本文主要是介绍K-Means算法实现鸢尾花数据集聚类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1. 作者介绍
- 2. K-Means聚类算法
- 2.1 基本概念
- 2.2 算法流程
- 3. K-Means聚类算法实现
- 3.1 鸢尾花数据集
- 3.2 准备工作
- 3.3 代码实现
- 3.4 结果展示
- 4. 问题与解析
- 参考链接
1. 作者介绍
张勇,男,西安工程大学电子信息学院,2022级研究生
研究方向:智能信息处理与信息系统研究
电子邮件:17605542959@163.com
陈梦丹,女,西安工程大学电子信息学院,2022级硕士研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:1169738496@qq.com
2. K-Means聚类算法
2.1 基本概念
K-Means聚类算法即K均值算法,是一种迭代求解的聚类分析算法,是一个将数据集中在某些方面相似的数据成员进行分类组织的过程。给定一个数据点集合和需要的聚类数目K,K由用户指定,K均值算法根据某个距离函数反复把数据分入K个聚类中。
K均值算法优势在于它速度很快,原理简单、易于操作,但是也有缺点:(1)必须选择有多少个组或类;(2)不同的算法运行中可能产生不同的聚类结果,结果不可重复,缺乏一致性;(3)常常终止于局部最优;(4)对噪声和异常数据敏感及不适合用于发现非凸形状的聚类簇。
2.2 算法流程
K-Means的核心目标是将给定的数据集划分成K个簇(K是超参),并给出每个样本数据对应的中心点。具体步骤非常简单,可以分为4步:
- 数据预处理。主要是标准化、异常点过滤。
- 随机选取K个中心,记为 :
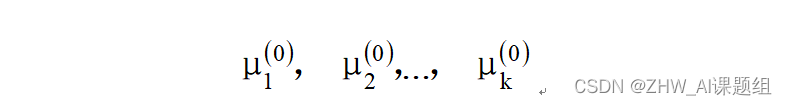
- 定义损失函数:
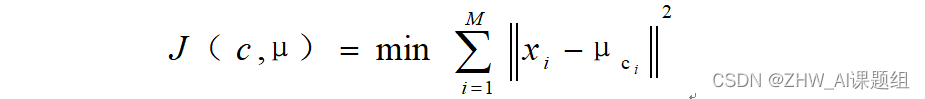
- 令t=0,1,2,… 为迭代步数,重复如下过程知道J 收敛:
(1)对于每一个样本,将其分配到距离最近的中心
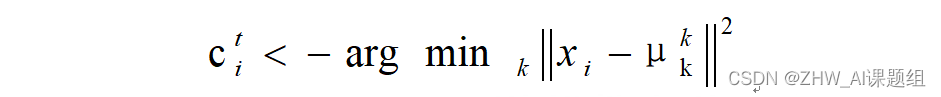
(2)对于每一个类中心k,重新计算该类的中心
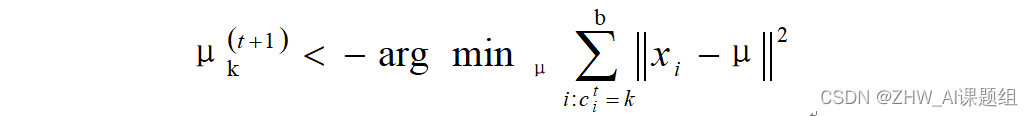
3. K-Means聚类算法实现
3.1 鸢尾花数据集
Iris鸢尾花数据集: 包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条数据,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,通常可以通过这4个特征预测鸢尾花卉属于哪一品种。

Iris数据集是一个.csv文件,其数据格式如下:
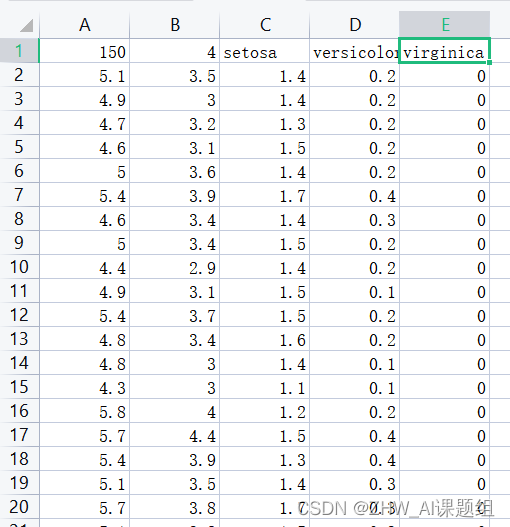
图中第一行数据的意义是:150(数据集中数据的总条数);4(特征值的类别数),即花萼长度、花萼宽度、花瓣长度、花瓣宽度;setosa、versicolor、virginica:三种鸢尾花名。
从第二行开始各列数据的意义:第一列为花萼长度值;第二列为花萼宽度值;第三列为花瓣长度值;第四列为花瓣宽度值;第五列对应是种类(三类鸢尾花分别用0,1,2表示)。
3.2 准备工作
1、首先要在自己的Python环境中下载sklearn(进入个人虚拟环境并输入):
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
2、下载数据集:
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.datasets import load_iris
iris = load_iris()
3.3 代码实现
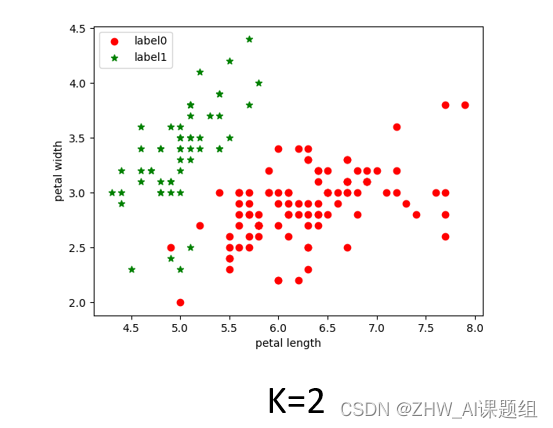
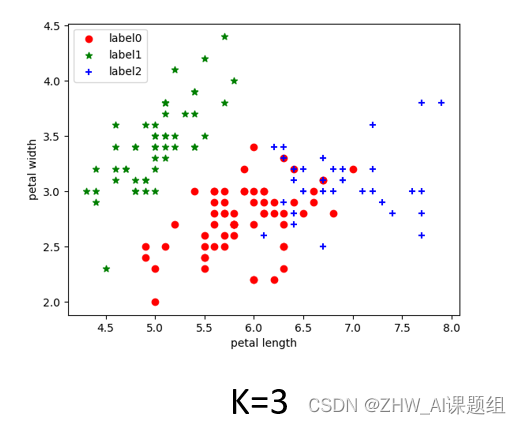
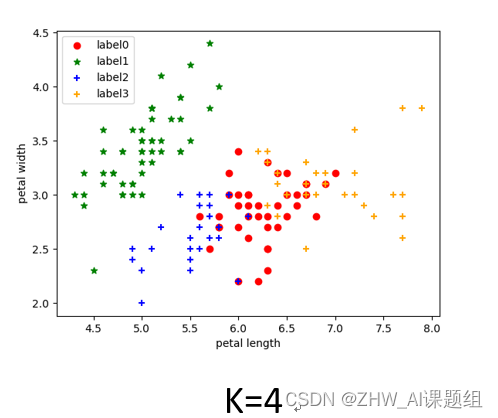
当K分别等于2、3、4时,具体实现代码如下:
K=2:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:]
estimator = KMeans(n_clusters=2) #构造聚类器,这里聚成两类
estimator.fit(X) #聚类
label_pred = estimator.labels_ #获取聚类标签
#绘图
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker='*', label='label1')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
K=3:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:]
estimator = KMeans(n_clusters=3) #构造聚类器,这里聚成两类
estimator.fit(X) #聚类
label_pred = estimator.labels_ #获取聚类标签
#绘图
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c = "blue", marker='+', label='label2')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
K=4:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:]
estimator = KMeans(n_clusters=4) #构造聚类器,这里聚成两类
estimator.fit(X) #聚类
label_pred = estimator.labels_ #获取聚类标签
#绘图
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
x3 = X[label_pred == 3]
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c = "blue", marker='+', label='label2')
plt.scatter(x3[:, 0], x3[:, 1], c = "orange", marker='+', label='label3')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
3.4 结果展示
4. 问题与解析
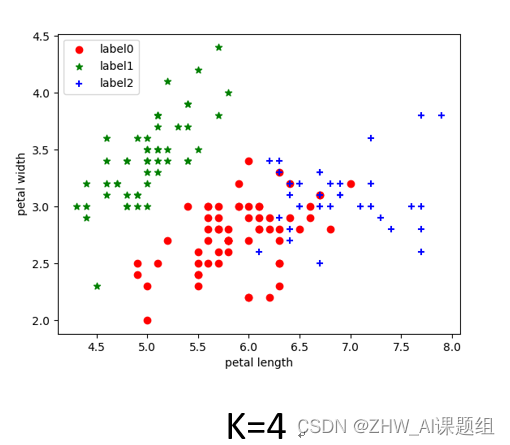
在构建聚类器时,修改K值,即修改需要分成几类(簇),单单修改参数cluster=2、3、4是不正确的,在绘图程序部分也要与之对应进行修改。
例如:cluster=4,绘图程序仍然用cluster=3的绘图程序,虽然程序不会报错,但是导致分类只有三类,实验结果错误。下面是错误代码及结果演示:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:]
estimator = KMeans(n_clusters=4) #构造聚类器,这里聚成两类
estimator.fit(X) #聚类
label_pred = estimator.labels_ #获取聚类标签
#绘图
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c = "green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c = "blue", marker='+', label='label2')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()
错误代码实验结果展示:
参考链接
https://zhuanlan.zhihu.com/p/184686598?utm_source=qq
https://blog.csdn.net/u010916338/article/details/86487890
这篇关于K-Means算法实现鸢尾花数据集聚类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


