本文主要是介绍第100+5步 ChatGPT文献复现:ARIMAX预测肺结核 vol. 5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于WIN10的64位系统演示
一、写在前面
我们继续往下看,首先例行回顾文章:
《PLoS One》杂志的2023年一篇题目为《A comparative study of three models to analyze the impact of air pollutants on the number of pulmonary tuberculosis cases in Urumqi, Xinjiang》文章的公开数据做案例。
这文章做的是用:空气污染物对新疆乌鲁木齐肺结核病例数影响的比较研究。

这一步我们继续弄ARIMAX模型,首先回顾上一步我的总结:
以肺结核和SO2构建ARIMAX模型为例,首先,单独使用肺结核的时序数据构建最优的ARIMA模型(叫做ARIMA-MTB),拿到该模型的残差白噪声序列,叫做S1;其次,单独使用SO2的时序数据构建最优的ARIMA模型(叫做ARIMA-SO2),拿到该模型的残差白噪声序列,叫做S2;接着,利用S1和S2序列绘制交叉相关函数(CCF)图,找到S2序列滞后多少个月(本例是1个月)与S1序列呈现相关关系;最后,把滞后1个月的S2序列纳入ARIMA-MTB模型,就是最终的ARIMAX模型了,这里的X,就是滞后1个月的S2序列。注意哦,纳入的是SO2的白噪声残差序列,而不是原始序列!!!
这一步,我们使用SPSS把ARIMAX模型构建完毕。
二、学习和复现:结果三
咱们一步一步来吧:
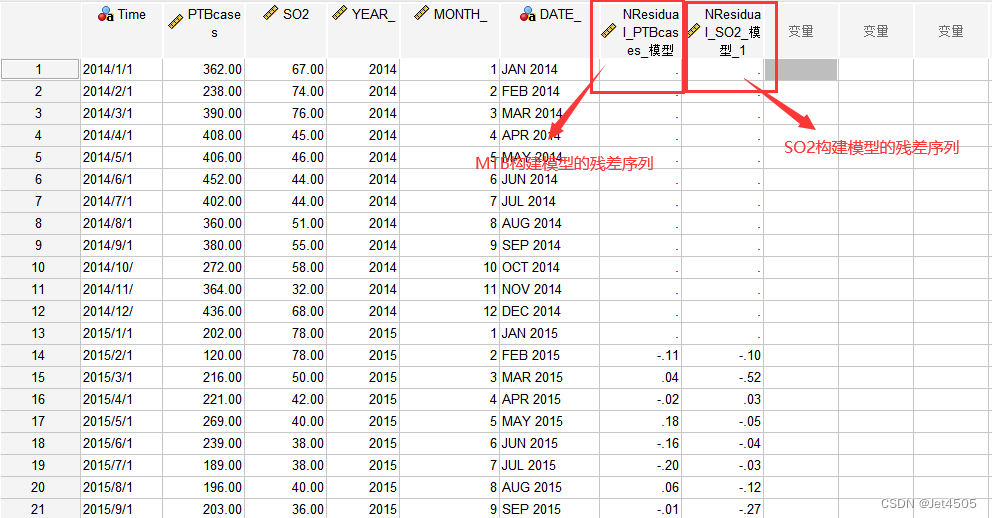
(1)上一步,我们拿到了ARIMA-MTB和ARIMA-SO2的残差白噪声虚列,两个都是ARIMA(0,1,1)(0,1,0):
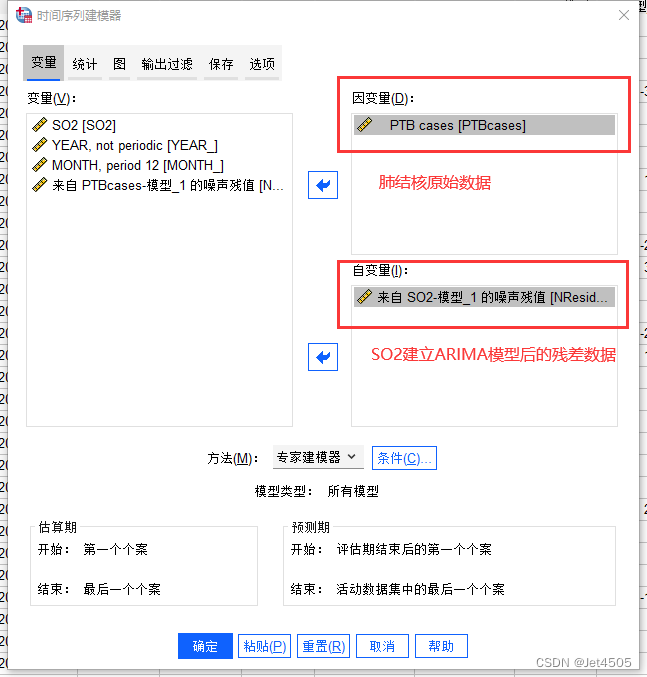
(2)进入ARIMAX模型建立界面,跟单纯的ARIMA不同的是,需要把SO2的残差序列作为自变量加入:
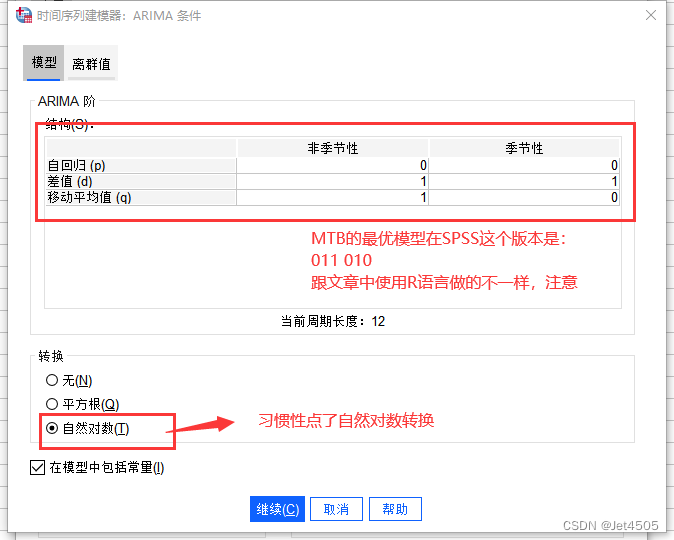
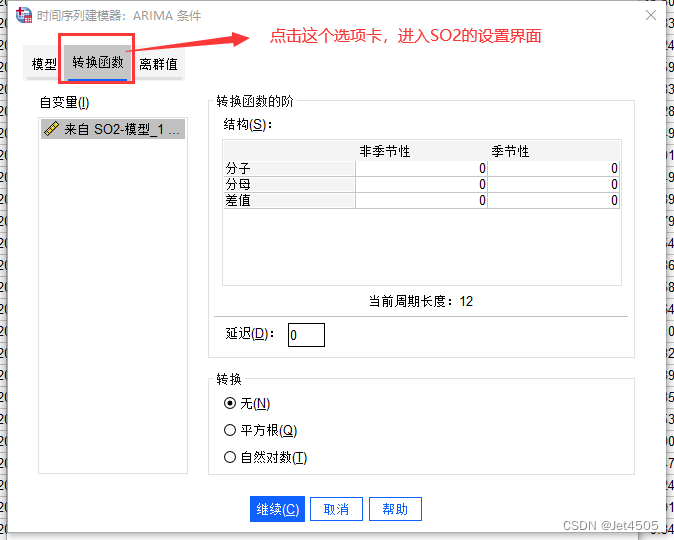
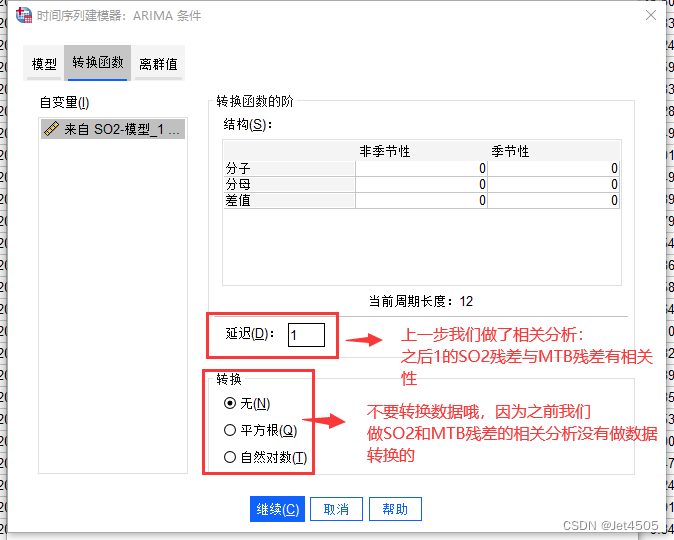
这里的延迟就填1,为啥?就是之前做的相关分析,滞后一个月有显著性差异。
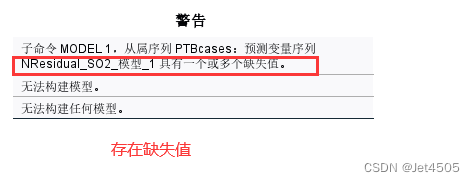
然后翻车了,因为存在缺失值哈,先试试无脑填充0吧:
看看结果如何:
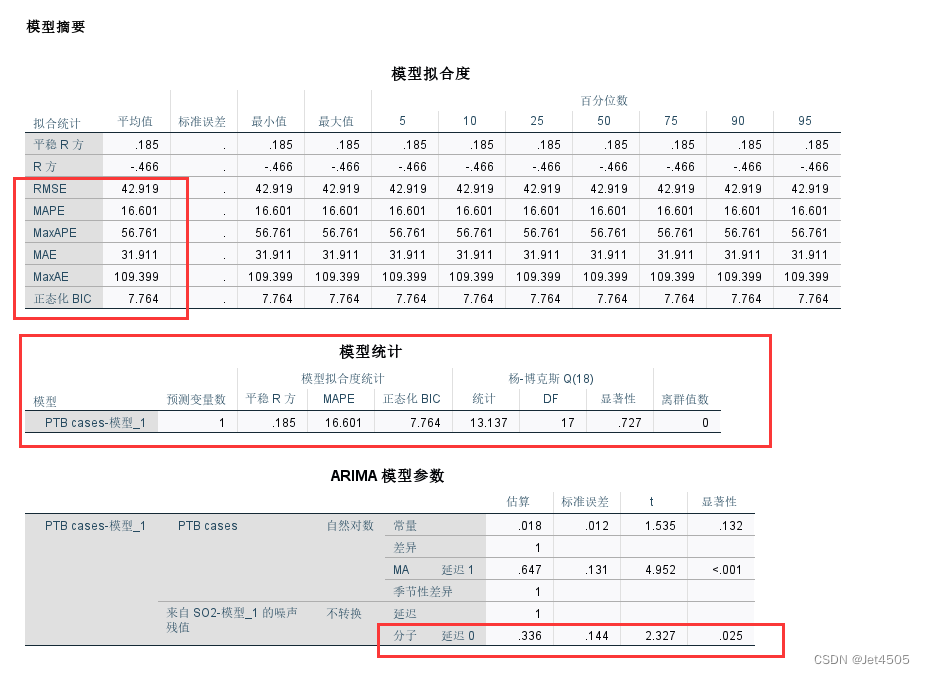
跟单纯的ARIMA模型做对比:

有点诡异的是:除了BIC值,ARIMAX模型在平稳R方、MAE、MAPE、RMSE等性能参数均稍微优于单纯的ARIMA模型。
(3)试一试SO2残差序列的中位数或者平均值填充,再进行ARIMAX建模:
① 平均值填充,填充-0.0097:
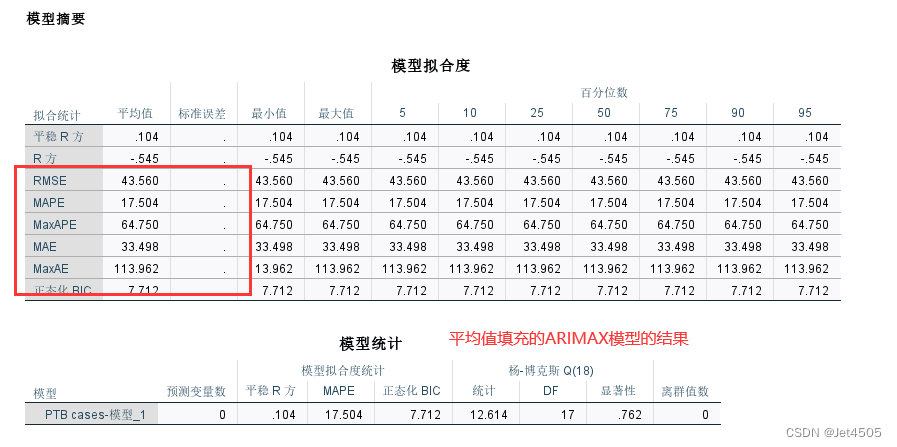
结果大同小异吧,毕竟平均值跟0基本没啥差别。
② 中位数填充,填充-0.0247:
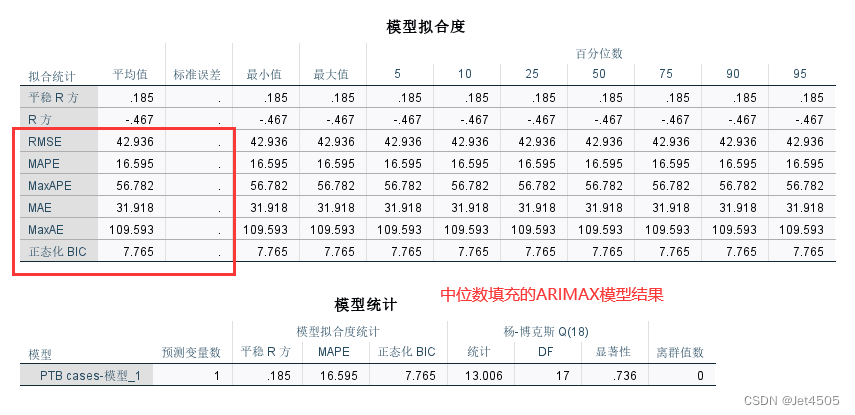
也是大同小异。
(4)最后看看文章对于结果的描述:

翻译翻译:
在接下来的部分中,这五种相对空气污染物SO2、PM10、PM2.5、NO2和CO被纳入到多变量ARIMA模型中,以建立相应的ARIMAX模型。七个ARIMAX模型中只有三个通过了残差和参数测试,它们的AIC和MAPE值分别被计算出来(见表6)。如表6所示,包含空气污染物的ARIMAX模型的AIC和MAPE值低于ARIMA模型。特别是,ARIMAX(1,1,2)×(0,1,1)12+PM2.5,带有12个月的滞后,具有最小的AIC值(AIC = 479.32)和MAPE值(MAPE = 6.766%),这是最优的ARIMAX模型。
就有一句话解读:
“七个ARIMAX模型中只有三个通过了残差和参数测试,”:也就是SO2等空气污染的残差序列作为自变量纳入ARIMAX模型,也还需要通过参数检验的,P值小于0.05。我们的例子中,SO2的残差序列的P值等于0.025:
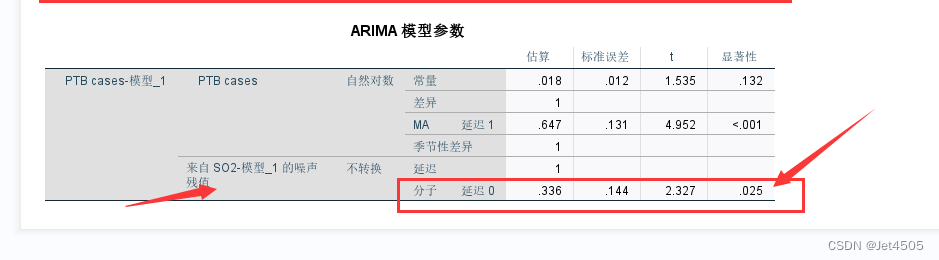
三、一点补充
可以看到,用SPSS做的ARIMAX模型在性能提升方面,没有文章中使用R语言做的那么明显。SPSS做的ARIMAX模型的MAPE大约在16.60%左右,而文献中可达到12.728%,可谓遥遥领先。两个软件建模算法的区别我也是不太了解,有可能是参数设定方面的差别,也不得而知。不过,SPSS操作简单,我觉得也是可以用的,把建模过程描述清晰就行。
有没有想过,使用传统的ARIMAX模型构建方法,效果如何?
我试了一下,由于数据不够多,做相关分析,之后36个月都没啥差异的,哈哈。
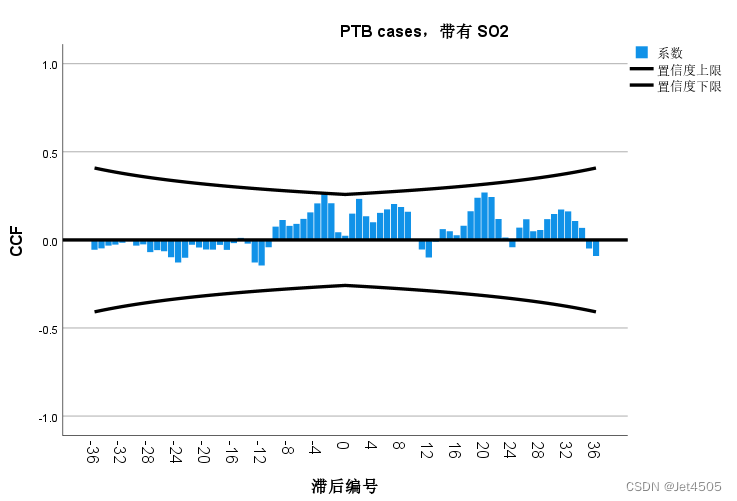
好了,这篇文章的ARIMAX模型构建部分,就解读完了。下一步,我们换另一篇文章来解读解读。
四、数据
链接:https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0277314
这篇关于第100+5步 ChatGPT文献复现:ARIMAX预测肺结核 vol. 5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







