本文主要是介绍Langchain-Chatchat 从入门到精通(基于本地知识库的问答系统)(更新中),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 一、Langchain-Chatchat介绍
- 1-1、Langchain-Chatchat介绍
- 1-2、LangChain+ChatGLM 工作流
- 1-3、文档角度的工作流
- 二、快速上手
- 2-0、硬件要求
- 2-1、环境配置
- 2-2、模型下载
- 2-3、初始化知识库和配置文件
- 2-4、一键启动
- 三、配置文件详解(config目录下)
- 3-1、basic_config
- 3-2、kb_config
- 3-3、model_config
- 3-4、prompt_config
- 3-5、server_config
- 四、其他问题
- 4-1、如何开启量化模式?
- 4-2、加载其他模型?
- 4-3、加载BaiChuan模型报错AttributeError: 'BaichuanTokenizer' object has no attribute 'sp_model'
- 4-4、加载通义千问模型报错KeyError: 'qwen2'
- 总结
前言
一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。(本文侧重于整个项目的理解和内容调节,如部署遇到问题请看结尾的其他参考文章)
一、Langchain-Chatchat介绍
1-1、Langchain-Chatchat介绍

Langchain-Chatchat 项目地址: https://github.com/chatchat-space/Langchain-Chatchat
一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
1-2、LangChain+ChatGLM 工作流
项目实现原理如下:
- 加载文件
- 读取文本
- 文本分割
- 文本向量化
- 问句向量化
- 在文本向量中匹配出与问句向量最相似的top k个
- 匹配出的文本作为上下文和问题一起添加到Prompt中去
- 提交给LLM生成回答
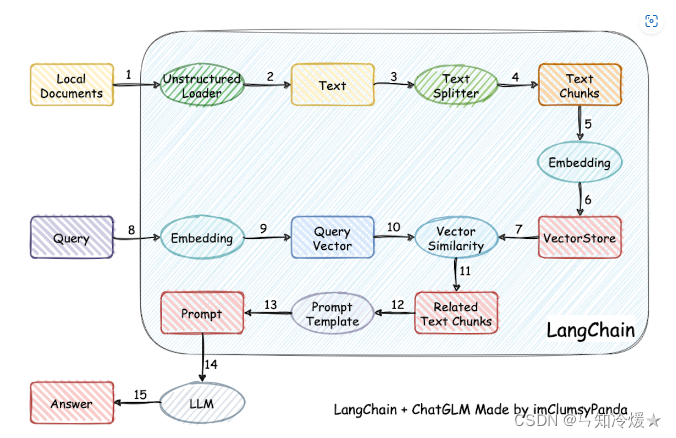
1-3、文档角度的工作流
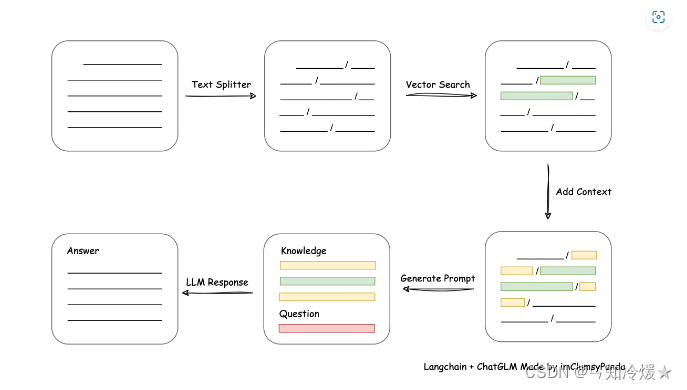
二、快速上手
Notice: 强烈建议直接使用镜像!!!个人去搭建环境真的会遇到亿点点问题😍
2-0、硬件要求
如果想要顺利在GPU运行本地模型的 FP16 版本,你至少需要以下的硬件配置,来保证在我们框架下能够实现 稳定连续对话
ChatGLM3-6B & LLaMA-7B-Chat 等 7B模型
- 最低显存要求: 14GB
- 推荐显卡: RTX 4080
Qwen-14B-Chat 等 14B模型
- 最低显存要求: 30GB
- 推荐显卡: V100
Yi-34B-Chat 等 34B模型
- 最低显存要求: 69GB
- 推荐显卡: A100
Qwen-72B-Chat 等 72B模型
- 最低显存要求: 145GB
- 推荐显卡:多卡 A100 以上
注意: 以上显存占用仅供参考,实际占用请以nvidia-smi为准
2-1、环境配置
# 拉取仓库
$ git clone https://github.com/chatchat-space/Langchain-Chatchat.git# 进入目录
$ cd Langchain-Chatchat# 安装全部依赖
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
2-2、模型下载
下载模型要先安装lfs:https://docs.github.com/zh/repositories/working-with-files/managing-large-files/installing-git-large-file-storage
备注: 下载模型可能会因为网络问题无法下载,可以考虑不翻墙的方法,在魔搭社区下载!https://modelscope.cn/models
$ git lfs install
$ git clone https://huggingface.co/THUDM/chatglm3-6b
$ git clone https://huggingface.co/BAAI/bge-large-zh
2-3、初始化知识库和配置文件
$ python copy_config_example.py
$ python init_database.py --recreate-vs
更新知识库表:
python init_database.py --create-tables
2-4、一键启动
$ python startup.py -a
启动后的界面如下:
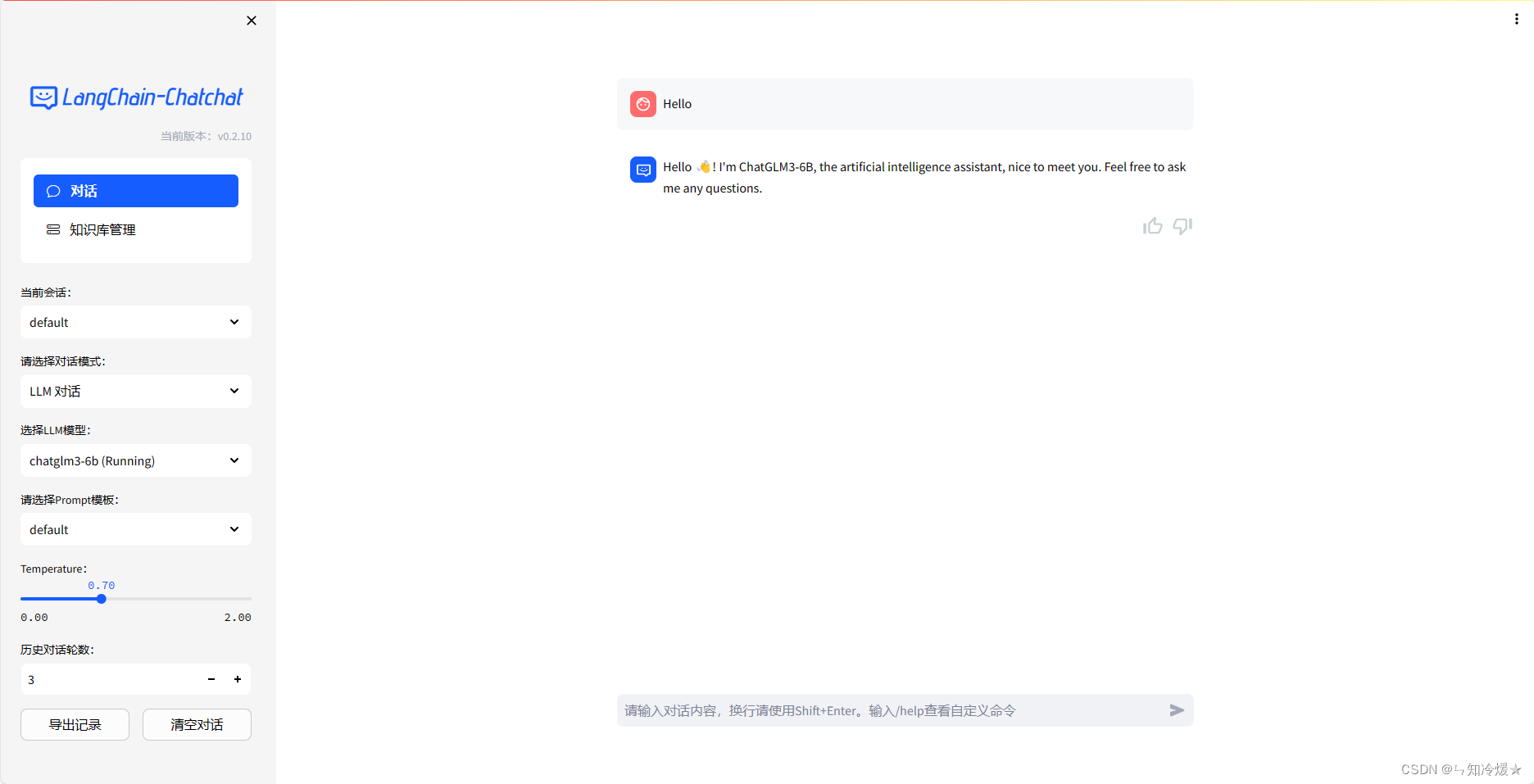
其他:
# api服务启动,访问0.0.0.0:7861/docs
python server/api.py# Web UI服务启动,访问http://localhost:8501/
streamlit run webui.py
三、配置文件详解(config目录下)
3-1、basic_config
basic_config介绍: 基础配置文件,记录日志格式、日志存储路径以及临时文件目录。一般无需修改。
代码界面截图如下所示
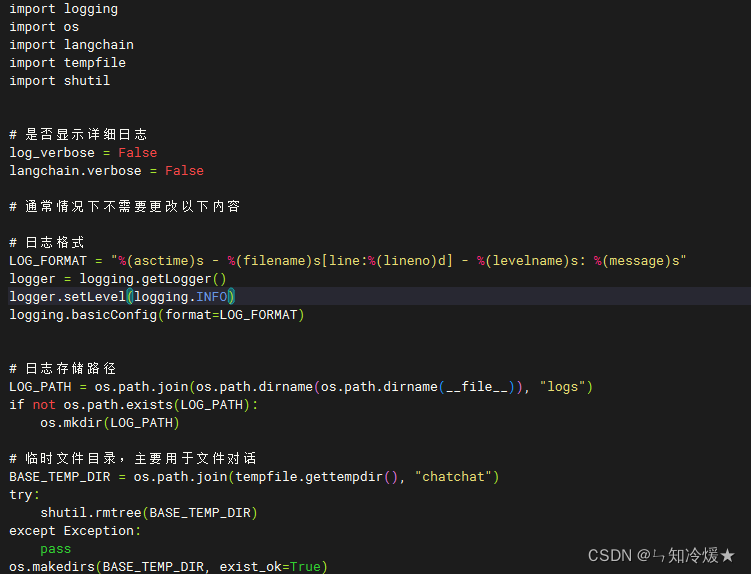
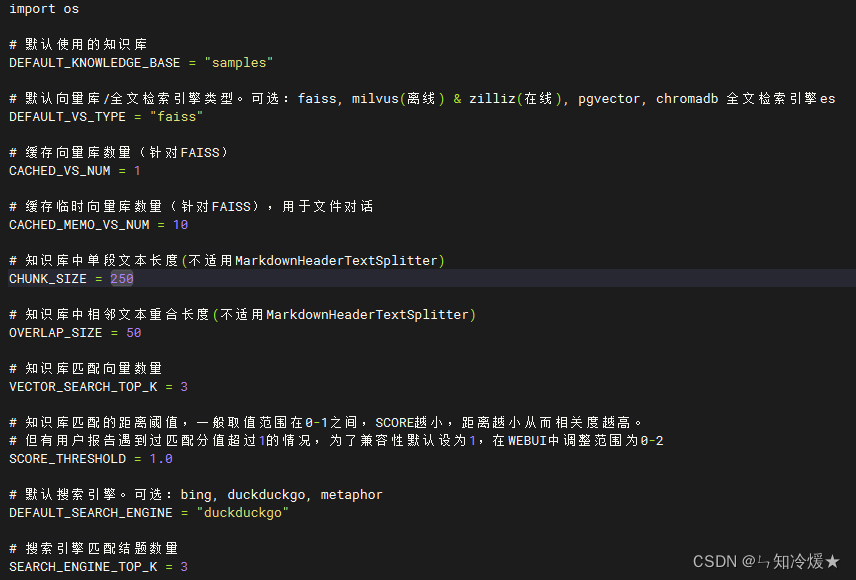
3-2、kb_config
kb_config介绍: 向量数据库配置、分词器配置、知识库配置等。
代码界面截图如下所示:
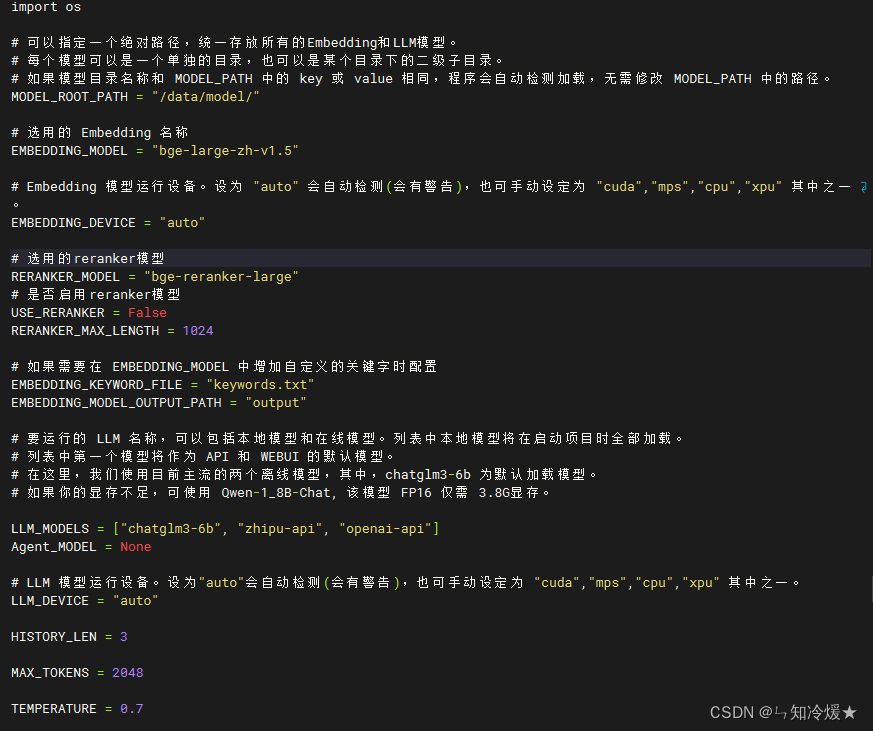
3-3、model_config
model_config介绍: 模型配置项,包括选用的Embedding、要运行的LLM、在线LLM的api、key的配置。
代码界面截图如下所示:
支持的联网模型:
- 智谱AI
- 阿里云通义千问
- 百川
- ChatGPT
- Gimini
- Azure OpenAI
- MiniMax
- 讯飞星火
- 百度千帆
- 字节火山方舟
目前支持的本地向量数据库列表如下:
- FAISS
- Milvus
- PGVector
- Chroma
默认配置如下:
- LLM: Chatglm3-6b
- Embedding Models: m3e-base
- TextSplitter: ChineseRecursiveTextSplitter
- Kb_dataset: faiss
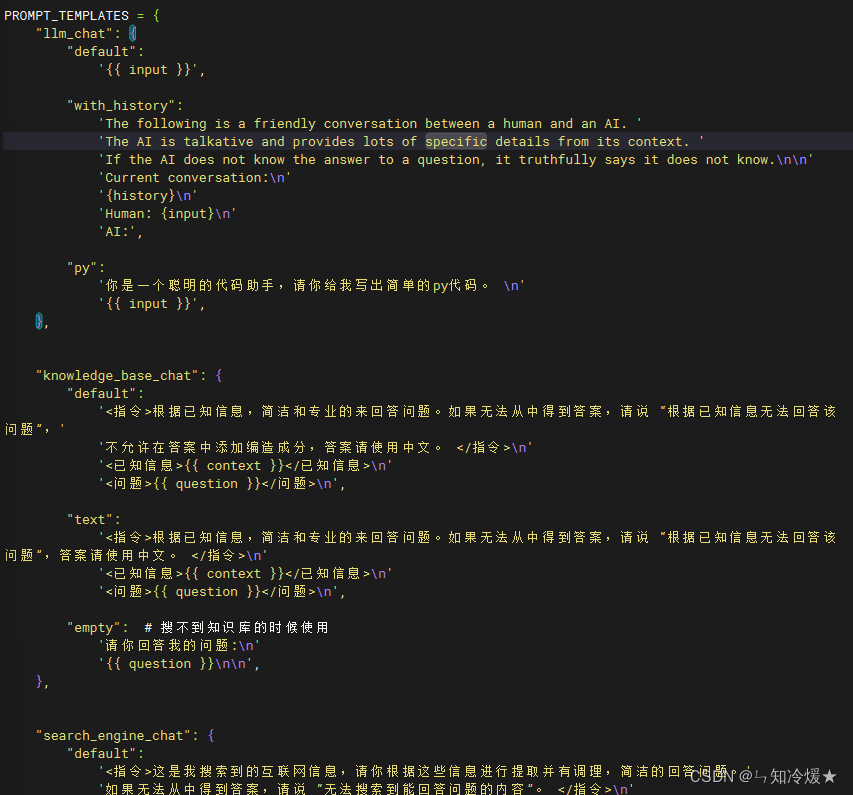
3-4、prompt_config
prompt_config介绍: 提示词配置,包括基础的大模型对话提示词、知识库的对话提示词、搜索引擎的对话提示词、与Agent对话的提示词。
- llm_chat: 最基本的对话提示词。
- knowledge_base_chat: 与知识库对话的提示词。
- agent_chat: 与Agent对话的提示词。
Notice: prompt模板使用Jinja2语法,简单点就是用双大括号代替f-string的单大括号 请注意,本配置文件支持热加载,修改prompt模板后无需重启服务。
代码界面截图如下所示:
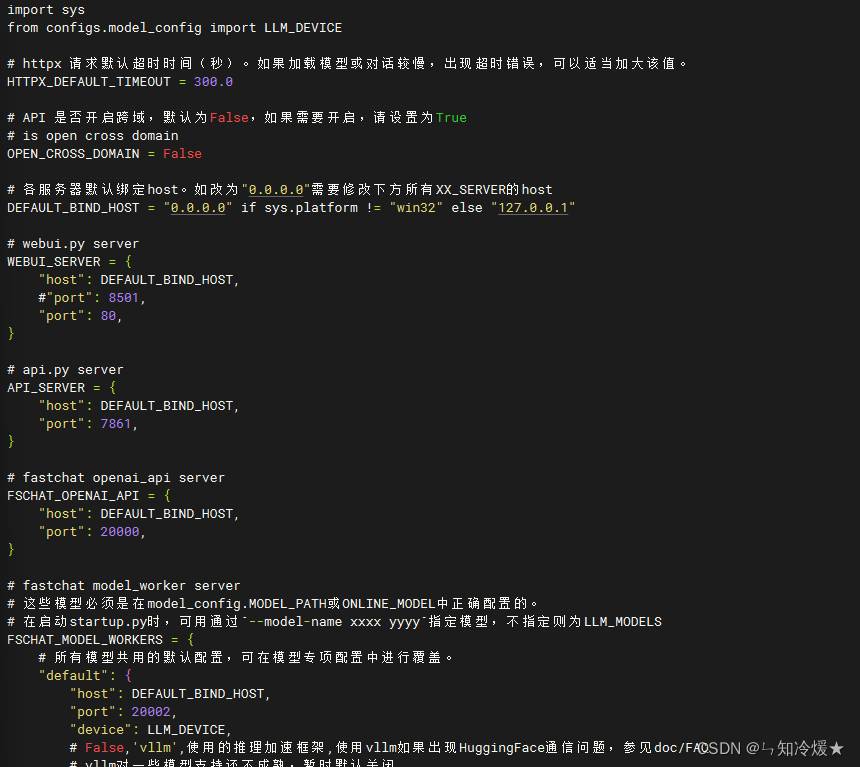
3-5、server_config
server_config介绍: 服务器和端口的配置项,如果需要修改端口号的话可以在这里进行修改。
Notice: 在启动startup.py时,可用通过–model-worker --model-name xxxx指定模型,不指定则为LLM_MODEL
代码界面截图如下所示:
四、其他问题
4-1、如何开启量化模式?
在配置文件server_config文件里有Load_8bit参数,改为True即可:
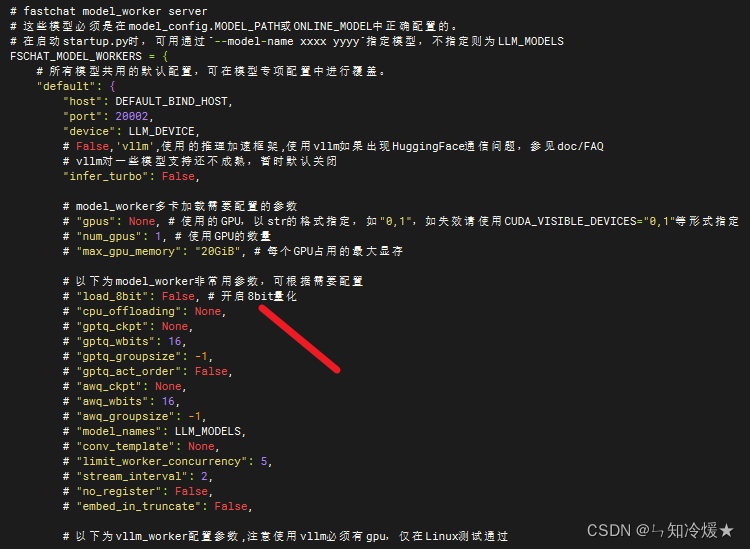
4-2、加载其他模型?
- 在model_config文件夹里我们可以看到该框架支持的模型:
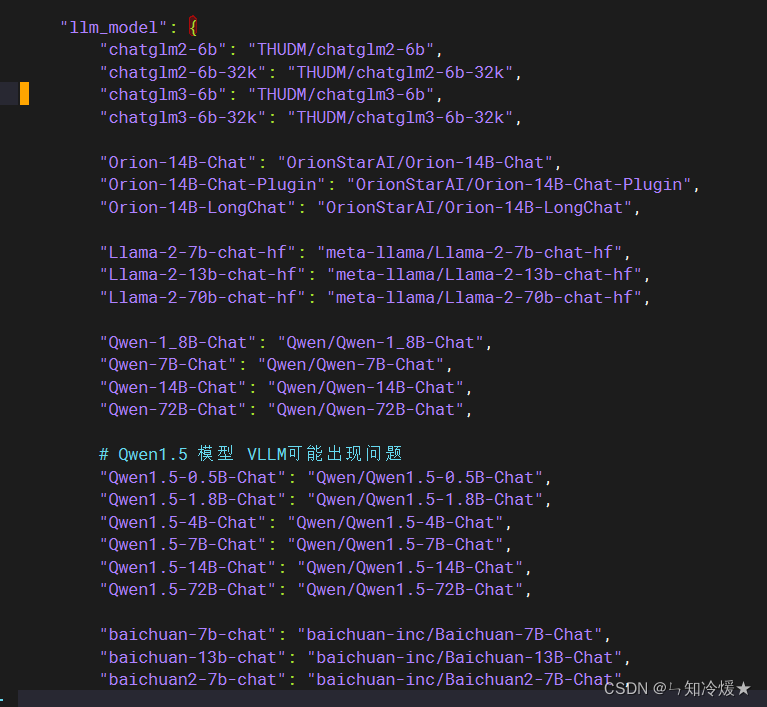
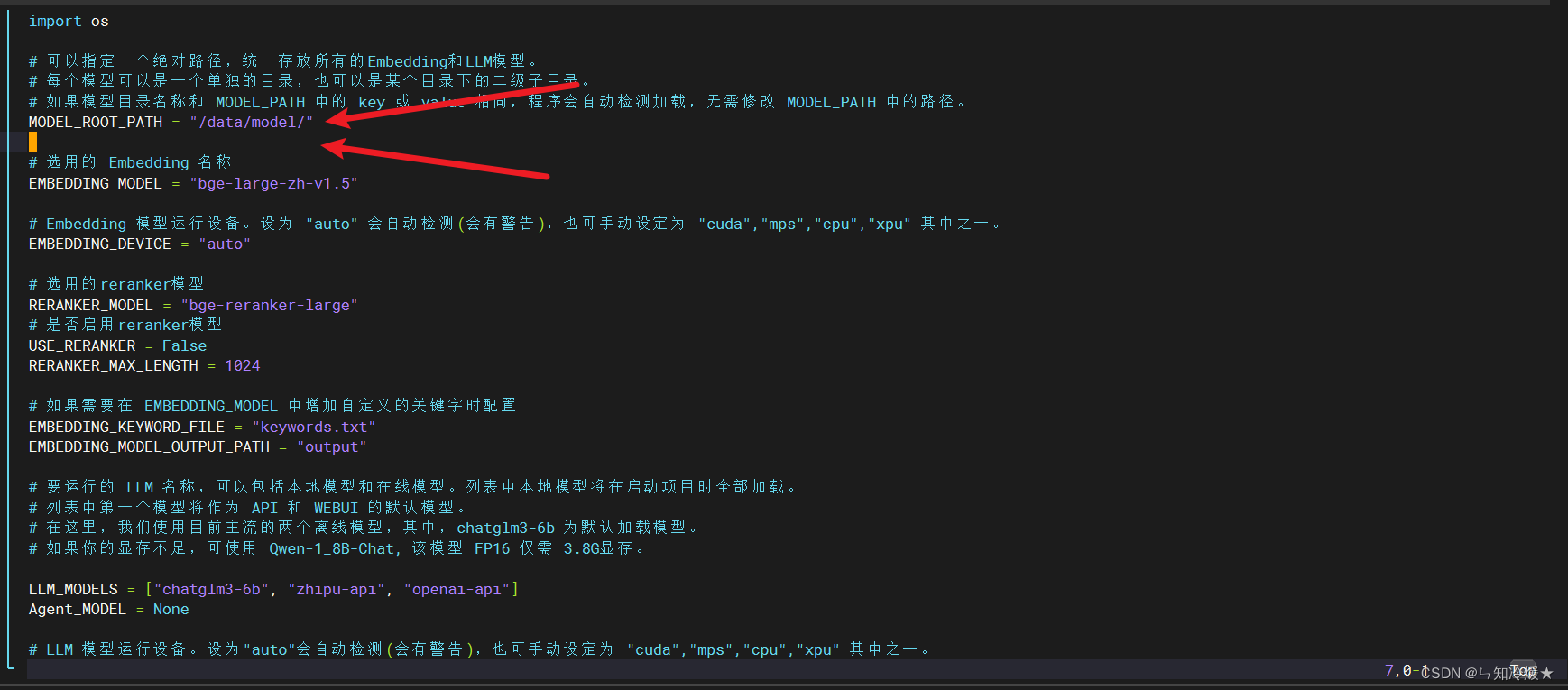
- 首先我们需要在model_config里修改模型以及Embedding的根目录,将下载好的模型放于该根目录下,并且模型文件夹名称要与上边的模型名称一致。例如:mv Qwen1___5-14B/ Qwen1.5-14B-Chat
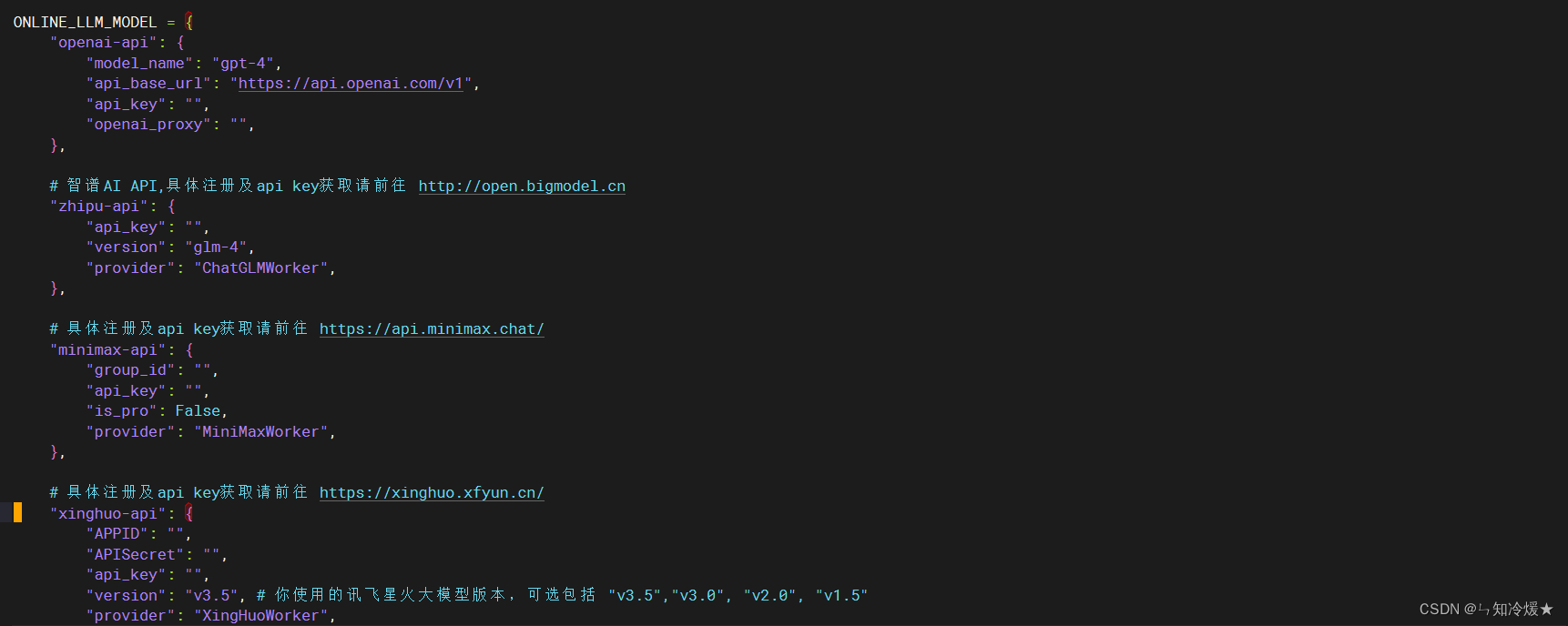
- 若需要使用在线模型,只需把申请好的API_KEY等填入即可。
- 模型下载请去结尾参考文章魔搭社区官网下载。
4-3、加载BaiChuan模型报错AttributeError: ‘BaichuanTokenizer’ object has no attribute ‘sp_model’
解决方法: 由于版本冲突导致,需要更改以下包的版本
pip install transformers==4.33.3
pip install torch==2.0.1
pip install triton==2.0.0
4-4、加载通义千问模型报错KeyError: ‘qwen2’
解决方法: 由于版本冲突导致,需要更改以下包的版本
# 大于这个版本也是ok的
pip install --upgrade transformers==4.37.2
(腹语): 这个transformers版本是没法加载BaiChuan的,所以你只能二选一!
参考文章:
Langchain官方GitHub
Langchain-Chatchat 官方Github
Langchain-Chatchat 官方Github----疑难问题解答
魔搭社区官网
【大模型实践】使用 Langchain-Chatchat 进行本地部署的完整指南).
Langchain-Chatchat + 阿里通义千问Qwen 保姆级教程 | 次世代知识管理解决方案
Langchain-Chatchat大语言模型本地知识库的踩坑、部署、使用
【大模型实践】使用 Langchain-Chatchat 进行本地部署的完整指南
LLMs之RAG:LangChain-Chatchat(一款中文友好的全流程本地知识库问答应用)的简介(支持 FastChat 接入的ChatGLM-2/LLaMA-2等多款主流LLMs+多款embe
Langchain-Chatchat开源库使用的随笔记(一)
总结
确认过眼神,我遇上对的人💕💕💕
这篇关于Langchain-Chatchat 从入门到精通(基于本地知识库的问答系统)(更新中)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






