本文主要是介绍带你了解弯曲文本检测算法的两种思路:区域重组和像素分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:文本检测是文本读取识别的第一步,对后续的文本识别有着重大的影响。
本文分享自华为云社区《技术综述十三:弯曲文本检测算法(一)》,作者: 我想静静。
背景介绍
文本检测是文本读取识别的第一步,对后续的文本识别有着重大的影响。一般场景下,可以通过对通用目标检测算法进行配置修改,来实现对文本行的检测定位。然而在弯曲文字场景,通用目标检测算法无法实现对文字边框的精准表述。因此,近年来很多学术论文都提出了新颖的解决场景文字检测的算法,主要包括两种思路:1. 基于区域重组的文本检测;2. 基于像素分割的文本检测。
区域重组的文本检测算法
PixelLink
PixelLink主要是针对相邻文本难以分离这个问题而提出的。该方法主要是预测文本/非文本区域,以及每个像素和它的上、下、左、右、左上、右上、左下、右下的像素之间的连接关系。在推理阶段,被预测为文本的像素和与该像素具有连接关系的像素被连接在一起。最后每个连接组件的最小外接矩形作为文本边框。

图1. PinxelLink 算法框架
由于使用了基于连通域的方法进行文本像素汇聚,导致该方法对噪声比较敏感,在推理阶段容易生成一些面积较小的false positives。作者通过去除掉短边小于10个像素或者面积小于300个像素的检测结果来缓解这个问题。
TextSnake
TextSnake 主要是针对使用四边形框不能有效地检测任意形状文本而提出的。该方法使用一系列重叠的圆盘来表示文本区域,每个圆盘有特定的圆心、半径、方向。如图1所示,通过预测文本区域、文本中心线(实际上是中心区域)、文本中心线上每个点对应的半径以及角度来重建文本轮廓。后处理阶段需要从预测的文本中心区域获得多个中心点作为圆盘的圆心,然后根据圆心对应的半径画圆,最后将所有圆的轮廓包围起来得到最终的文本边界框。
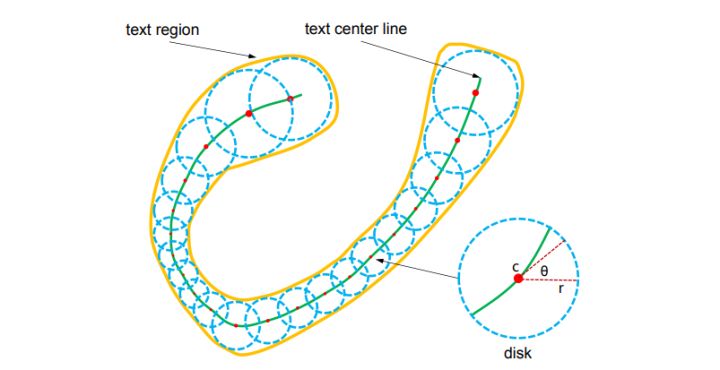
图2. TextSnake 文本表征方法

图3. 中心点机制
获得圆盘中心点的步骤如图3所示,首先在预测的文本中心区域随机取一个点,然后根据预测的方向做该点的切线和法线,法线和文本中心区域的两端的交点的中点(图(a)的红点)即是该处的中心点(作为圆盘的圆心)。中心点沿着两个相反的方向前进一定的步长,得到两个新的点,而后根据这两个新的点再寻找对应的中点。以此类推,直到进行到文本中心区域的两端。
该方法能有效地检测任意形状、方向的文本,但是后处理比较复杂且耗时。
CRAFT
CRAFT主要是针对基于字符级的文本检测方法对于曲形文本检测存在限制的问题而提出的,但同样适用于弯曲文本检测。该论文的思路是通过回归字符和字符间的亲和力来检测任意形状文本,这里的亲和力是用于表示相邻的字符是否属于同一个文本实例。此外,由于很多数据集没有提供字符级标注,本文提出一个弱监督算法来从字级标注中生成字符级标注。
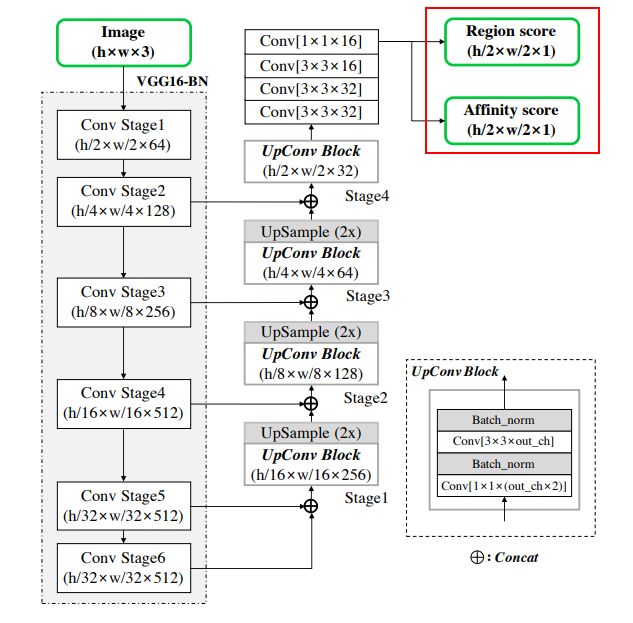
图4. CRAFT网络架构
如图4所示,字符区域和相邻字符亲和力都是通过一个通道进行回归得到。

图5. CRAFT 字符区域的ground-truth生成方法
用于训练模型的字符区域得分和亲和力得分的ground truth生成过程如图5所示。对于字符区域得分,首先生成一个2D高斯图,然后计算该高斯图变换到对应的字符框的透视变换矩阵,最后使用这个矩阵将2D高斯图变换到相应的字符区域。对于亲和力得分的ground-truth的生成也是使用相同的方法,前提只需要获得亲和力框。获得亲和力框的过程如下:1. 每个字符框连接对角线将字符框划分为4个三角形,取上下方的三角形的中心作为亲和力框的顶点。2.相邻两个字符框得到的2个上三角形和下三角形的中心作为四边形的顶点构成了一个亲和力边框。
弱监督字符生成算法生成字符伪标签的过程: 1. 使用在合成数据集训练好的模型预测剪裁下来的文本区域的字符区域得分;2. 使用分水岭算法得到每个字符区域;3. 将坐标变换到原图得到实际的字符边框坐标。

图6. CRAFT 弱监督学习过程
后处理:在推理阶段,预测出字符和亲和力图之后,置信度大于指定阈值的字符区域和亲和力区域都被置为1。然后标记每个连通区域。最后,对于四边形文本,使用最小外界矩形作为边框。
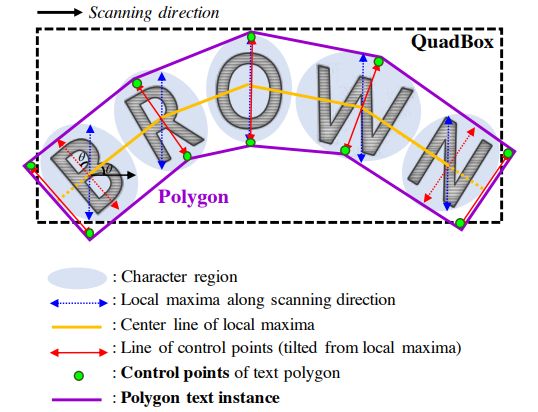
图7. 弯曲文本边框重组过程。
对于曲形文本,获得文本轮廓的过程如图7所示:第一步是沿着字符的方向找到每个字符区域的局部最长线;每条线的中心连接起来的线为中心线;每条局部最长线旋转到与中心线垂直;两端的线移动到文本区域的两端;将所有端点连接得到曲形文本边框。
区域重组的文本检测算法
PSENet
PSENet 是一个纯分割的文本检测方法,该方法的初衷是为了有效地分离任意形状的相邻文本。它通过预测多个尺度的文本分割图来实现这个目的。具体如图1所示,这里以预测3个尺度的分割图为例,即(a),(e),(f)。后处理的流程如下:首先从最小尺度的分割图(a)给各个连接组件分配标签,然后将(a)向四周扩张从而合并(e)中的被预测为文本的像素。同理,合并(f)中的文本像素。

图1. PSENet 渐进式扩展过程
这种渐进地、从小到大合并相邻文本像素的方法能有效地分离相邻文本实例,但是付出的代价就是速度很慢,通过C++能缓解速度慢的问题。
PAN
PAN主要是针对现有的文本检测方法速度太慢,不能实现工业化应用而设计的。该方法从两方面来提升文本检测的速度。第一,从网络结构上,该方法使用了轻量级的ResNet18作为backbone。但ResNet18的特征提取能力不够强,并且得到的感受野不够大。因此,进一步提出了轻量级的特征增强模块和特征融合模块,该特征增强模块类似于FPN,且可以多个级联在一起。特征增强模块在只增加少量的计算量的前提下有效地增强了模型的特征提取能力,并增大了感受野。第二,从后处理上提升速度。该方法通过预测文本区域,文本中心区域(kernel),以及像素间的相似度来检测文本。使用聚类的思想,kernel是聚类中心,文本像素是需要聚类的样本。为了聚类,属于同一个文本实例的kernel和对应的像素的相似度向量之间的距离应该尽可能小,不同kernels的相似度向量的距离应该远。在推理阶段,首先根据kernel得到连接组件,然后沿着四周合并与kernel的距离小于阈值d的像素。该方法在实现高精度的同时还取得了实时的文本检测速度.
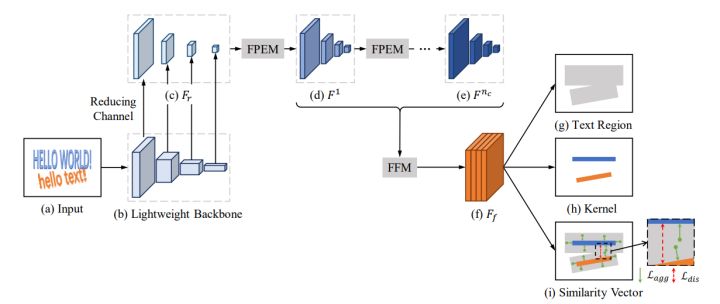
图2. PAN网络结构
MSR
MSR是为了解决多尺度文本检测困难而提出来的。与别的文本检测方法不同,该方法使用了多个一样的backbone,并将输入图像下采样到多个尺度之后连同原图一起输入到这些backbone,最后不同的backbone的特征经过上采样之后进行融合,从而捕获了丰富的多尺度特征。网络最后预测文本中心区域、文本中心区域每个点到最近的边界点的x坐标偏移和y坐标偏移。在推理阶段,文本中心区域的每个点根据预测的x/y坐标偏移得到对应的边界点,最终的文本轮廓是包围所有边界点的轮廓。
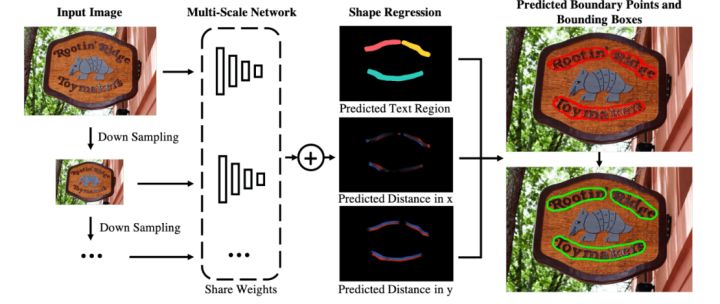
图3. MSR算法框架

图4:MSR网络结构
该方法的优点是对于多尺度文本有较强的检测能力,但是由于该方法定义的文本中心区域只是文本区域在上下方向上进行了缩小,而左右方向没有缩小,因此无法有效分离水平上相邻的文本。
DB
DB主要是针对现有的基于分割的方法需要使用阈值进行二值化处理而导致后处理耗时且性能不够好而提出的。该方法很巧妙地设计了一个近似于阶跃函数的二值化函数,使得分割网络在训练的时候能学习文本分割的阈值。此外,在推理阶段,该方法根据文本中心区域的面积和周长直接扩张一定的比例得到最终的文本轮廓,这也进一步提升了该方法的推理速度。整体上而言,DB对基于像素分割的文本检测方法提供了一个很好的算法框架,解决了此类算法阈值配置的难题,同时又有较好的兼容性--开发者可以针对场景难点对backbone进行改造优化,达到一个较好的性能和精度的平衡。

图5. DB网络结构
基于像素分割的算法能精准地预测出任意形状的文本实例,然后对于重叠文本区域,很难能将不同实例区分开来。要真正将该系列算法落地,满足业务需求,未来需解决重叠文本的问题。
Reference
[1]. Deng D, Liu H, Li X, et al. Pixellink: Detecting scene text via instance segmentation[C] //Proceedings of the AAAI Conference on Artificial Intelligence. 2018, 32(1).
[2]. Long S, Ruan J, Zhang W, et al. Textsnake: A flexible representation for detecting text of arbitrary shapes[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 20-36.
[3]. Baek Y, Lee B, Han D, et al. Character region awareness for text detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 9365-9374.
[4]. Wang W, Xie E, Li X, et al. Shape robust text detection with progressive scale expansion network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 9336-9345.
[5]. Wang W, Xie E, Song X, et al. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 8440-8449.
[6]. Xue C, Lu S, Zhang W. Msr: Multi-scale shape regression for scene text detection[J]. arXiv preprint arXiv:1901.02596, 2019.
[7]. Liao M, Wan Z, Yao C, et al. Real-time scene text detection with differentiable binarization[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(07): 11474-11481.
点击关注,第一时间了解华为云新鲜技术~
这篇关于带你了解弯曲文本检测算法的两种思路:区域重组和像素分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






