本文主要是介绍69.Spark大型电商项目-用户访问session分析-算子调优之MapPartitions提升Map类操作性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
普通的map操作
MapPartitions操作
MapPartitions操作的优点
MapPartitions操作的缺点
MapPartitions系列操作建议
本篇文章记录用户访问session分析-算子调优之MapPartitions提升Map类操作性能。
普通的map操作
数据一条一条的操作。

public static JavaPairRDD<String,Row> getSessionid2ActionRDD(JavaRDD<Row> actionRDD){/*** 使用mapToPair处理单条的数据*/return actionRDD.mapToPair(new PairFunction<Row, String, Row>() {private static final long serialVersionUID = 1L;@Overridepublic Tuple2<String, Row> call(Row row) throws Exception {return new Tuple2<String,Row>(row.getString(2),row);}});}
MapPartitions操作
spark中,最基本的原则,就是每个task处理一个RDD的partition。
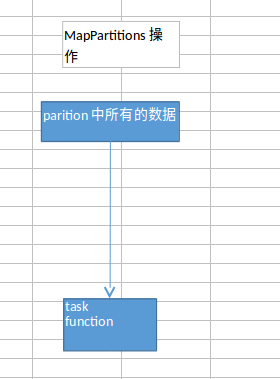
MapPartitions操作的优点
如果是普通的map,比如一个partition中有1万条数据;那么function要执行和计算1万次。
但是,使用MapPartitions操作之后,一个task仅仅会执行一次function,function一次接收所有的partition数据。只要执行一次就可以了,性能比较高。
MapPartitions操作的缺点
如果是普通的map操作,一次function的执行就处理一条数据;那么如果内存不够用的情况下,比如处理了1千条数据了,那么这个时候内存不够了,那么就可以将已经处理完的1千条数据从内存里面垃圾回收掉,或者用其他方法,腾出空间来吧。
所以说普通的map操作通常不会导致内存的OOM异常。
但是MapPartitions操作,对于大量数据来说,比如甚至一个partition,100万数据,一次传入一个function以后,那么可能一下子内存不够,但是又没有办法去腾出内存空间来,可能就OOM,内存溢出。
public static JavaPairRDD<String,Row> getSessionid2ActionRDD(JavaRDD<Row> actionRDD){/*** 使用PairPartitions进行数据处理*/return actionRDD.mapPartitionsToPair(new PairFlatMapFunction<Iterator<Row>, String, Row>() {private static final long serialVersionUID = 1L;@Overridepublic Iterator<Tuple2<String, Row>> call(Iterator<Row> iterator) throws Exception {List<Tuple2<String,Row>> list = new ArrayList<Tuple2<String,Row>>();while (iterator.hasNext()){Row row = iterator.next();list.add(new Tuple2<String,Row>(row.getString(2),row));}return list.iterator();}});}
MapPartitions系列操作建议
什么时候比较适合用MapPartitions系列操作,就是说,数据量不是特别大的时候,都可以用这种MapPartitions系列操作,性能还是非常不错的,是有提升的。比如原来是15分钟,(曾经有一次性能调优),12分钟。10分钟->9分钟。
但是也有过出问题的经验,MapPartitions只要一用,直接OOM,内存溢出,崩溃。
在项目中,自己先去估算一下RDD的数据量,以及每个partition的量,还有自己分配给每个executor的内存资源。看看一下子内存容纳所有的partition数据,行不行。如果行,可以试一下,能跑通就好。性能肯定是有提升的。
但是试了一下以后,发现,不行,OOM了,那就放弃吧。
这篇关于69.Spark大型电商项目-用户访问session分析-算子调优之MapPartitions提升Map类操作性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





