本文主要是介绍使用Python和Echarts进行数据可视化分析:旅游景点销量和星级景点统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
##使用 Python 和 Echarts 进行数据可视化分析:以旅游景点销量和星级景点统计为例
基于全国各地区景点门票的售卖情况数据,分析全国热门景点分布和国民出游情况
(全国景点分布,国民假期出游分析及建议)
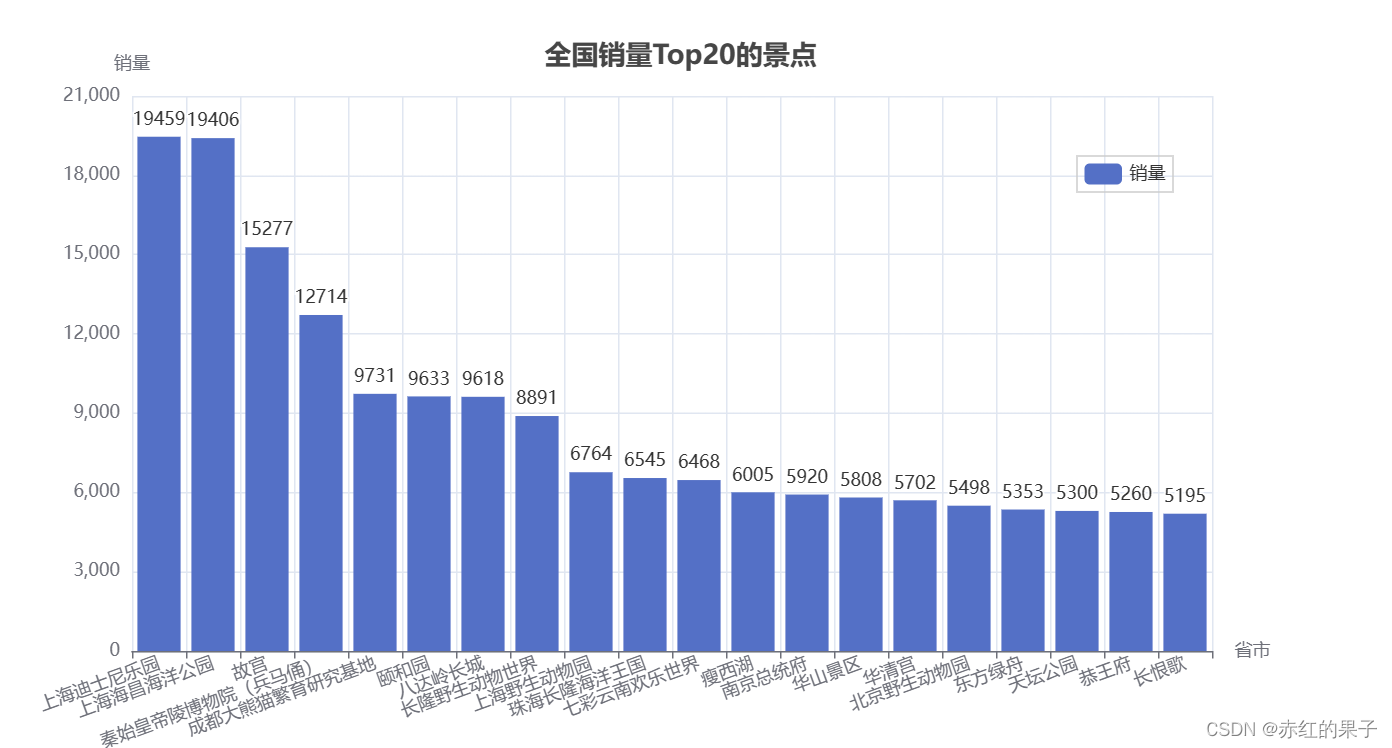
- 全国销量 Top20 的热门景点(热门景点);
- 全国各省市 4A、5A 景区数量(景点分布情况);
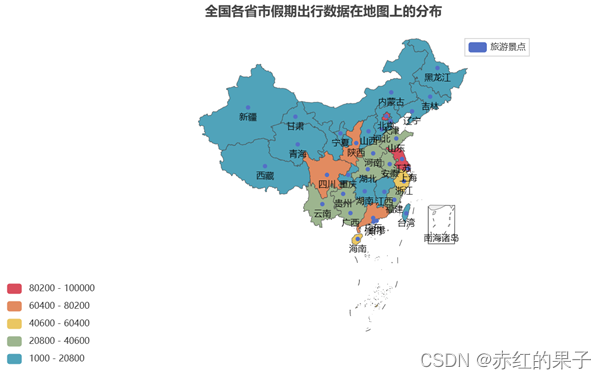
- 全国各省市假期出行数据在地图上的分布(出游分析及建议)。
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
# 用pandas读取、导入数据集
data = pd.read_excel("./旅游景点.xlsx")
print(data[:5])
数据集内容如下:
城市 名称 星级 评分 价格 销量 省/市/区 坐标 \
0 上海 上海迪士尼乐园 NaN 0.0 325.0 19459 上海·上海·浦东新区 121.667917,31.149712
1 上海 上海海昌海洋公园 4A 0.0 276.5 19406 上海·上海·浦东新区 121.915647,30.917713
2 上海 上海野生动物园 5A 3.6 116.0 6764 上海·上海·浦东新区 121.728112,31.059636
3 上海 东方绿舟 4A 3.5 40.0 5353 上海·上海·青浦区 121.015977,31.107866
4 上海 东方明珠 5A 3.8 54.0 3966 上海·上海·浦东新区 121.50626,31.245369简介 是否免费 具体地址
0 每个女孩都有一场迪士尼梦 False 上海市浦东新区川沙镇黄赵路310号上海迪士尼乐园
1 看珍稀海洋生物 | 玩超刺激娱乐项目 False 上海市浦东新区南汇城银飞路166号
2 全球动物聚集地 | 零距离和动物做朋友 False 上海市浦东新区南六公路178号
3 全国首屈一指的青少年校外教育营地 False 上海市青浦区沪青平公路6888号
4 感受云端漫步,品味老上海风情 False 上海市浦东新区世纪大道1号
# 销量Top20的热门景点
# 先将数据集按照销量多少进行排序 sort_values()
data_sale = data.sort_values(by="销量", ascending=False)
# print(data_sale[:20])
print(list(data_sale["名称"])[:20])
print(data_sale["销量"].values.tolist()[:20])
Sale = (Bar().add_xaxis(list(data_sale["名称"])[:20]).add_yaxis("销量", data_sale["销量"].values.tolist()[:20])#.set_global_opts(title_opts=opts.TitleOpts(title="全国销量Top20的景点", pos_top="4%", pos_left="40%"),# xaxis_opts=opts.AxisOpts(name="景点名称",# splitline_opts=opts.SplitLineOpts(is_show=True)),xaxis_opts=opts.AxisOpts(name="省市",axislabel_opts=opts.LabelOpts(interval=0, rotate=20),splitline_opts=opts.SplitLineOpts(is_show=True),),yaxis_opts=opts.AxisOpts(name="销量"),legend_opts=opts.LegendOpts(pos_left="80%", pos_top="20%"),).set_series_opts(label_opts=opts.LabelOpts(position="top"))# 生成.render("Top20销量.html")
)
['上海迪士尼乐园', '上海海昌海洋公园', '故宫', '秦始皇帝陵博物院(兵马俑)', '成都大熊猫繁育研究基地', '颐和园', '八达岭长城', '长隆野生动物世界', '上海野生动物园', '珠海长隆海洋王国', '七彩云南欢乐世界', '瘦西湖', '南京总统府', '华山景区', '华清宫', '北京野生动物园', '东方绿舟', '天坛公园', '恭王府', '长恨歌']
[19459, 19406, 15277, 12714, 9731, 9633, 9618, 8891, 6764, 6545, 6468, 6005, 5920, 5808, 5702, 5498, 5353, 5300, 5260, 5195]
绘图展示:
# 先从数据中提取出4A、5A星级的景点
data_rank = data[data["星级"].isin(["4A", "5A"])]
print(data_rank[:5])
# 统计各省市的星级景点数量
count = data_rank.groupby("城市").count()["星级"]print(count[:5])
Rank = (Bar().add_xaxis(count.index.values.tolist()).add_yaxis("4A, 5A级景点数量", count.values.tolist()).set_global_opts(title_opts=opts.TitleOpts(title="各省市4A-5A景区数量", pos_left="40%"),xaxis_opts=opts.AxisOpts(name="省市",axislabel_opts=opts.LabelOpts(interval=0, rotate=35),splitline_opts=opts.SplitLineOpts(is_show=True),),yaxis_opts=opts.AxisOpts(name="数量"),legend_opts=opts.LegendOpts(pos_left="80%", pos_top="15%"),).render("各省市4A-5A景区数量.html")
)
城市 名称 星级 评分 价格 销量 省/市/区 坐标 \
1 上海 上海海昌海洋公园 4A 0.0 276.5 19406 上海·上海·浦东新区 121.915647,30.917713
2 上海 上海野生动物园 5A 3.6 116.0 6764 上海·上海·浦东新区 121.728112,31.059636
3 上海 东方绿舟 4A 3.5 40.0 5353 上海·上海·青浦区 121.015977,31.107866
4 上海 东方明珠 5A 3.8 54.0 3966 上海·上海·浦东新区 121.50626,31.245369
7 上海 上海科技馆 5A 3.7 45.0 2120 上海·上海·浦东新区 121.54785,31.224219简介 是否免费 具体地址
1 看珍稀海洋生物 | 玩超刺激娱乐项目 False 上海市浦东新区南汇城银飞路166号
2 全球动物聚集地 | 零距离和动物做朋友 False 上海市浦东新区南六公路178号
3 全国首屈一指的青少年校外教育营地 False 上海市青浦区沪青平公路6888号
4 感受云端漫步,品味老上海风情 False 上海市浦东新区世纪大道1号
7 魔都科普教育殿堂 | 周末遛娃圣地 False 上海市浦东新区世纪大道2000号(近二号线上海科技馆站)
城市
上海 25
云南 31
内蒙古 23
北京 38
吉林 10
Name: 星级, dtype: int64
绘图展示: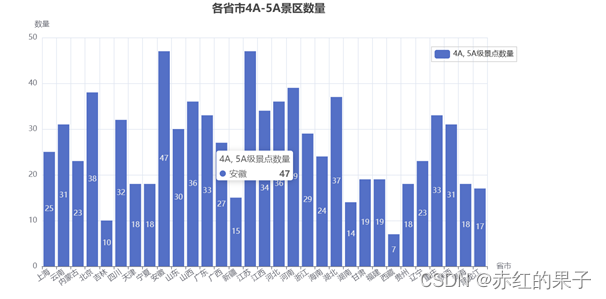
# 合并生成的两个html中的表格
# 可以不进行合并
with open("Top20销量.html", "r", encoding="utf-8") as f1:html1 = f1.read()with open("各省市4A-5A景区数量.html", "r", encoding="utf-8") as f2:html2 = f2.read()final_html = html1 + html2with open("final.html", "w", encoding="utf-8") as f:f.write(final_html)
# 全国各省市假期出行数据在地图上的分布
data_city = data[["城市", "销量"]]
print(data_city[:5])
# 对各省市销量累加求和
city_cnt = data_city.groupby("城市").sum()["销量"]
print(city_cnt[:5])
city_list = city_cnt.index.tolist()
sale_list = city_cnt.values.tolist()
print(city_list)
print(sale_list)namemap = {"黑龙江省": "黑龙江","吉林省": "吉林","辽宁省": "辽宁","北京市": "北京","天津市": "天津","河北省": "河北","山西省": "山西","内蒙古自治区": "内蒙古","上海市": "上海","江苏省": "江苏","山东省": "山东","浙江省": "浙江","安徽省": "安徽","江西省": "江西","福建省": "福建","广东省": "广东","澳门特别行政区": "澳门","台湾省": "台湾","香港特别行政区": "香港","西藏自治区": "西藏","广西壮族自治区": "广西","海南省": "海南","河南省": "河南","湖北省": "湖北","湖南省": "湖南","陕西省": "陕西","新疆维吾尔自治区": "新疆","宁夏回族自治区": "宁夏","甘肃省": "甘肃","青海省": "青海","重庆市": "重庆","四川省": "四川","贵州省": "贵州","云南省": "云南",
}c = (Map()# 添加中国地图.add("旅游景点", [list(z) for z in zip(city_list, sale_list)], "china", name_map=namemap).set_global_opts(title_opts=opts.TitleOpts(title="全国各省市假期出行数据在地图上的分布", pos_left="30%"),legend_opts=opts.LegendOpts(pos_top="10%", pos_left="70%"),visualmap_opts=opts.VisualMapOpts(min_=1000, max_=100000, is_piecewise=True),).render("全国各省市假期出行数据在地图上的分布.html")
)
城市 销量
0 上海 19459
1 上海 19406
2 上海 6764
3 上海 5353
4 上海 3966
城市
上海 84084
云南 28056
内蒙古 3959
北京 93987
台湾 1001
Name: 销量, dtype: int64
['上海', '云南', '内蒙古', '北京', '台湾', '吉林', '四川', '天津', '宁夏', '安徽', '山东', '山西', '广东', '广西', '新疆', '江苏', '江西', '河北', '河南', '浙江', '海南', '湖北', '湖南', '澳门', '甘肃', '福建', '西藏', '贵州', '辽宁', '重庆', '陕西', '青海', '香港', '黑龙江']
[84084, 28056, 3959, 93987, 1001, 3772, 65052, 5254, 5622, 21027, 32147, 15904, 62757, 37946, 3614, 80783, 11046, 6826, 33776, 45481, 44123, 22563, 6980, 3128, 4338, 23256, 7028, 22499, 10423, 20054, 64353, 4591, 1006, 4639]
绘图展示:
echarts 官方文档
这篇关于使用Python和Echarts进行数据可视化分析:旅游景点销量和星级景点统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





