本文主要是介绍递归神经网络:(01/4) 顺序数据处理的骨干,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一、说明
二、顺序数据处理的架构
递归神经网络 (RNN) 是一种专为处理顺序数据而设计的神经网络架构。它们特别适用于输入数据顺序至关重要的任务,例如自然语言处理、时间序列分析和语音识别。
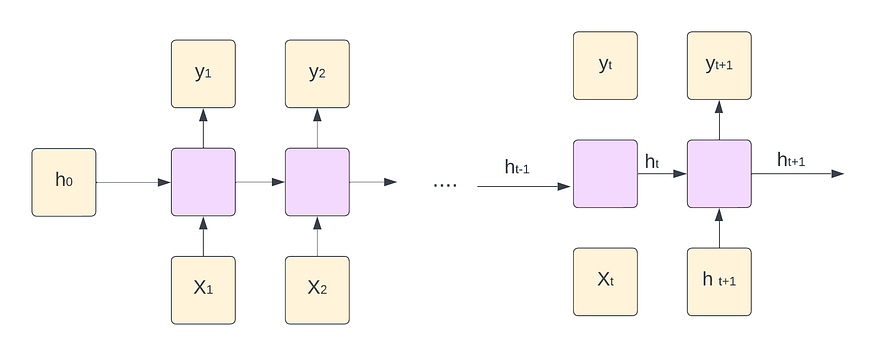
对于每个时间步长 t,激活 y<t>,h<t> 和输出表示如下:
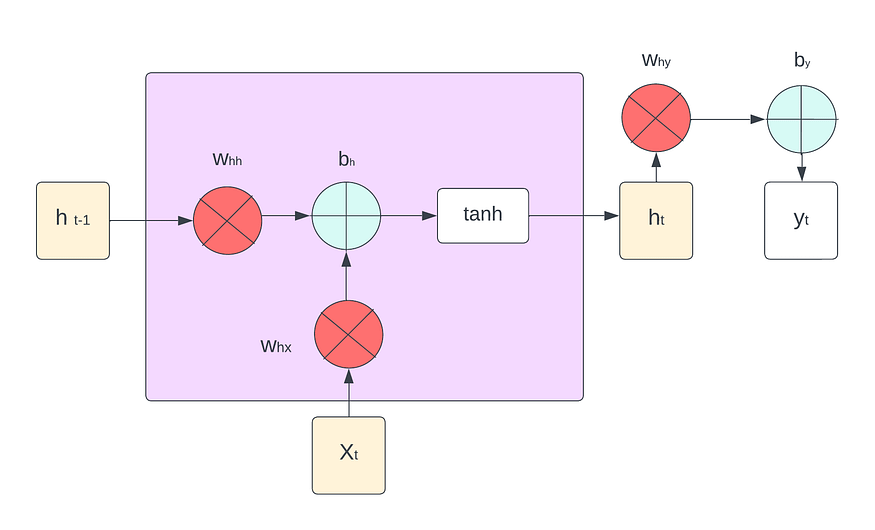
三、RNN 的每个时间步长如何工作
RNN 维护一个隐藏状态,该状态在每个时间步都会根据当前输入和之前的隐藏状态进行更新。这种隐藏状态用作内存,允许网络捕获有关先前输入的信息,并使用它来影响当前的预测。每个时间步的基本操作如下:
前向传播
![]()
![]()
这里:
- ht 是时间 t 的隐藏状态,
- xt 是时间 t 的输入,
- Whx,为什么是输入的权重矩阵,
- Whh 是隐藏状态的权重矩阵,
- bh, by 是偏置项,
代码单单元 RNN—
def forward(self, x):# this list i create for backpropagationself.intermediate_values = []hidden_states = []outputs = []for t in range(len(x)):x_t = x[t].reshape(-1, 1)h_t = np.tanh(np.dot(self.W_hx, x_t) + np.dot(self.W_hh, self.h_t) + self.b_h)y_t = np.dot(self.W_yh, h_t) + self.b_y# Store hidden state and output for this timestephidden_states.append(h_t)outputs.append(y_t)# Update hidden state for the next timestepself.h_t = h_t# Store intermediate values for backpropagationself.intermediate_values.append((x_t, h_t, y_t))return outputs, hidden_states损失函数 — 在递归神经网络的情况下,所有时间步长的损失函数 L 根据每个时间步长的损失定义如下:
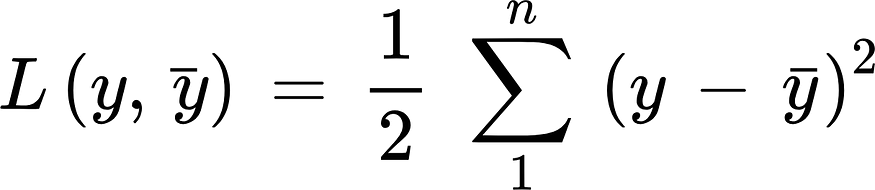
反向传播 —
1. 损失随时间的反向传播:
![]()
2. Whx 随时间的反向传播:
![]()
3. Whh 随时间的反向传播:
![]()
4. B H 随时间的反向传播:
![]()
5. Tanh 随时间的反向传播:
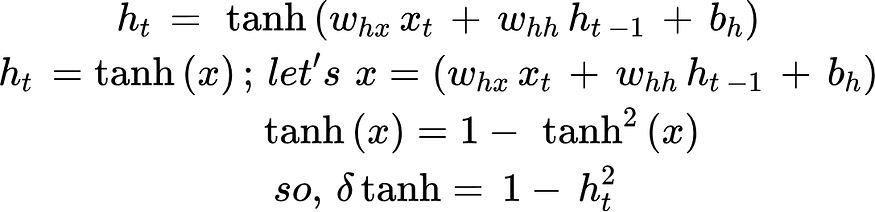
def backward(self, x, targets):# Initialize gradientsdL_dW_hx = np.zeros_like(self.W_hx)dL_dW_hh = np.zeros_like(self.W_hh)dL_db_h = np.zeros_like(self.b_h)dL_dW_yh = np.zeros_like(self.W_yh)dL_db_y = np.zeros_like(self.b_y)# Initialize gradient of loss with respect to hidden statedL_dh_t = np.zeros_like(self.h_t)# Backpropagation through timefor t in reversed(range(len(x))):x_t, h_t, y_t = self.intermediate_values[t]target_t = targets[t].reshape(-1, 1)# Compute loss gradient with respect to outputdL_dy_t = y_t - target_t #. 1# Compute gradient of loss with respect to hidden state# dervative of (h_t*w_hy+b_y) with respect of htdL_dh_t += np.dot(self.W_yh.T, dL_dy_t) # 2,3,4# Backpropagation through tanh#derivative of tanh(x) with respect to x is 1- tan**2(x)dtanh = (1 - h_t**2) * dL_dh_t # 5# Accumulate gradients for the parametersdL_dW_hx += np.outer(dtanh, x_t)dL_dW_hh += np.outer(dtanh, h_t)dL_db_h += dtanhdL_dW_yh += np.outer(dL_dy_t, h_t)dL_db_y += dL_dy_t# Update gradient of loss with respect to hidden state for the next timestep# dervative of (h_t-1*w_hh+b_y) with respect of ht-1dL_dh_t = np.dot(self.W_hh.T, dtanh)我们初始化每个参数的梯度和相对于隐藏状态 (ht) 的损失梯度。我们从最后一个时间步开始,通过时间进行反向传播。对于每个时间步长,我们计算参数的梯度,并累积相对于隐藏状态的损失梯度。使用梯度下降更新梯度。
四、通常使用以下方式的激活
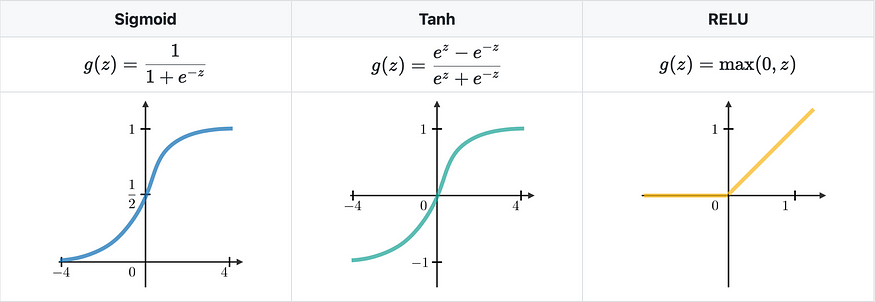
(3)激活。
培训 —
def train(self, x, targets, epochs):for epoch in range(epochs):# Forward passoutputs, _ = self.forward(x)# Compute and print the lossloss = 0.5 * np.mean((outputs - targets)**2)print(f"Epoch {epoch + 1}/{epochs}, Loss: {loss}")# Backward passself.backward(x, targets)我们执行指定数量的 epoch 的训练。在每个纪元中,我们执行前向传递,计算损失并打印它。然后,我们执行向后传递以更新模型参数。
五、RNN的应用
虽然上图中描绘了递归神经网络,即所谓的前馈网络,但它们并不以这种方式受到限制。相反,前馈网络将一个输入映射到一个输出。相反,它们的输入和输出的长度可能会有所不同,并且不同种类的 RNN 被用于各种用例,包括机器翻译、情感分析和音乐创作。

(4)RNN的应用。来源:Shervine博客
六、深度 RNN
处理深度递归神经网络 (RNN) 时,您有多种选择来设计和实现架构。一种常见的方法是堆叠多层 RNN,从而创建深度 RNN 架构。以下是有关如何设计深度 RNN 的说明:
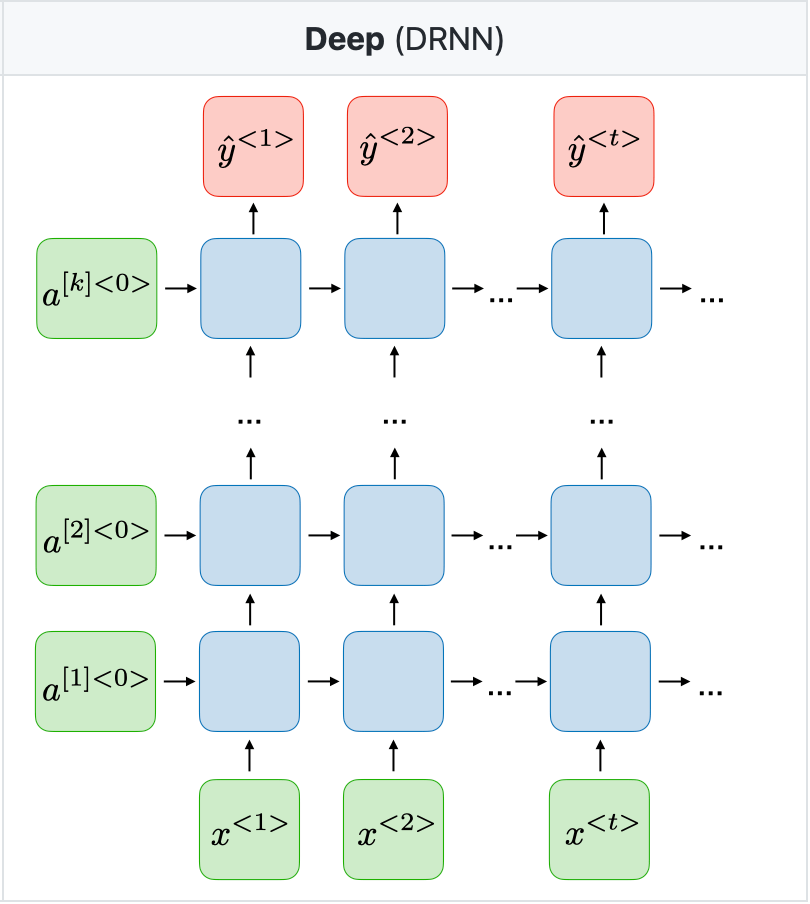
堆叠 RNN 层 —
- 您可以将多个 RNN 层堆叠在一起,以创建深度架构。
- 堆栈中的每一层都按顺序处理输入序列,其隐藏状态将作为输入传递到下一层。
- 顶层的输出通常用于进行预测或进一步处理。
深度 RNN 可能是计算密集型的,训练可能需要更长的时间。批量归一化或层归一化等技术对于训练更深层次的网络非常有用。您也可以考虑使用更高级的 RNN 架构(如 LSTM 或 GRU)来解决梯度消失/爆炸问题。
这篇关于递归神经网络:(01/4) 顺序数据处理的骨干的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



