本文主要是介绍AI大模型日报#0419:全球最强开源大模型 Llama 3 发布:15T 数据预训练,参数将超 4000 亿,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导读: 欢迎阅读《AI大模型日报》,内容基于Python爬虫和LLM自动生成。目前采用“文心一言”生成了每条资讯的摘要。
标题: 刚刚,全球最强开源大模型 Llama 3 发布:使用 15T 数据预训练,最大模型参数将超 4000 亿

摘要: Meta发布了其最新一代开源大型语言模型Llama 3,该模型在24K GPU集群上训练,使用15T数据,并提供8B和70B的预训练和指令微调版本。Llama 3在广泛的行业基准测试中表现优异,具有改进的推理能力等新功能。Meta表示,得益于预训练和后训练的改进,Llama 3在8B和70B参数尺度下是最好的模型,后期训练程序的改进降低了错误拒绝率,提高了对齐度和响应多样性。与先进模型相比,Llama 3在多项标准测试基准上表现更好,同时在真实世界场景中也表现出色。Llama 3成为最强开源LLM的关键要素包括模型架构、预训练数据、扩大预训练规模和指令微调。其中,Llama 3采用了纯解码器transformer架构,并使用了一个128K token的tokenizer来提高编码效率和模型性能。此外,Meta还采用了分组查询等技术来提高推理效率。这些改进使得Llama 3在性能上有了显著提升,成为目前最具竞争力的开源大型语言模型之一。
网址: 刚刚,全球最强开源大模型 Llama 3 发布:使用 15T 数据预训练,最大模型参数将超 4000 亿|用例|meta|视频生成模型_网易订阅
标题: 深度|AIGC 视频应用的突破口在 3D?文生视频发展技术路径辨析
摘要: OpenAI推出的Sora在科技圈引起激烈讨论,图灵奖得主杨立昆质疑其缺乏对物理世界的理解。同时,360董事长和猎豹CEO也有不同看法。国内推出了文生视频产品如魔珐科技的有言AIGC,引发关注。文生视频将成为2024年科技圈焦点,类似ChatGPT在2023年的热潮。AI视频生成正在飞速发展,但仍有待突破的卡点。
网址: 深度|AIGC 视频应用的突破口在 3D?文生视频发展技术路径辨析|aigc|分布式数据库|文生|视频发展|视频应用_手机网易网
标题: AI月活企业已超170万家!钉钉正式上线AI助理市场
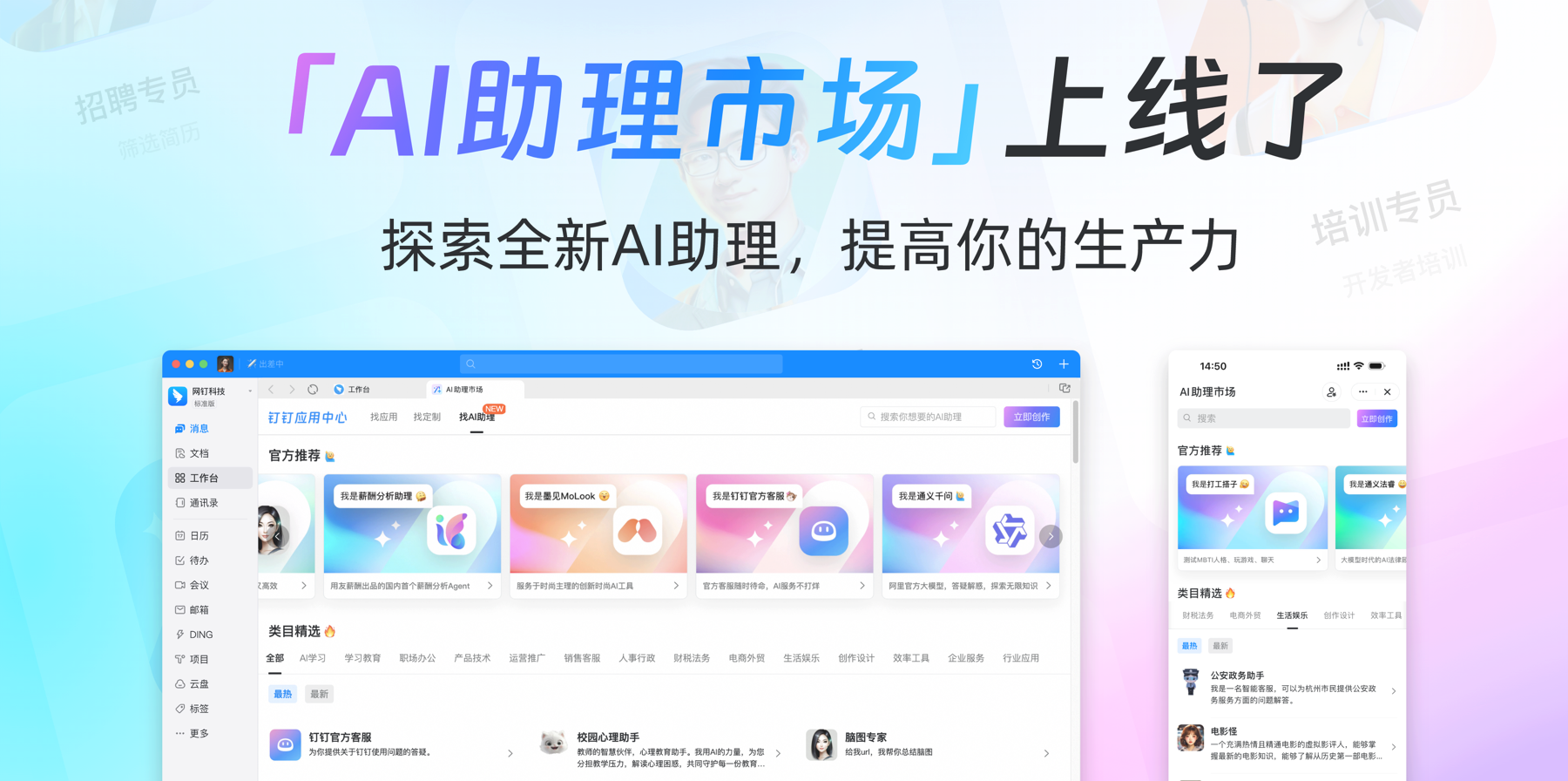
摘要: 钉钉上线AI助理市场,首批推出200+AI助理,覆盖多个类目,已有多个SaaS企业加入。用户可搜索启用。钉钉AI产品已深入各行业,超220万家企业使用。AI助理市场连接钉钉生态,让每个人、每家企业都能创造AI助理。首批AI助理分四类,包括角色AI助理等,可与大模型对话,实时搜索、问答。
网址: AI月活企业已超170万家!钉钉正式上线AI助理市场 | 机器之心
标题: 预测蛋白质共调控和功能,哈佛&MIT训练含19层transformer的基因组语言模型

摘要: 研究人员利用机器学习训练基因组语言模型(gLM),分析基因间的功能和调控关系,学习基因组上下文和蛋白质序列,并编码生物相关信息。该方法有助于理解生物系统,弥补了先前模型忽略蛋白质在基因组中相互关系和背景的不足。研究还涉及进化过程对蛋白质序列、结构和功能之间复杂联系的影响,对解释基因组数据至关重要。该研究已发表在《Nature Communications》。
网址: 预测蛋白质共调控和功能,哈佛&MIT训练含19层transformer的基因组语言模型 | 机器之心
这篇关于AI大模型日报#0419:全球最强开源大模型 Llama 3 发布:15T 数据预训练,参数将超 4000 亿的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





