本文主要是介绍1320亿参数,性能超LLaMA2、Grok-1!开源大模型DBRX,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3月28日,著名数据和AI平台Databricks在官网正式开源大模型——DBRX。
DBRX是一个专家混合模型(MoE)有1320亿参数,能生成文本/代码、数学推理等,有基础和微调两种模型。
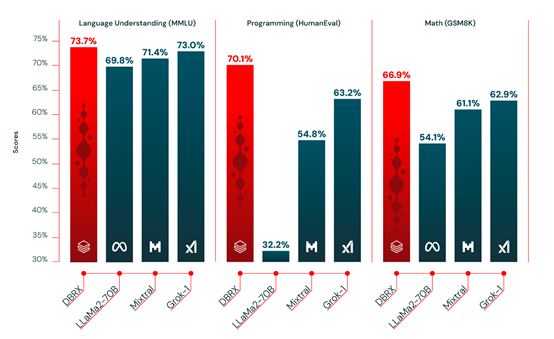
根据DBRX在MMLU、HumanEval和 GSM8K公布的测试数据显示,不仅性能超过了LLaMA2-70B和马斯克最近开源的Grok-1,推理效率比LLaMA2-70B快2倍,总参数却只有Grok-1的三分之一,是一款功能强算力消耗低的大模型。
基础模型:https://huggingface.co/databricks/dbrx-base
微调模型:https://huggingface.co/databricks/dbrx-instruct
Github:https://github.com/databricks/dbrx
在线demo:https://huggingface.co/spaces/databricks/dbrx-instruct
Databricks作为数据管理领域的超级独角兽,为了抓住生成式AI的风口,2023年6月26日曾以13亿美元的天价,收购了大模型开源平台MosaicML。
MosaicML曾在2023年5月5日发布了类ChatGPT开源大语言模型MPT-7B。(开源地址:https://huggingface.co/mosaicml/mpt-7b)该项目具备可商业化、高性能、算力消耗低、1T训练数据等技术优势。
MPT-7B只进行了大约10天的训练,零人工干预,训练成本仅用了20万美元。性能却打败了LLaMA-7B、StablelM-7B 、Cerebras-13B等当时知名开源模型。

截至目前,MPT-7B的下载量已超过300万次,而Databricks此次发布的DBRX在MPT-7B基础之上进行了大幅度优化并且将算力需求降低了4倍。
DBRX简单介绍
DBRX是一款基于Transformer的MoE架构大模型,1320亿参数中的360亿参数处于长期激活状态。
这与其它开源的MoE类型模型如Mixtral、Grok-1相比,DBRX使用了数量更多的小专家模型。DBRX有16个专家并选择4个,而Mixtral和Grok-1有8个专家并选择了2个。
DBRX使用了12T的文本和代码数据(支持中文),支持 32k上下文窗口,并在3072 个 英伟达的 H100 上进行了3个月的预训练。
DBRX除了与开源模型进行了对比之外,还与OpenAI的GPT系列、谷歌的Gemini以及Anthropic最新发布的Claude 3系列进行了同台竞技。
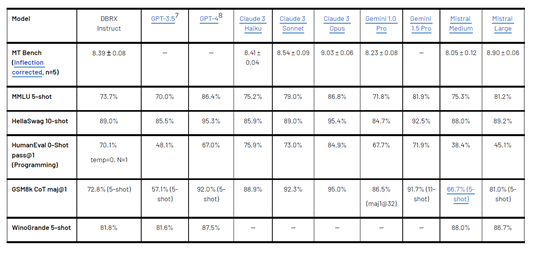
MMLU、HellaSwag、WinoGrande、HumanEval等综合测试结果显示,DBRX推理、数学解答、语言理解、代码等能力超过了GPT-3.5,性能与谷歌的Gemini 1.0 Pro 性能差不多。
什么是专家混合模型
MoE模型全称为Mixture of Experts,其核心原理是将一个庞大的神经网络分解为多个相对独立的小型子网络(即专家),每个专家负责处理输入数据的某些方面。
这种架构设计使得MoE模型能够高效利用计算资源,避免对所有参数进行无谓的计算。主要包括门控制机制、专家网络和聚合器三大模块
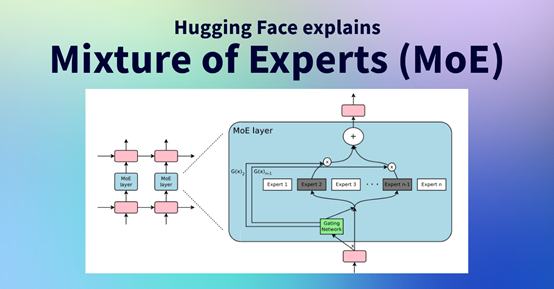
门控机制:这是MoE模型的核心模块,负责决定每个输入应该由哪个或哪几个专家处理。
门控机制会根据输入数据的特征分配权重给不同的专家,这个过程是动态的,意味着不同的输入会根据其内容被分配给最合适的专家处理。例如,Grok-1模型中只有大约25%的参数被实际使用或“激活”。
专家网络:这些是模型中的子网络,每个都有自己特定的参数配置。在传统的MoE模型中,这些专家网络可以是结构相同但参数不同的多个神经网络。每个网络都专注于模型任务的一个方面或输入数据的一个子集。
聚合器:一旦各个专家给出了自己对于输入的处理结果,聚合器则负责将这些结果综合起来,形成最终的输出。聚合的方式可以是简单的加权和、投票机制或者更复杂的融合策略。
MoE是开发、训练超过千亿参数大模型常用的架构,例如,GPT-4、Palm 2等著名大模型使用的都是该架构。
关于Databricks
Databricks创立于2013年,总部位于美国旧金山,在全球多个国家、地区设有办事处。其企业客户超过10000家,包括众多财富500强企业。
Databricks主要提数据智能分析服务,帮助企业、个人用户快速挖掘数据的商业价值。
本文素材来源Databricks官网,如有侵权请联系删除
END


这篇关于1320亿参数,性能超LLaMA2、Grok-1!开源大模型DBRX的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





