本文主要是介绍AMD GPU 内核驱动分析(三)-gpu scheduler ring fence同步工作模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在Linux Kernel 的AMDGPU驱动实现中,dma-fence扮演着重要角色,AMDGPU的Render/解码操作可能涉及到多个方面同时引用buffer的情况,以渲染/视频解码场景为例,应用将渲染/解码命令写入和GPU共享的BUFFER之后,需要将任务提交给GPU的运行队列等待执行,这个时候,应用不仅要监听buffer中任务的执行情况,还要保证在任务执行完毕之前,不能再去修改BUFFER中的数据。而AMDGPU也需要排它性地执行BUFFER命令。在GPU执行结束,应用希望及时得到执行完的信息,以便回收BUFFER重新利用,通知一般由绑定到某个BUFFER上的中断完成。这些操作,如果使用经典的共享BUFFER+锁的方式进行保护和同步,不但效率十分低下,而且各类内核机制杂糅在一起,缺乏一个统一的管理框架,使代码难以维护。 dma-fence则提供了一套简单便捷的机框架,将原子操作,休眠唤醒,同步/异步事件通知等功能嵌入到各种类型的BUFFER管理框架中,将各类机制有机的结合在一起,减少了用户态空间的忙等,使buffer使用更加智能高效。
以AMDGPU解码视频为例,利用dma-fence ring buffer隔离了应用解码请求和解码任务任务本身,提交任务和解码完成通知均通过BUFFER绑定的dma-fence进行交互:
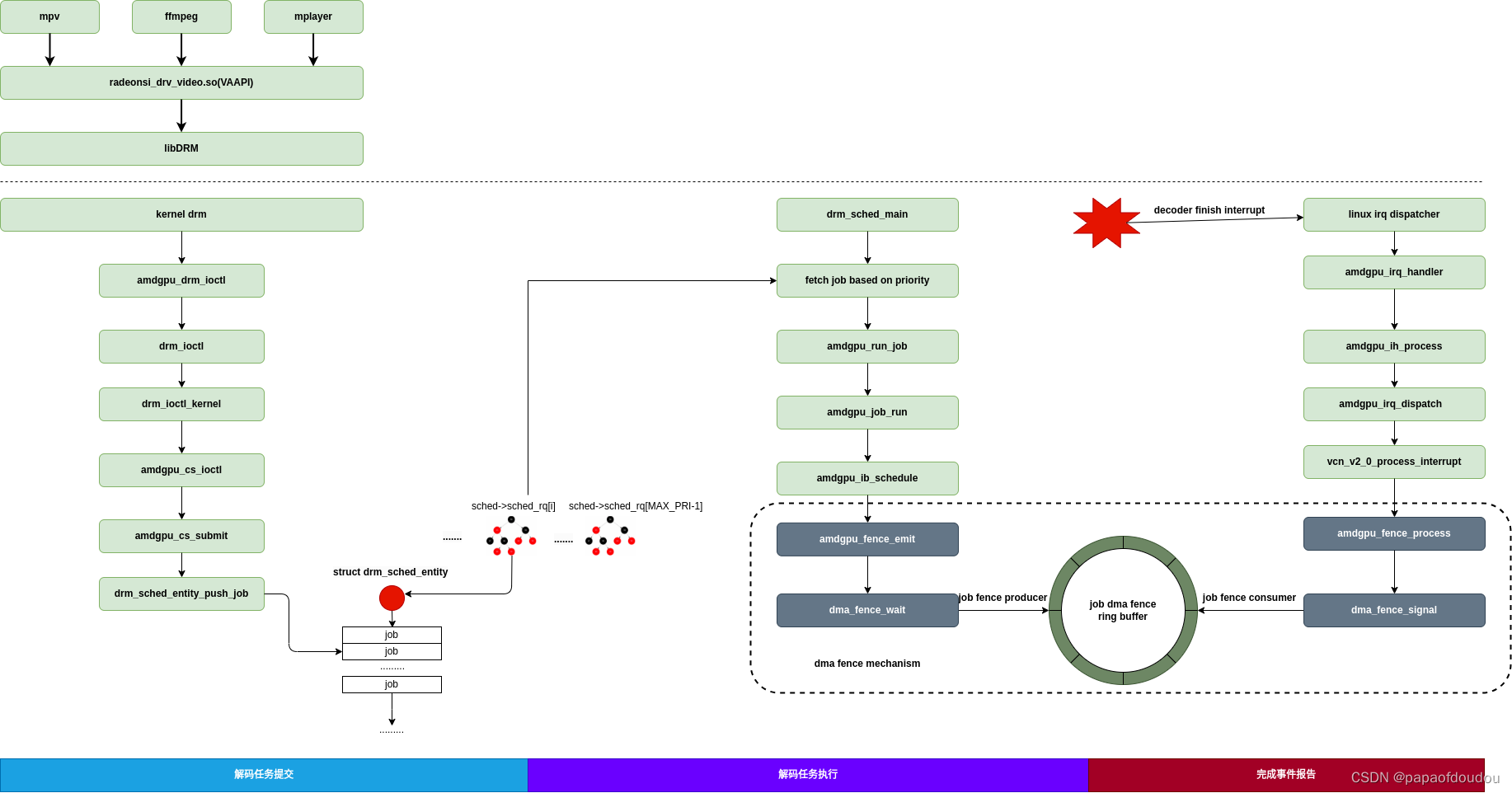
为了便于分析,我把5.4内核中AMDGPU这部分的实现提取出来,写了一个可以独立加载执行的内核模块demo,类似于CMODEL,任务提交上下文和解码完成通知上下文在AMDGPU驱动中分别用内核线程和中断实现,在demo中则全部用内核线程实现.
工作模型如下图所示:

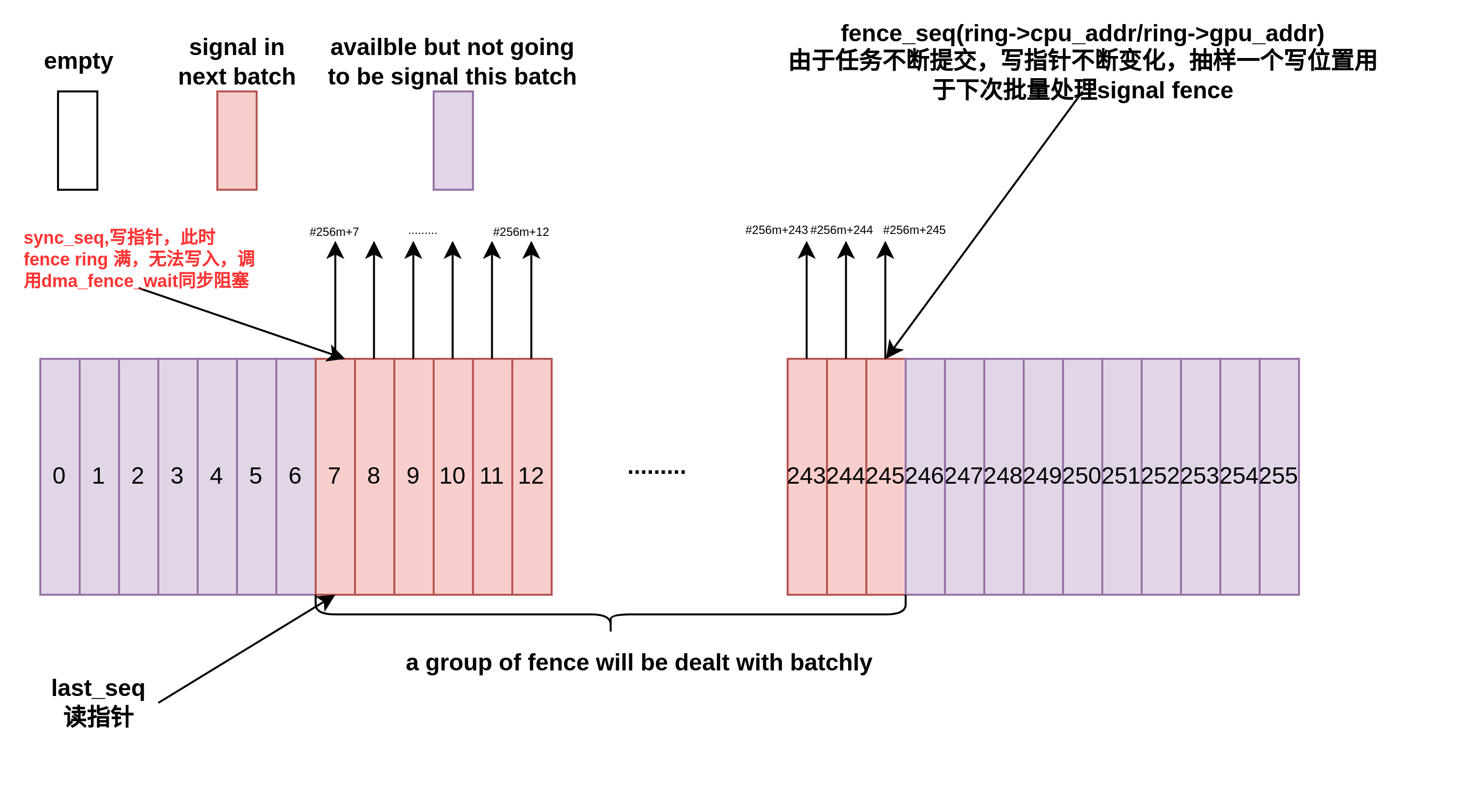
fence array有256个slot,每个位置代表一个fence.构成一个RING BUFFER。sync_seq为写指针序号,sync_seq只增不减,sync_seq mod 256为在array中的index,相当于RING BUFFER的写指针。
last_seq代表当前已经消耗掉结束位置(已完成处理的和fence绑定的buffer)的序号,同sync_seq一样,它也是单调递增的自然序列,last_seq mod 256 为在array中的index,相当于ring buffer的读指针。
而fence_seq则表示写位置的一个抽样,这是一个在AMDGPU中的hardware ring是所有进程共享的,每个进程随时可能会提交新的渲染任务,所以sync_seq时刻在更新,不适合处理。fence_seq则是某个时间点的快照,在last_seq和fence_seq之间的buffer(fence),都会在下一批中一并得到signal.
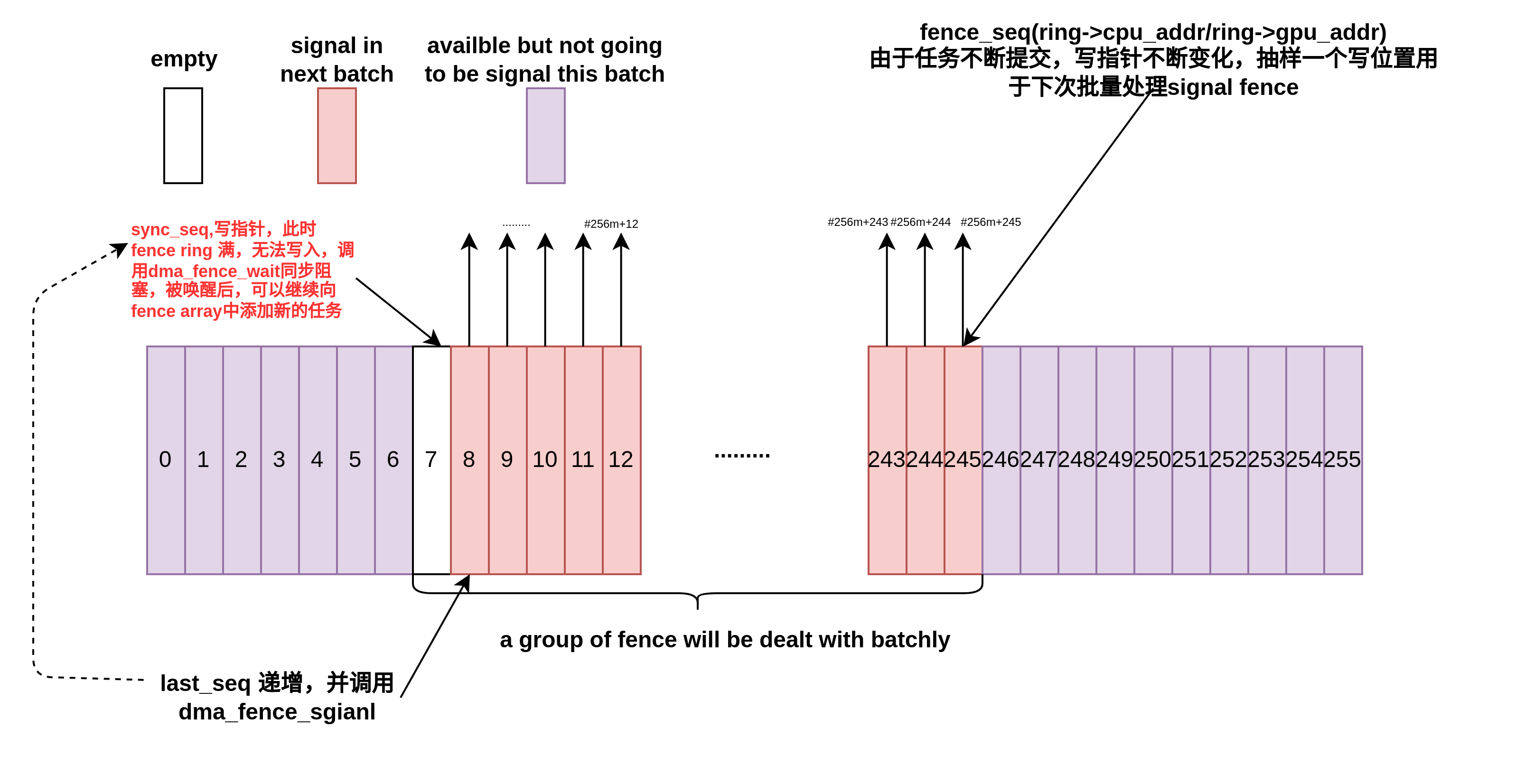
当提交过快,但是消耗较慢时,写方追上读方,此时需要进行生产-消费之间的同步,读端将会反压到写端,写端调用dma_fence_wait进行同步:
当消费方完成下一个任务后,释放当前slot,并且调用dma_fence_signal唤醒写线程,写线程受到信号后,继续执行,向fence array中填充新的任务:
dma fence 的free
拔出萝卜带出泥,通过job fence的free触发schedule fence和finish fence的释放,释放是通过引用计数归零触发的回调,在回调用中利用RCU异步释放FENCE占用的空间。


以上就是fence array的使用过程中的几个corner case.
AMDGPU中gpu_sched的TRACE Point
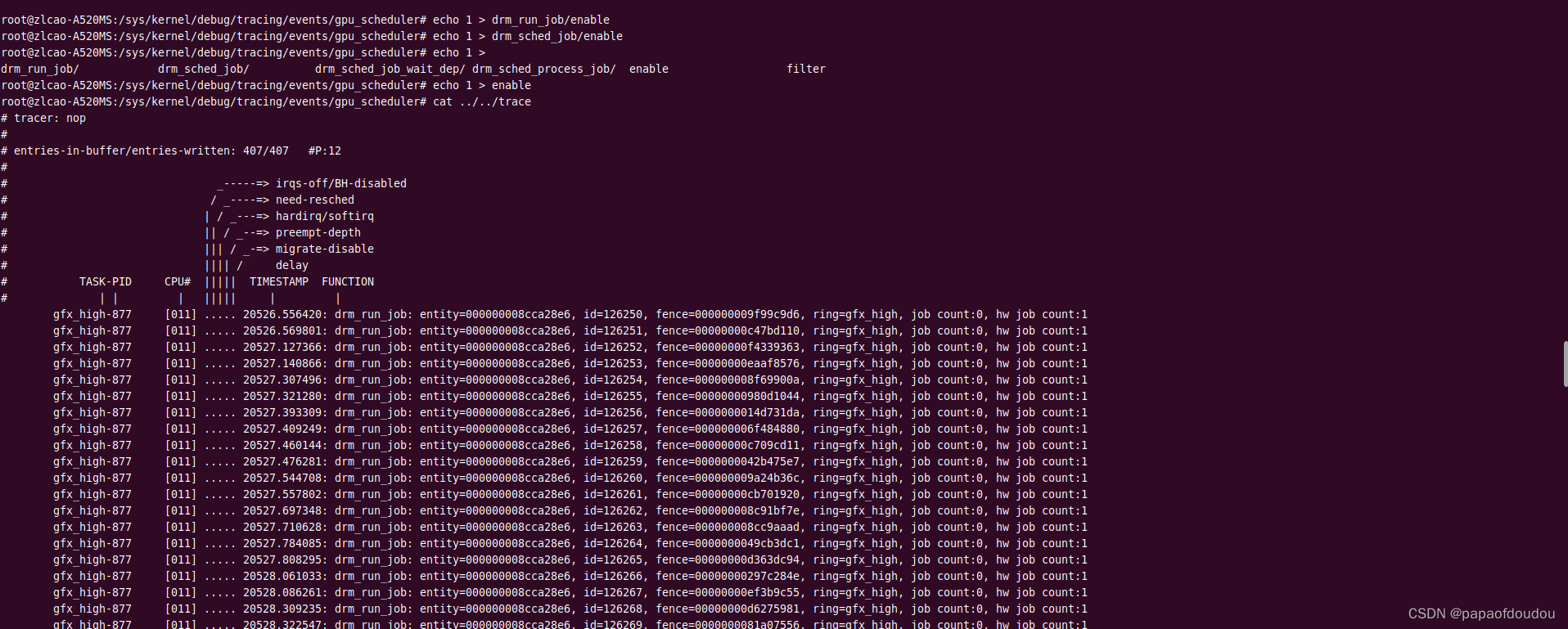
Linux 内核调试框架提供了GPU调度器的trace event功能,可以在不重新编译模块的情况下,追踪GPU的执行情况,路径如下:
/sys/kernel/debug/tracing/events/gpu_scheduler
trace结果:
root@zlcao-A520MS:/sys/kernel/debug/tracing/events/gpu_scheduler# echo 1 > drm_run_job/enable
root@zlcao-A520MS:/sys/kernel/debug/tracing/events/gpu_scheduler# echo 1 > drm_sched_job/enable
root@zlcao-A520MS:/sys/kernel/debug/tracing/events/gpu_scheduler# echo 1 >
drm_run_job/ drm_sched_job/ drm_sched_job_wait_dep/ drm_sched_process_job/ enable filter
root@zlcao-A520MS:/sys/kernel/debug/tracing/events/gpu_scheduler# echo 1 > enable
root@zlcao-A520MS:/sys/kernel/debug/tracing/events/gpu_scheduler# cat ../../trace
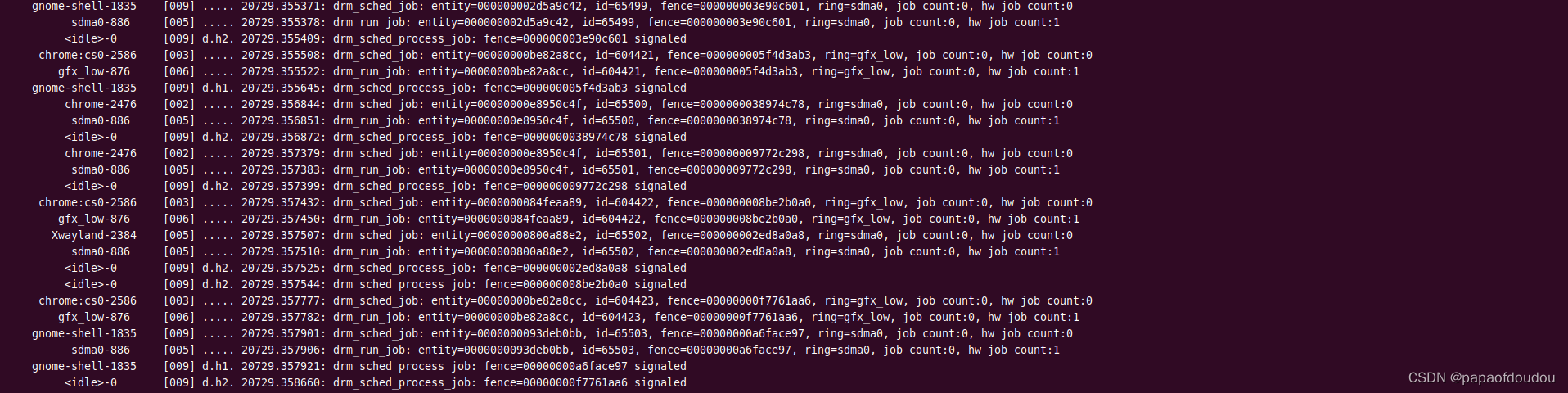
fence 流量控制
ring结构体中包含一个名子为num_hw_submission的字段,fence array的空间是就是根据其两倍大小来分配的。
这个变量最早由amdgpu.ko的amdgpu_sched_hw_submission参数传入,AMDGPU驱动会根据RINT的类型再做进一步的调整。

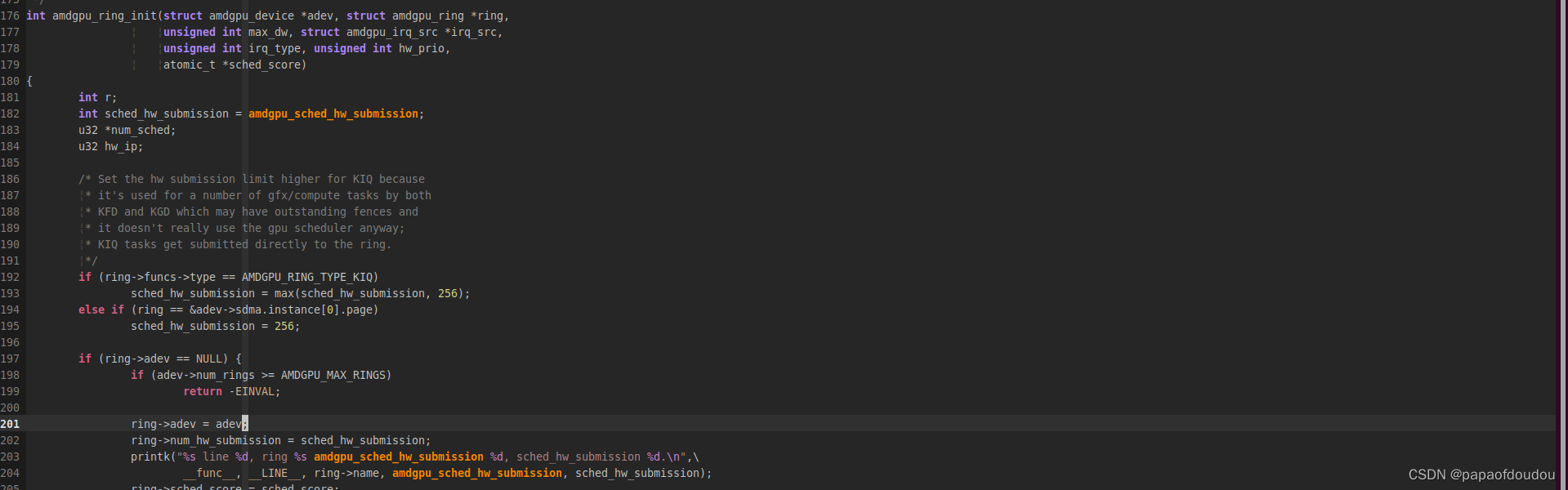
之后在创建调度线程时传递给sched->hw_submission_limit变量,.如果当前RING上发射出去的正在执行的job packet的数量小于sched->hw_submission_limit时,提交JOB的上向文将会对RING调度内核线程执行唤醒操作。通过这种方式对RING中的执行情况进行流量控制。
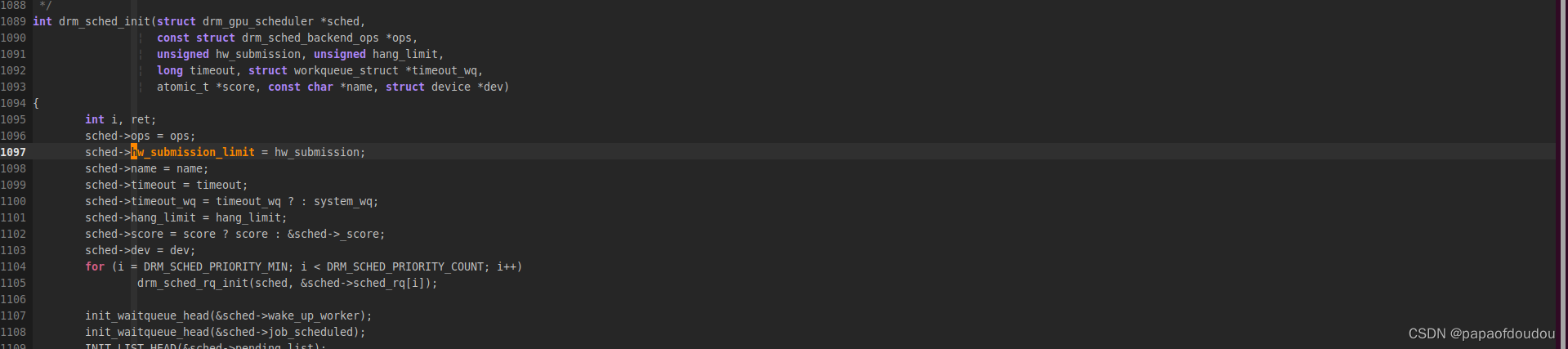

只有KIQ Ring的submission 数目最大,达到了256,原因前图注释已经说明,可能是因为在其上运行的COMMAND数量大。

ubuntu图形界面常态工作时,AMDGPU ring的负载情况:
在运行UBUNTU图形终端时,AMDGPU主要有三个RING在执行任务,包含gfx_low/high, sdma,gfx ring负责执行具体的渲染命令,而sdma则负责数据拷贝。
KFD Ring和GFX Ring的处理方式区别
KFD ring是支持compute的ring类型,它是用户台提交command packet的,所以不依赖于内核态gpu scheduler.而gfx ring则需要。
> HI flix:
> It seems the HSA KFD Driver are live in the DRM frameworkm, which
> is like the AMD Graphc drivers. But it seems the Graphic Drivers are
> free to KFD, because the GPU Graphic function are running well if
> CONFIG_HSA_AMD macro disable the KFD functions.
>
> but did the KFD driver needs the Drm drivers? *without the DRM
> Framework, did the KFD driver work normally? *
> and another question,*did the gpu_sched module is share for Graphici
> driver and KFD? or* it just use for Graphic Drivers.
>
> i am not familar the AMD GPU driver but i am very intrested on it when
> i found it, thanks very much for your kindly help on my misunderstading.
>
The AMDGPU driver is a unified driver that supports both graphics and
compute functionality on a wide range of AMD GPUs. You can think of KFD
as an extension to AMDGPU to support ROCm user mode (HIP, OpenMP,
PyTorch, Tensorflow, etc.). ROCm user mode still depends on some of the
DRM functionality. So KFD cannot exist as a standalone driver without
AMDGPU and DRM.KFD does not use the gpu_sched scheduler. It is only used by the
graphics driver. Instead it relies on user-mode-queues, where user mode
places command directly into memory-mapped queues that are executed by
the firmware on the GPU. We do not use a driver ioctl API for command
submission, so we don't use the gpu_sched scheduler. Instead the user
mode compute queues are scheduled by the GPU firmware.附模块code:
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/types.h>
#include <linux/spinlock.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/mm.h>
#include <linux/sched/signal.h>
#include <linux/dma-fence.h>
#include <linux/slab.h>
#include <linux/delay.h>
#include <linux/kthread.h>
#include <linux/sched.h>
#include <uapi/linux/sched/types.h>#define assert(expr) \if (!(expr)) { \printk( "Assertion failed! %s,%s,%s,line=%d\n",\#expr,__FILE__,__func__,__LINE__); \BUG(); \}#define num_hw_submission 128
struct fence_driver {uint64_t gpu_addr;volatile uint32_t *cpu_addr;uint32_t sync_seq;atomic_t last_seq;bool initialized;bool initialized_emit;bool initialized_recv;unsigned num_fences_mask;spinlock_t lock;struct dma_fence **fences;struct mutex mutex;struct dma_fence *last_fence;struct timer_list timer;struct timer_list work_timer;wait_queue_head_t job_scheduled;
};struct fence_set {struct dma_fence scheduled;struct dma_fence finished;spinlock_t lock;
};struct job_fence {struct dma_fence job;void *data;
};static uint32_t fence_seq;
static struct fence_driver *ring;
static struct task_struct *fence_emit_task;
static struct task_struct *fence_recv_task;
static struct kmem_cache *job_fence_slab;
static struct kmem_cache *sched_fence_slab;static const char *dma_fence_get_name(struct dma_fence *fence)
{return "dma-fence-drv";
}static bool dma_fence_enable_signal(struct dma_fence *fence)
{if (!timer_pending(&ring->work_timer)) {mod_timer(&ring->work_timer, jiffies + HZ / 10);}printk("%s line %d, signal fenceno %lld.\n", __func__, __LINE__, fence->seqno);return true;
}void fencedrv_fence_free(struct rcu_head *rcu)
{struct fence_set *fs;struct dma_fence *f = container_of(rcu, struct dma_fence, rcu);struct job_fence *jb = container_of(f, struct job_fence, job);assert(jb->data != NULL);fs = (struct fence_set *)jb->data;// the dma_fence_get must be symmentry with dma_fence_put during all the alive.assert((kref_read(&fs->scheduled.refcount) == 1));assert((kref_read(&fs->finished.refcount) == 1));//dma_fence_put(&fs->scheduled);dma_fence_put(&fs->finished);kmem_cache_free(job_fence_slab, jb);// dump_stack();
}static void fencedrv_dma_fence_release(struct dma_fence *fence)
{// typically usage for dma fence release by rcu.call_rcu(&fence->rcu, fencedrv_fence_free);
}static const struct dma_fence_ops fence_ops = {.get_driver_name = dma_fence_get_name,.get_timeline_name = dma_fence_get_name,.enable_signaling = dma_fence_enable_signal,.release = fencedrv_dma_fence_release,
};static int32_t fencedrv_get_ring_avail(void)
{uint32_t read_seq, write_seq;do {read_seq = atomic_read(&ring->last_seq);write_seq = ring->sync_seq;} while (atomic_read(&ring->last_seq) != read_seq);read_seq &= ring->num_fences_mask;write_seq &= ring->num_fences_mask;pr_err("%s line %d, read_seq %d, write_seq %d.\n",__func__, __LINE__, read_seq, write_seq);if (read_seq <= write_seq) {return write_seq - read_seq;} else {return write_seq + num_hw_submission * 2 - read_seq;}
}static const char *dma_fence_get_name_scheduled(struct dma_fence *fence)
{return "dma-fence-scheduled";
}static const char *dma_fence_get_name_finished(struct dma_fence *fence)
{return "dma-fence-finished";
}static void sched_fence_free(struct rcu_head *head);
static void fencedrv_dma_fence_release_scheduled(struct dma_fence *fence)
{struct fence_set *fs = container_of(fence, struct fence_set, scheduled);// typically usage for dma fence release by rcu.call_rcu(&fs->finished.rcu, sched_fence_free);
}static void fencedrv_dma_fence_release_finished(struct dma_fence *fence)
{struct fence_set *fs = container_of(fence, struct fence_set, finished);dma_fence_put(&fs->scheduled);//while (1);
}static const struct dma_fence_ops fence_scheduled_ops = {.get_driver_name = dma_fence_get_name_scheduled,.get_timeline_name = dma_fence_get_name_scheduled,.release = fencedrv_dma_fence_release_scheduled,
};static const struct dma_fence_ops fence_finished_ops = {.get_driver_name = dma_fence_get_name_finished,.get_timeline_name = dma_fence_get_name_finished,.release = fencedrv_dma_fence_release_finished,
};static struct fence_set *to_sched_fence(struct dma_fence *f)
{if (f->ops == &fence_scheduled_ops) {return container_of(f, struct fence_set, scheduled);}if (f->ops == &fence_finished_ops) {return container_of(f, struct fence_set, finished);}return NULL;
}static void sched_fence_free(struct rcu_head *head)
{struct dma_fence *f = container_of(head, struct dma_fence, rcu);struct fence_set *fs = to_sched_fence(f);if (fs == NULL)return;assert(f == &fs->finished);kmem_cache_free(sched_fence_slab, fs);dump_stack();
}static struct fence_set *init_fence_set(void)
{struct fence_set *fs = kmem_cache_alloc(sched_fence_slab, GFP_KERNEL);if (fs == NULL) {pr_err("%s line %d, alloc fence set from fence set slab failure.\n",__func__, __LINE__);return NULL;}spin_lock_init(&fs->lock);dma_fence_init(&fs->scheduled, &fence_scheduled_ops, &fs->lock, 0, 0);dma_fence_init(&fs->finished, &fence_finished_ops, &fs->lock, 0, 0);return fs;
}// ref amdgpu_fence_process
static int fence_recv_task_thread(void *data)
{struct sched_param sparam = {.sched_priority = 1};sched_setscheduler(current, SCHED_FIFO, &sparam);//mutex_lock(&ring->mutex);while (ring->initialized == false) {set_current_state(TASK_UNINTERRUPTIBLE);if (ring->initialized == true) {break;}//mutex_unlock(&ring->mutex);schedule();//mutex_lock(&ring->mutex);}set_current_state(TASK_RUNNING);//mutex_unlock(&ring->mutex);while (!kthread_should_stop() && ring->initialized_recv == true) {uint32_t seqno_next = 0;uint32_t seq, last_seq;int r;do {// last_seq is the read pointer of fence ring buffer.last_seq = atomic_read(&ring->last_seq);seq = *ring->cpu_addr;if (kthread_should_stop())return 0;} while (atomic_cmpxchg(&ring->last_seq, last_seq, seq) != last_seq);if (del_timer(&ring->work_timer) &&seq != ring->sync_seq) {mod_timer(&ring->work_timer, jiffies + HZ / 10);}//printk("%s line %d, last_seq %d, seq %d, sync_seq %d.\n", __func__, __LINE__, last_seq, seq, ring->sync_seq);if (unlikely(seq == last_seq)) {msleep(10);continue;}assert(seq > last_seq);last_seq &= ring->num_fences_mask;seq &= ring->num_fences_mask;//printk("%s line %d, last_seq %d, seq %d, sync_seq %d.\n", __func__, __LINE__, last_seq, seq, ring->sync_seq);do {struct dma_fence *fence, **ptr;++last_seq;last_seq &= ring->num_fences_mask;ptr = &ring->fences[last_seq];fence = rcu_dereference_protected(*ptr, 1);RCU_INIT_POINTER(*ptr, NULL);if (!fence) {continue;}if (seqno_next == 0 || seqno_next == fence->seqno) {seqno_next = fence->seqno + 1;} else { /*if (seqno_next != 0 && seqno_next != fence->seqno)*/pr_err("%s line %d, seqno is not continue, exptect %d, actual %lld.\n",__func__, __LINE__, seqno_next, fence->seqno);}printk("%s line %d, last_seq/slot %d, seq %d, signal %lld.\n",__func__, __LINE__, last_seq, seq, fence->seqno);if (list_empty(&fence->cb_list)) {printk("%s line %d, fence cb list is empty.\n",__func__, __LINE__);} else {printk("%s line %d, fence cb list is not empty.\n",__func__, __LINE__);}r = dma_fence_signal(fence);if (kthread_should_stop()) {dma_fence_put(fence);return 0;}if (r) {pr_err("%s line %d, fence already signaled.\n",__func__, __LINE__);continue;//BUG();}dma_fence_put(fence);} while (last_seq != seq);wake_up(&ring->job_scheduled);}set_current_state(TASK_RUNNING);return 0;
}// ref amdgpu_fence_emit.
static int fence_emit_task_thread(void *data)
{int r;uint64_t oldwaitseqno = 0;struct sched_param sparam = {.sched_priority = 1};sched_setscheduler(current, SCHED_FIFO, &sparam);//mutex_lock(&ring->mutex);while (ring->initialized == false) {set_current_state(TASK_UNINTERRUPTIBLE);if (ring->initialized == true) {break;}//mutex_unlock(&ring->mutex);schedule();//mutex_lock(&ring->mutex);}set_current_state(TASK_RUNNING);//mutex_unlock(&ring->mutex);while (!kthread_should_stop() && ring->initialized_emit == true) {
#if 0msleep(1000);printk("%s line %d.\n", __func__, __LINE__);
#elsestruct dma_fence __rcu **ptr;struct job_fence *fence;uint32_t seq;struct fence_set *fs = init_fence_set();fence = kmem_cache_alloc(job_fence_slab, GFP_KERNEL);if (fence == NULL) {pr_err("%s line %d, alloc fence from fence slab failure.\n",__func__, __LINE__);return -1;}// ring->sync_seq is fence ring write pointer.seq = ++ring->sync_seq;dma_fence_init(&fence->job, &fence_ops, &ring->lock, 0, seq);fence->data = fs;ptr = &ring->fences[seq & ring->num_fences_mask];//printk("%s line %d, seq = %d.\n", __func__, __LINE__, seq);if (kthread_should_stop()) {// will call fence_ops.release directly to free the fence.dma_fence_put(&fence->job);continue;}if (unlikely(rcu_dereference_protected(*ptr, 1))) {struct dma_fence *old;int diff;rcu_read_lock();old = dma_fence_get_rcu_safe(ptr);rcu_read_unlock();if (old) {mutex_lock(&ring->mutex);//dma_fence_get(old);ring->last_fence = old;mutex_unlock(&ring->mutex);r = dma_fence_wait(old, false);mutex_lock(&ring->mutex);ring->last_fence = NULL;dma_fence_put(old);mutex_unlock(&ring->mutex);if (kthread_should_stop() || r) {// will call fence_ops.release directly to free the fence.dma_fence_put(&fence->job);continue;}// if overlap happened, there must be a congruences on seq and old->seqno,which means seq≡ old->seqno mod(num_hw_submission * 2)// this implies seq = q*(num_hw_submission * 2) + old->seqno. q=1 typically.diff = seq - old->seqno;printk("%s line %d, fence wokenup, wakeseqno %lld, new adding seq %d, slot %d, diff %d, waken interval %lld, latestseq %d, avail %d.\n",__func__, __LINE__, old->seqno, seq, seq & ring->num_fences_mask, diff, old->seqno - oldwaitseqno,ring->sync_seq, fencedrv_get_ring_avail());if (diff != num_hw_submission * 2) {pr_err("%s line %d, fatal error, diff not match totoal ring.\n",__func__, __LINE__);}oldwaitseqno = old->seqno;}}#if 0printk("%s line %d, fence emit, seqno %lld, seq %d, slot %d.\n",__func__, __LINE__, fence->seqno, seq, seq & ring->num_fences_mask);
#endifrcu_assign_pointer(*ptr, dma_fence_get(&fence->job));// because no outer usage of fence, so put it here for free ok.dma_fence_put(&fence->job);
#endif}set_current_state(TASK_RUNNING);return 0;
}void work_timer_fn(struct timer_list *timer)
{uint32_t seqno_next = 0;uint32_t seq, last_seq;int r;do {last_seq = atomic_read(&ring->last_seq);seq = *ring->cpu_addr;} while (atomic_cmpxchg(&ring->last_seq, last_seq, seq) != last_seq);if (unlikely(seq == last_seq)) {goto end;}assert(seq > last_seq);last_seq &= ring->num_fences_mask;seq &= ring->num_fences_mask;do {struct dma_fence *fence, **ptr;++last_seq;last_seq &= ring->num_fences_mask;ptr = &ring->fences[last_seq];fence = rcu_dereference_protected(*ptr, 1);RCU_INIT_POINTER(*ptr, NULL);if (!fence) {continue;}if (seqno_next == 0 || seqno_next == fence->seqno) {seqno_next = fence->seqno + 1;} else { /*if (seqno_next != 0 && seqno_next != fence->seqno)*/pr_err("%s line %d, seqno is not continue, exptect %d, actual %lld.\n",__func__, __LINE__, seqno_next, fence->seqno);}r = dma_fence_signal(fence);if (r) {pr_err("%s line %d, fence already signaled.\n",__func__, __LINE__);continue;//BUG();}dma_fence_put(fence);} while (last_seq != seq);
end:pr_err("%s line %d, work timer triggerd.\n", __func__, __LINE__);mod_timer(timer, jiffies + HZ / 10);
}void gpu_process_thread(struct timer_list *timer)
{uint32_t seq, oldseq;seq = ring->sync_seq;oldseq = fence_seq;// trigger a job done on device.if (fence_seq == 0) {if (seq > 6)fence_seq = seq - 4;} else if ((seq - fence_seq) > 10) {fence_seq += (seq - fence_seq) / 2;assert(fence_seq > oldseq);}printk("%s line %d, timer trigger job, latest consume fence %d.\n",__func__, __LINE__, fence_seq);mod_timer(timer, jiffies + HZ / 2);
}static int fencedrv_wait_empty(void)
{uint64_t seq = READ_ONCE(ring->sync_seq);struct dma_fence *fence, **ptr;int r;if (!seq)return 0;fence_seq = seq;ptr = &ring->fences[seq & ring->num_fences_mask];rcu_read_lock();fence = rcu_dereference(*ptr);if (!fence || !dma_fence_get_rcu(fence)) {rcu_read_unlock();return 0;}rcu_read_unlock();r = dma_fence_wait(fence, false);printk("%s line %d, wait last fence %lld, seq %lld, r %d.\n", \__func__, __LINE__, fence->seqno, seq, r);dma_fence_put(fence);return r;
}static int __init fencedrv_init(void)
{if ((num_hw_submission & (num_hw_submission - 1)) != 0) {pr_err("%s line %d, num_hw_submission must be power of two.\n",__func__, __LINE__);return -1;}ring = kzalloc(sizeof(*ring), GFP_KERNEL);if (ring == NULL) {pr_err("%s line %d, alloc fence driver failure.\n",__func__, __LINE__);return -ENOMEM;}// fence_seq is a snap shot of sync_seq for deal with fence batchlly.ring->cpu_addr = &fence_seq;ring->gpu_addr = (uint64_t)&fence_seq;ring->sync_seq = 0;atomic_set(&ring->last_seq, 0);ring->initialized = false;ring->initialized_emit = false;ring->initialized_recv = false;ring->last_fence = NULL;ring->num_fences_mask = num_hw_submission * 2 - 1;init_waitqueue_head(&ring->job_scheduled);spin_lock_init(&ring->lock);ring->fences = kcalloc(num_hw_submission * 2, sizeof(void *), GFP_KERNEL);if (!ring->fences) {pr_err("%s line %d, alloc fence buffer failure.\n",__func__, __LINE__);return -ENOMEM;}printk("%s line %d, fence mask 0x%x, num_hw_submission 0x%x.\n",__func__, __LINE__, ring->num_fences_mask, num_hw_submission);job_fence_slab = kmem_cache_create("job_fence_slab", sizeof(struct job_fence), 0,SLAB_HWCACHE_ALIGN, NULL);if (!job_fence_slab) {pr_err("%s line %d, alloc job_fence_slab falure.\n",__func__, __LINE__);return -ENOMEM;}sched_fence_slab = kmem_cache_create("sched_fence_slab", sizeof(struct fence_set), 0,SLAB_HWCACHE_ALIGN, NULL);if (!sched_fence_slab) {pr_err("%s line %d, alloc sched_fence_slab falure.\n",__func__, __LINE__);return -ENOMEM;}mutex_init(&ring->mutex);fence_emit_task = kthread_run(fence_emit_task_thread, NULL, "fence_emit");if (IS_ERR(fence_emit_task)) {pr_err("%s line %d, create fence emit tsk failure.\n",__func__, __LINE__);return -1;}fence_recv_task = kthread_run(fence_recv_task_thread, NULL, "fence_recv");if (IS_ERR(fence_recv_task)) {pr_err("%s line %d, create fence recv tsk failure.\n",__func__, __LINE__);return -1;}timer_setup(&ring->timer, gpu_process_thread, TIMER_IRQSAFE);add_timer(&ring->timer);mod_timer(&ring->timer, jiffies + HZ / 2);timer_setup(&ring->work_timer, work_timer_fn, TIMER_IRQSAFE);add_timer(&ring->work_timer);mod_timer(&ring->work_timer, jiffies + HZ / 10);printk("%s line %d, module init.\n", __func__, __LINE__);ring->initialized = true;ring->initialized_emit = true;ring->initialized_recv = true;wake_up_process(fence_emit_task);wake_up_process(fence_recv_task);return 0;
}static void __exit fencedrv_exit(void)
{printk("%s line %d, module unload task begin.\n", __func__, __LINE__);del_timer_sync(&ring->work_timer);mutex_lock(&ring->mutex);if ((ring->last_fence != NULL) &&(!test_bit(DMA_FENCE_FLAG_SIGNALED_BIT, &ring->last_fence->flags))) {ring->initialized_emit = false;dma_fence_signal(ring->last_fence);dma_fence_put(ring->last_fence);}mutex_unlock(&ring->mutex);kthread_stop(fence_emit_task);printk("%s line %d, module unload task mid.\n", __func__, __LINE__);del_timer_sync(&ring->timer);fencedrv_wait_empty();printk("%s line %d, sync wait avail %d.\n", __func__, __LINE__, fencedrv_get_ring_avail());wait_event_killable(ring->job_scheduled, fencedrv_get_ring_avail() <= 1);ring->initialized_recv = false;kthread_stop(fence_recv_task);printk("%s line %d, module unload task end.\n", __func__, __LINE__);ring->initialized = false;rcu_barrier();kmem_cache_destroy(job_fence_slab);kmem_cache_destroy(sched_fence_slab);kfree(ring->fences);kfree(ring);fence_emit_task = NULL;fence_recv_task = NULL;printk("%s line %d, module unload.\n", __func__, __LINE__);
}module_init(fencedrv_init);
module_exit(fencedrv_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("czl");参考博客
Fence_dma fence_笔落梦昙的博客-CSDN博客
结束
这篇关于AMD GPU 内核驱动分析(三)-gpu scheduler ring fence同步工作模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







