本文主要是介绍SCI 2区论文:医疗保健中心训练有素的脑膜瘤分割模型的性能测试-基于四个回顾性多中心数据集的二次分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基本信息
- 标题:Performance Test of a Well-Trained Model for Meningioma Segmentation in Health Care Centers: Secondary Analysis Based on Four Retrospective Multicenter Data Sets
- 中文标题:医疗保健中心训练有素的脑膜瘤分割模型的性能测试:基于四个回顾性多中心数据集的二次分析
- 发表年份: 2023年12月
- 期刊/会议: Journal of Medical Internet Research
- 分区: SCI 2区
- IF:7.076
- 作者: Chaoyue Chen; Jianguo Xu(一作;通讯)
- 单位:华西 神经外科
- DOI:10.2196/44119
- 开源代码:无
摘要: 背景:CNN在磁共振成像脑膜瘤分割方面取得了最先进的结果。然而,从不同机构、协议或扫描仪获得的图像可能会显示出显着的域转移(domain shift),从而导致性能下降并在实际临床场景中挑战模型部署。
客观的:本研究旨在调查训练有素的脑膜瘤分割模型在不同医疗保健中心部署时的实际性能,并验证增强其泛化能力的方法。
方法:这项研究在四个中心进行。2015 年 1 月至 2021 年 12 月期间,共有 606 名患者进行了 606 次 MRI 入组。通过神经放射科医生的共识读数确定的手动分割被用作基本事实掩模。该模型之前使用名为 Deeplab V3+ 的标准监督 CNN 进行训练,并在四个医疗保健中心分别部署和测试。为了确定减轻观察到的性能下降的适当方法,使用了两种方法:无监督域适应和监督再训练。
结果:训练后的模型在两个医疗机构的肿瘤分割方面表现出了最先进的性能,中心 A 的 Dice 比为 0.887,B 中心的 Dice 比为 0.874,C 中心的 Dice 比率为 0.631,D 中心的 Dice 比率为 0.649,因为他们使用不同的扫描协议获得 MRI。采用无监督域适应后,性能得分显着提高,中心 C 的 Dice 比率为 0.842,中心 D 的 Dice 比率为 0.855。有监督再训练后,性能进一步提升,中心 C 的 Dice 比率为 0.899,中心 D 的 Dice 比率为 0.886。
结论:在不同的医疗保健机构中部署经过训练的 CNN 模型可能会因 MRI 的域转移而出现显着的性能下降。在这种情况下,应考虑使用无监督领域适应或有监督再训练,同时考虑临床需求、模型性能和可用数据大小之间的平衡。
章节速览
-
- Introduction
-
- Methods
- 2.1 研究人群
- 2.2 图像预处理和标注
- 2.3 Well-Trained 模型测试
- 2.4 通过无监督域适应增强性能
- 2.5 通过监督再训练增强性能
- 2.6 道德考虑
-
- Results
- 3.1 研究队列的特征
- 3.2 四家公立医疗机构模型测试
- 3.3 通过无监督域适应增强性能
- 3.4 通过监督再培训提高性能
-
- Discussion
- 4.1 主要发现
- 4.2 相关工作和模型测试结果的解释
- 4.3 模型增强的相关工作及结果解读
- 4.4 局限性
- 4.5 结论
- 4.6 致谢
1. Introduction
迄今为止,所有研究脑膜瘤分割的 CAD 研究都使用与训练数据集相似的图像来测试 CNN 模型的稳健性。然而,当通过不同的扫描协议获取时,医学图像(尤其是 MRI)中的目标在图像模式上可能会有很大差异。与计算机断层扫描不同,在计算机断层扫描中,各个组织和邻近结构都有自己典型的计算机断层扫描编号(HU),而 MRI 上的组织信号强度是由多种因素决定的,包括扫描仪制造商;成像参数,例如造影剂施用、重复和回波时间;k空间填充策略;和重建算法。因此,从不同协议或扫描仪获得的图像可能会显示出显着的域转移,导致模型性能下降并对其在公共医疗保健机构中的部署提出挑战。鉴于脑膜瘤图像分割的重要性,应该研究训练有素的模型在不同的公共卫生保健中心使用时的实际表现。
为了减轻这一限制并满足临床需求,我们在四个公共医疗中心部署并测试了训练有素的脑膜瘤分割模型。此外,我们还探讨了再训练和迁移学习的功效,因为当模型表现出性能显着下降时,这些技术被广泛使用。这项研究是第一项专注于脑膜瘤分割模型部署和测试的研究,将为可能从 CAD 研究中受益最多的临床医生提供详细的统计数据
2. Methods
2.1 研究人群
所有患者均于2015年1月至2021年12月期间接受肿瘤切除术并病理诊断为脑膜瘤。
使用不同制造商的 3.0 T 和 1.5 T MR 机器以及不同的扫描协议对患者进行检。中心 A 和 B 中使用快速梯度回波序列(GRE),而中心 C 和 D 使用脂肪抑制快速自旋回波(FSE / TSE)。具体的扫描协议如下:


2.2 图像预处理和标注
空间分辨率重新采样为 1 × 1 × 1(中心 A 和 B)或 1 × 1 × 5(中心 C 和 D),强度标准化为 [0,1]。使用ITK-SNAP手动标注。
2.3 Well-Trained 模型测试(model 1)
使用 Deeplab V3+ 深度学习架构在 A 中心收集的735例病例图像进行训练,并在内部测试中表现出良好的性能。该训练好的模型的性能在四家医疗机构中进行了独立测试。
2.4 通过无监督域适应增强性能(model 2)
模型2是使用无监督域适应方法生成的,该方法是我们团队专门为脑膜瘤分割设计的。该网络的主要目的是通过最小化源域和目标域的分布来调整特征。网络结构、数据参数和超参数设置的详细描述见多媒体附录4 。
将来自中心 A 的所有带有手动标签的图像设置为源,并将来自中心 C 和 D 的无标签的随机选择案例的 80% 设置为生成对抗性学习的目标域。将C中心和D中心的其余病例设置为测试组。
2.5 通过监督再训练增强性能(model 3)
模型 3 也使用 Deeplab V3+ 进行训练,就像模型 1 一样。从中心 C 和 D 中,随机选择 80% 的病例作为训练队列,20% 的病例作为测试队列
3.Results
3.1 研究队列的特征
图 2.来自四个数据库的磁共振成像示例。(图A) 中心 A(MPR-AGEs);(图B-C) 中心 B (MPR-AGE);(图D-G) 中心 C(脂肪抑制FSE/TSE);(图H) 中心 D(FSE/TSE)。MPR-AGE 中的肿瘤边界更加清晰,因为它们具有高空间分辨率(红色箭头)。此外,大脑皮层在 MPR-AGE 中相当明显,但在 FSE/TSE 中则不然,因为 FSE/TSE 是脂肪抑制的(黄色箭头)

3.2 四家公立医疗机构模型测试
在中心 A 进行了训练,并在四家机构进行了测试,测试结果如下图

3.3 通过无监督域适应增强性能
通过所提出的迁移学习网络,CNN 模型的性能显着增强.如图所示
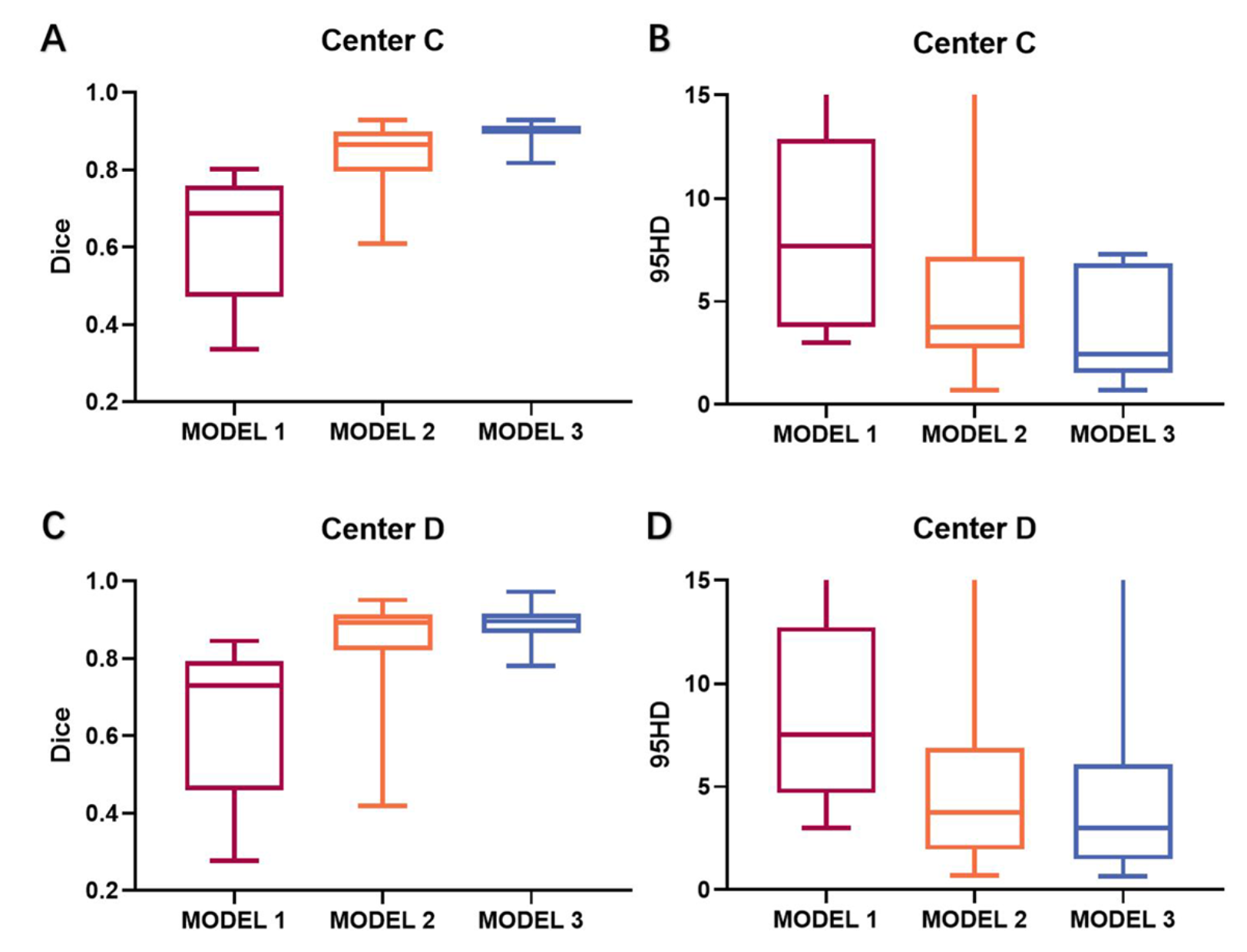

3.4 通过监督再培训提高性能
总体而言,监督训练的模型 3 与模型 2 相比表现出优越的性能。模型2和模型3的分割性能总结为表3

4 讨论
在这项研究中,我们在四个独立的医疗机构中测试了训练有素的 CNN 脑膜瘤分割模型的性能。结果表明,该模型只能在使用与训练数据集类似的协议进行 MR 扫描的机构中保持其临床可行性。此外,无监督域适应方法的性能显着提高,但无法超越在大规模数据集上训练的有监督模型。与之前的研究相比,本研究应被视为对模型部署的二次分析,以深入了解在临床实践中验证人工智能方法的重要性。
这项研究有几个局限性。首先,仅使用对比度增强的图像。其他类型的图像,包括 T1 加权图像、T2 加权图像和液体衰减反转恢复,也常用于临床实践。这些成像序列应该在未来的研究中进行研究。
其次,所有涉及的患者都接受了手术切除,这意味着早期肿瘤的数量是有限的。第三,考虑到回顾性研究的遗传性选择偏倚,应该要求在多个中心进行前瞻性研究来验证我们的结果。第四,我们的研究重点是模型测试和方法验证。本文使用的所有方法均已被报道过,并且在网络架构方面没有方法上的创新。
用于脑膜瘤分割的监督训练 CNN 模型只能在具有训练数据的相似域特征的 MRI 上保持其可行性。当模型表现出显着下降的性能时,可以使用无监督域适应方法,但它不能超越需要ground truth 的有监督再训练方法。
文章持续更新,可以关注微公【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连

这篇关于SCI 2区论文:医疗保健中心训练有素的脑膜瘤分割模型的性能测试-基于四个回顾性多中心数据集的二次分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







