本文主要是介绍【大数据】Flink SQL 语法篇(三):窗口聚合(TUMBLE、HOP、SESSION、CUMULATE),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flink SQL 语法篇(三):窗口聚合
- 1.滚动窗口(TUMBLE)
- 1.1 Group Window Aggregation 方案(支持 Batch / Streaming 任务)
- 1.2 Windowing TVF 方案(1.13 只支持 Streaming 任务)
- 2.滑动窗口(HOP)
- 2.1 Group Window Aggregation 方案(支持 Batch / Streaming 任务)
- 2.2 Windowing TVF 方案(1.13 只支持 Streaming 任务)
- 3.会话窗口(SESSION)
- 3.1 Group Window Aggregation 方案(支持 Batch / Streaming 任务)
- 4.渐进式窗口(CUMULATE)
- 4.1 Windowing TVF 方案(1.13 只支持 Streaming 任务)
- 5.Window TVF 支持 Grouping Sets、Rollup、Cube

1.滚动窗口(TUMBLE)
滚动窗口 将每个元素指定给 指定窗口大小 的窗口。滚动窗口具有固定大小,且不重叠。例如,指定一个大小为 5 分钟的滚动窗口。在这种情况下,Flink 将每隔 5 分钟开启一个新的窗口,其中每一条数都会划分到唯一的一个 5 分钟的窗口中,如下图所示。

- ⭐ 应用场景:常见的按照一分钟对数据进行聚合。例如,计算一分钟内 PV,UV 数据。
- ⭐ 实际案例:简单且常见的分维度分钟级别同时在线用户数、总销售额。
那么上面这个案例的 SQL 要咋写呢?
关于滚动窗口,在 1.13 版本之前和 1.13 及之后版本有两种 Flink SQL 实现方式,分别是:
Group Window Aggregation(1.13之前只有此类方案,此方案在1.13及之后版本已经标记为废弃,不推荐小伙伴萌使用)。Windowing TVF(1.13及之后建议使用 Windowing TVF)。
1.1 Group Window Aggregation 方案(支持 Batch / Streaming 任务)
-- 数据源表
CREATE TABLE source_table (-- 维度数据dim STRING,-- 用户 iduser_id BIGINT,-- 价格price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,pv BIGINT,sum_price BIGINT,max_price BIGINT,min_price BIGINT,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
select dim,count(*) as pv,sum(price) as sum_price,max(price) as max_price,min(price) as min_price,-- 计算 uv 数count(distinct user_id) as uv,UNIX_TIMESTAMP(CAST(tumble_start(row_time, interval '1' minute) AS STRING)) * 1000 as window_start
from source_table
group bydim,tumble(row_time, interval '1' minute);
可以看到 Group Window Aggregation 滚动窗口的 SQL 语法就是把 Tumble Window 的声明写在了 group by 子句中,即 tumble(row_time, interval '1' minute),第一个参数为 事件时间的时间戳;第二个参数为 滚动窗口大小。
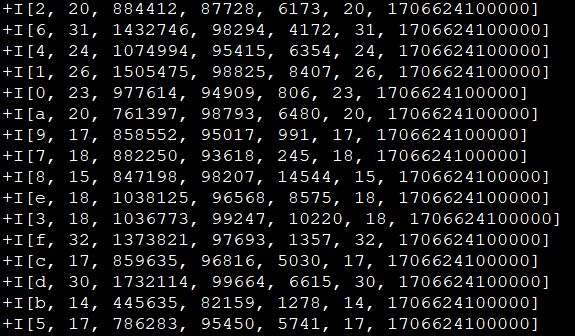
1.2 Windowing TVF 方案(1.13 只支持 Streaming 任务)
-- 数据源表
CREATE TABLE source_table (-- 维度数据dim STRING,-- 用户 iduser_id BIGINT,-- 价格price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,pv BIGINT,sum_price BIGINT,max_price BIGINT,min_price BIGINT,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECT dim,UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start,count(*) as pv,sum(price) as sum_price,max(price) as max_price,min(price) as min_price,count(distinct user_id) as uv
FROM TABLE(TUMBLE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND))
GROUP BY window_start, window_end,dim
可以看到 Windowing TVF 滚动窗口的写法就是把 Tumble Window 的声明写在了数据源的 Table 子句中,即 TABLE(TUMBLE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND)),包含三部分参数:
- 第一个参数
TABLE source_table声明数据源表。 - 第二个参数
DESCRIPTOR(row_time)声明数据源的时间戳。 - 第三个参数
INTERVAL '60' SECOND声明滚动窗口大小为 1 min。
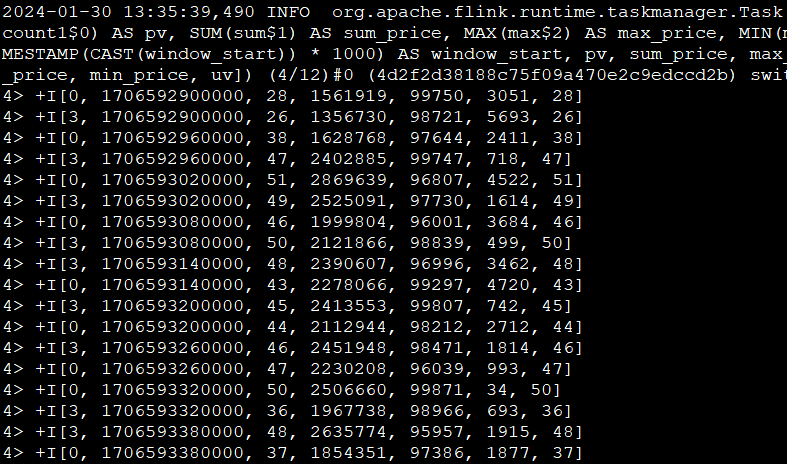
由于离线没有相同的时间窗口聚合概念,这里就直接说实时场景 SQL 语义,假设 Orders 为 Kafka,target_table 也为 Kafka,这个 SQL 生成的实时任务,在执行时,会生成三个算子:
- 数据源算子(
From Order):连接到 Kafka Topic,数据源算子一直运行,实时的从 Order Kafka 中一条一条的读取数据,然后一条一条发送给下游的 窗口聚合算子。 - 窗口聚合算子(
TUMBLE算子):接收到上游算子发的一条一条的数据,然后将每一条数据按照时间戳划分到对应的窗口中(根据事件时间、处理时间的不同语义进行划分),上述案例为事件时间,事件时间中,滚动窗口算子接收到上游的 Watermark 大于窗口的结束时间时,则说明当前这一分钟的滚动窗口已经结束了,将窗口计算完的结果发往下游算子(一条一条发给下游 数据汇算子)。 - 数据汇算子(
INSERT INTO target_table):接收到上游发的一条一条的数据,写入到target_tableKafka 中。
这个实时任务也是 24 小时一直在运行的,所有的算子在同一时刻都是处于 running 状态的。
注意:事件时间中滚动窗口的窗口计算触发是由 Watermark 推动的。
2.滑动窗口(HOP)
滑动窗口 也是将元素指定给固定长度的窗口。与滚动窗口功能一样,也有窗口大小的概念。不一样的地方在于,滑动窗口有另一个参数控制窗口计算的频率(滑动窗口滑动的步长)。因此,如果滑动的步长小于窗口大小,则滑动窗口之间每个窗口是可以重叠。在这种情况下,一条数据就会分配到多个窗口当中。举例,有 10 分钟大小的窗口,滑动步长为 5 分钟。这样,每 5 分钟会划分一次窗口,这个窗口包含的数据是过去 10 分钟内的数据,如下图所示。

- ⭐ 应用场景:比如计算同时在线的数据,要求结果的输出频率是 1 分钟一次,每次计算的数据是过去 5 分钟的数据(有的场景下用户可能在线,但是可能会 2 分钟不活跃,但是这也要算在同时在线数据中,所以取最近 5 分钟的数据就能计算进去了)。
- ⭐ 实际案例:简单且常见的分维度分钟级别同时在线用户数,1 分钟输出一次,计算最近 5 分钟的数据。
2.1 Group Window Aggregation 方案(支持 Batch / Streaming 任务)
-- 数据源表
CREATE TABLE source_table (-- 维度数据dim STRING,-- 用户 iduser_id BIGINT,-- 价格price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECT dim,UNIX_TIMESTAMP(CAST(hop_start(row_time, interval '1' minute, interval '5' minute) AS STRING)) * 1000 as window_start, count(distinct user_id) as uv
FROM source_table
GROUP BY dim, hop(row_time, interval '1' minute, interval '5' minute);
可以看到 Group Window Aggregation 滚动窗口的写法就是把 Hop Window 的声明写在了 group by 子句中,即 hop(row_time, interval '1' minute, interval '5' minute)。其中:
- 第一个参数为 事件时间的时间戳。
- 第二个参数为 滑动窗口的滑动步长。
- 第三个参数为 滑动窗口大小。
2.2 Windowing TVF 方案(1.13 只支持 Streaming 任务)
-- 数据源表
CREATE TABLE source_table (-- 维度数据dim STRING,-- 用户 iduser_id BIGINT,-- 用户price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,uv BIGINT,window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECT dim,UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start, count(distinct user_id) as bucket_uv
FROM TABLE(HOP(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '1' MINUTES, INTERVAL '5' MINUTES))
GROUP BY window_start, window_end, dim;
可以看到 Windowing TVF 滚动窗口的写法就是把 Hop Window 的声明写在了数据源的 Table 子句中,即 TABLE(HOP(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '1' MINUTES, INTERVAL '5' MINUTES)),包含四部分参数:
- 第一个参数 TABLE
source_table声明数据源表。 - 第二个参数
DESCRIPTOR(row_time)声明数据源的时间戳。 - 第三个参数
INTERVAL '1' MINUTES声明滚动窗口滑动步长大小为 1 min。 - 第四个参数
INTERVAL '5' MINUTES声明滚动窗口大小为 5 min。
3.会话窗口(SESSION)
Session 时间窗口 和滚动、滑动窗口不一样,其没有固定的持续时间,如果在定义的间隔期(Session Gap)内没有新的数据出现,则 Session 就会窗口关闭。

- ⭐ 实际案例:计算每个用户在活跃期间(一个 Session)总共购买的商品数量,如果用户 5 分钟没有活动则视为 Session 断开。
目前 1.13 版本中 Flink SQL 不支持 Session 窗口的 Window TVF,所以这里就只介绍 Group Window Aggregation 方案。
3.1 Group Window Aggregation 方案(支持 Batch / Streaming 任务)
-- 数据源表,用户购买行为记录表
CREATE TABLE source_table (-- 维度数据dim STRING,-- 用户 iduser_id BIGINT,-- 价格price BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.dim.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (dim STRING,pv BIGINT, -- 购买商品数量window_start bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECT dim,UNIX_TIMESTAMP(CAST(session_start(row_time, interval '5' minute) AS STRING)) * 1000 as window_start, count(1) as pv
FROM source_table
GROUP BY dim, session(row_time, interval '5' minute);
上述 SQL 任务是在整个 Session 窗口结束之后才会把数据输出。Session 窗口既支持 处理时间 也支持 事件时间。但是处理时间只支持在 Streaming 任务中运行,Batch 任务不支持。
可以看到 Group Window Aggregation 中 Session 窗口的写法就是把 Session Window 的声明写在了 group by 子句中,即 session(row_time, interval '5' minute)。其中:第一个参数为 事件时间的时间戳;第二个参数为 Session Gap 间隔。
4.渐进式窗口(CUMULATE)
渐进式窗口 定义(1.13 只支持 Streaming 任务):渐进式窗口在其实就是 固定窗口间隔内提前触发的的滚动窗口,其实就是 Tumble Window + early-fire 的一个事件时间的版本。例如,从每日零点到当前这一分钟绘制累积 UV,其中 10:00 时的 UV 表示从 00:00 到 10:00 的 UV 总数。渐进式窗口可以认为是首先开一个最大窗口大小的滚动窗口,然后根据用户设置的触发的时间间隔将这个滚动窗口拆分为多个窗口,这些窗口具有相同的窗口起点和不同的窗口终点。如下图所示:

- ⭐ 应用场景:周期内累计 PV,UV 指标(如每天累计到当前这一分钟的 PV,UV)。这类指标是一段周期内的累计状态,对分析师来说更具统计分析价值,而且几乎所有的复合指标都是基于此类指标的统计(不然离线为啥都要累计一天的数据,而不要一分钟累计的数据呢)。
- ⭐ 实际案例:每天的截止当前分钟的累计
money(sum(money)),去重id数(count(distinct id))。每天代表渐进式窗口大小为 1 天,分钟代表渐进式窗口移动步长为分钟级别。
明细输入数据:
| time | id | money |
|---|---|---|
| 2021-11-01 00:01:00 | A | 3 |
| 2021-11-01 00:01:00 | B | 5 |
| 2021-11-01 00:01:00 | A | 7 |
| 2021-11-01 00:02:00 | C | 3 |
| 2021-11-01 00:03:00 | C | 10 |
预期经过渐进式窗口计算的输出数据:
| time | count distinct id | sum money |
|---|---|---|
| 2021-11-01 00:01:00 | 2 | 15 |
| 2021-11-01 00:02:00 | 3 | 18 |
| 2021-11-01 00:03:00 | 3 | 28 |
转化为折线图长这样:

可以看到,其特点就在于,每一分钟的输出结果都是当天零点累计到当前的结果。
渐进式窗口目前只有 Windowing TVF 方案支持。
4.1 Windowing TVF 方案(1.13 只支持 Streaming 任务)
-- 数据源表
CREATE TABLE source_table (-- 用户 iduser_id BIGINT,-- 用户money BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.price.min' = '1','fields.price.max' = '100000'
);-- 数据汇表
CREATE TABLE sink_table (window_end bigint,window_start bigint,sum_money BIGINT,count_distinct_id bigint
) WITH ('connector' = 'print'
);-- 数据处理逻辑
insert into sink_table
SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, window_start, sum(money) as sum_money,count(distinct id) as count_distinct_id
FROM TABLE(CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND, INTERVAL '1' DAY))
GROUP BYwindow_start, window_end
可以看到 Windowing TVF 滚动窗口的写法就是把 Cumulate Window 的声明写在了数据源的 Table 子句中,即 TABLE(CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '60' SECOND, INTERVAL '1' DAY)),其中包含四部分参数:
- 第一个参数
TABLE source_table声明数据源表。 - 第二个参数
DESCRIPTOR(row_time)声明数据源的时间戳。 - 第三个参数
INTERVAL '60' SECOND声明渐进式窗口触发的渐进步长为 1 min。 - 第四个参数
INTERVAL '1' DAY声明整个渐进式窗口的大小为 1 天,到了第二天新开一个窗口重新累计。
5.Window TVF 支持 Grouping Sets、Rollup、Cube
实际的案例场景中,经常会有多个维度进行组合(cube)计算指标的场景。如果把每个维度组合的代码写一遍,然后 union all 起来,这样写起来非常麻烦,而且会导致一个数据源读取多遍。
这时,有离线 Hive SQL 使用经验的小伙伴萌就会想到,如果有了 Grouping Sets,我们就可以直接用 Grouping Sets 将维度组合写在一条 SQL 中,写起来方便并且执行效率也高。当然,Flink 支持这个功能。
但是目前 Grouping Sets 只在 Window TVF 中支持,不支持 Group Window Aggregation。
来一个实际案例感受一下,计算每日零点累计到当前这一分钟的 分汇总、age、sex、age+sex 维度的用户数。
-- 用户访问明细表
CREATE TABLE source_table (age STRING,sex STRING,user_id BIGINT,row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.age.length' = '1','fields.sex.length' = '1','fields.user_id.min' = '1','fields.user_id.max' = '100000'
);CREATE TABLE sink_table (age STRING,sex STRING,uv BIGINT,window_end bigint
) WITH ('connector' = 'print'
);insert into sink_table
SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, if (age is null, 'ALL', age) as age,if (sex is null, 'ALL', sex) as sex,count(distinct user_id) as bucket_uv
FROM TABLE(CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '5' SECOND, INTERVAL '1' DAY))
GROUP BY window_start, window_end,-- grouping sets 写法GROUPING SETS ((), (age), (sex), (age, sex));
Flink SQL 中 Grouping Sets 的语法和 Hive SQL 的语法有一些不同,如果我们使用 Hive SQL 实现上述 SQL 的语义,其实现如下:
insert into sink_table
SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, if (age is null, 'ALL', age) as age,if (sex is null, 'ALL', sex) as sex,count(distinct user_id) as bucket_uv
FROM source_table
GROUP BYage, sex
-- hive sql grouping sets 写法
GROUPING SETS ((), (age), (sex), (age, sex)
);
这篇关于【大数据】Flink SQL 语法篇(三):窗口聚合(TUMBLE、HOP、SESSION、CUMULATE)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






