两种基本能力的机制:自我验证和自我修改。
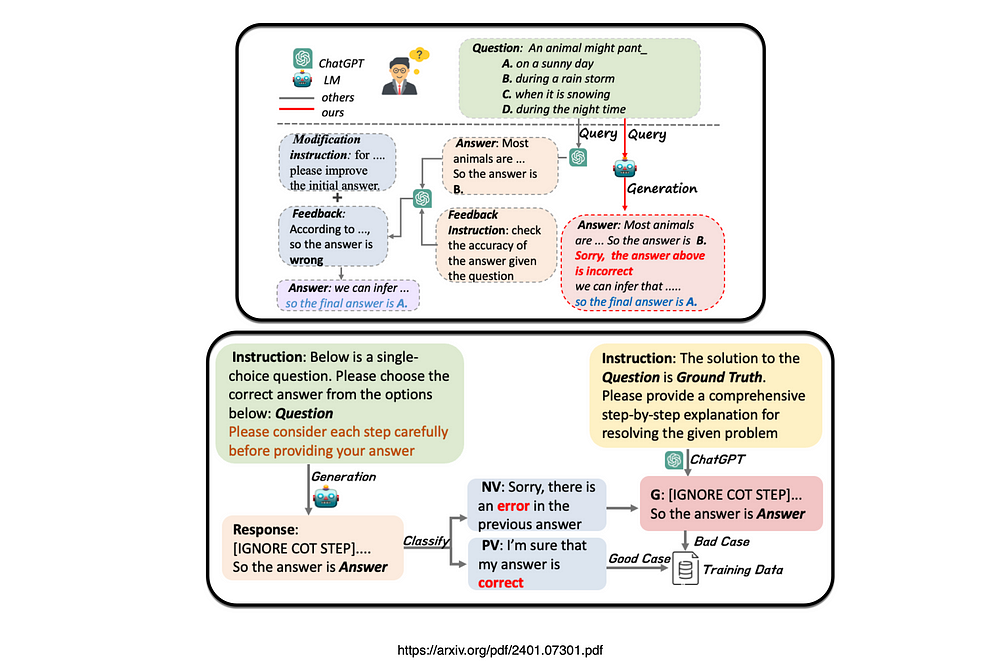
在微调阶段,该过程引入部分答案屏蔽(PAM),为模型注入自我验证功能。
结果首次证明,即使是只有 60 亿个参数的小型语言模型,在响应生成过程中也具有固有的自我校正能力,与地面事实的依赖无关。
所提出的内在自我纠正努力将自我纠正作为一种固有模式嵌入到语言模型中。它需要一个自主且自发的自我修正过程,与现有的即时工程方法不同。
为了使小语言模型具有自纠错能力,设计了一种用于构建自纠错数据的管道并建立了可普遍应用于生成自纠错任务的数据的数据格式。
综上所述
这两项研究提出了一种方法,即创建细致入微的训练数据,为小语言模型 (SLM) 灌输特定的推理和自我纠正技能。
微调通常与向模型添加知识、增强模型的知识相关。然而,这种特定的数据设计方法侧重于微调,以增强语言模型的功能和行为,而不是添加用于检索的知识。
我很确定,一定会有更多设计训练数据以更新模型行为的创造性方法的例子。
这篇关于数据设计:通过微调来优化SLM(小模型)的性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





