本文主要是介绍文心一言 VS 讯飞星火 VS chatgpt (119)-- 算法导论10.3 4题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
四、用go语言,我们往往希望双向链表的所有元素在存储器中保持紧凑,例如,在多数组表示中占用前m 个下标位置。(在页式虚拟存储的计算环境下,即为这种情况。)假设除指向链表本身的指针外没有其他指针指向该链表的元素,试说明如何实现过程ALLOCATE-OBIECT和 FREE-OBJECT,使得该表示保持紧凑。(提示:使用栈的数组实现。)
文心一言:
在Go语言中,我们可以使用一种称为"栈的数组"的结构来实现这种紧凑的存储。在这种表示中,数组的元素按照它们被分配的顺序存储,并且分配和释放操作都通过栈来进行,这样可以保证所有元素在存储器中保持紧凑。
首先,我们需要定义链表节点的数据结构,通常包含数据本身和指向下一个节点的指针。此外,为了便于实现,我们还需要一个栈来跟踪可用节点。
type Node struct { data int next *Node
} type Stack struct { top *Node len int
}
然后我们可以实现ALLOCATE-OBJECT和FREE-OBJECT过程。在ALLOCATE-OBJECT过程中,我们首先检查栈是否为空,如果为空,我们创建一个新的节点并将其推入栈中。否则,我们从栈顶弹出一个节点并将其数据设置为所需的值。在FREE-OBJECT过程中,我们将节点推入栈中以使其可供以后重新使用。
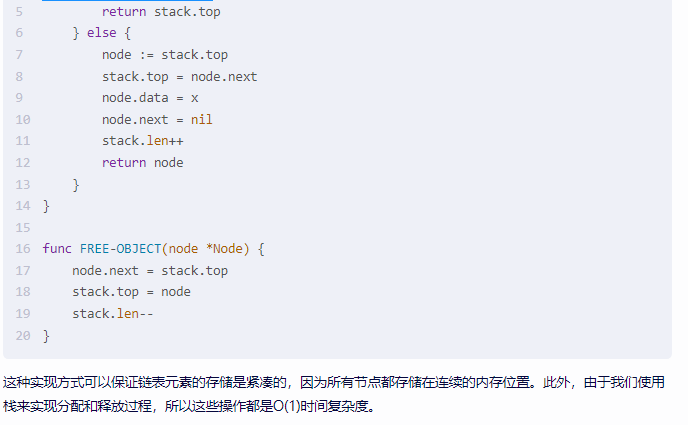
func ALLOCATE-OBJECT(x int) *Node { if stack.len == 0 { stack.top = &Node{data: x, next: nil} stack.len = 1 return stack.top } else { node := stack.top stack.top = node.next node.data = x node.next = nil stack.len++ return node }
} func FREE-OBJECT(node *Node) { node.next = stack.top stack.top = node stack.len--
}
这种实现方式可以保证链表元素的存储是紧凑的,因为所有节点都存储在连续的内存位置。此外,由于我们使用栈来实现分配和释放过程,所以这些操作都是O(1)时间复杂度。

讯飞星火:
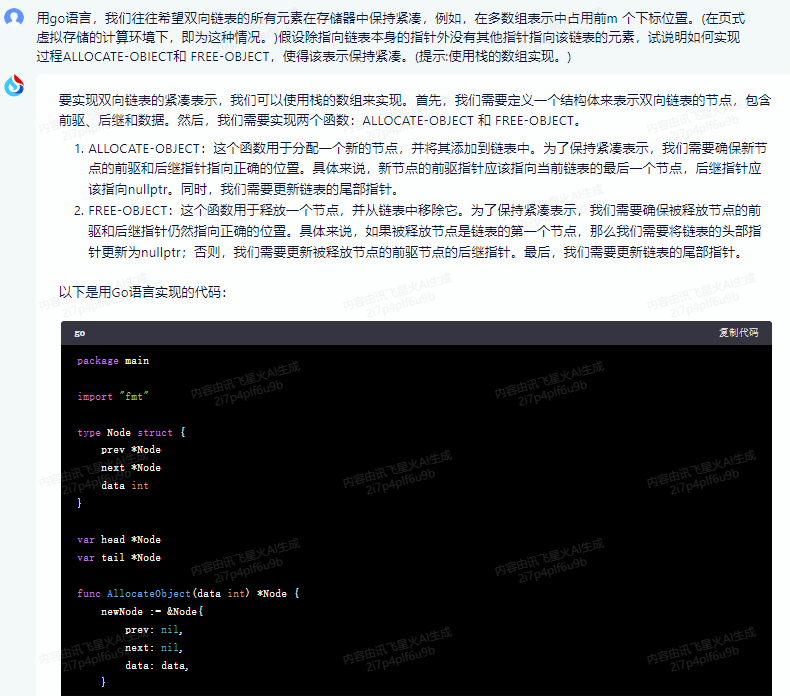
要实现双向链表的紧凑表示,我们可以使用栈的数组来实现。首先,我们需要定义一个结构体来表示双向链表的节点,包含前驱、后继和数据。然后,我们需要实现两个函数:ALLOCATE-OBJECT 和 FREE-OBJECT。
-
ALLOCATE-OBJECT:这个函数用于分配一个新的节点,并将其添加到链表中。为了保持紧凑表示,我们需要确保新节点的前驱和后继指针指向正确的位置。具体来说,新节点的前驱指针应该指向当前链表的最后一个节点,后继指针应该指向nullptr。同时,我们需要更新链表的尾部指针。
-
FREE-OBJECT:这个函数用于释放一个节点,并从链表中移除它。为了保持紧凑表示,我们需要确保被释放节点的前驱和后继指针仍然指向正确的位置。具体来说,如果被释放节点是链表的第一个节点,那么我们需要将链表的头部指针更新为nullptr;否则,我们需要更新被释放节点的前驱节点的后继指针。最后,我们需要更新链表的尾部指针。
以下是用Go语言实现的代码:
package mainimport "fmt"type Node struct {prev *Nodenext *Nodedata int
}var head *Node
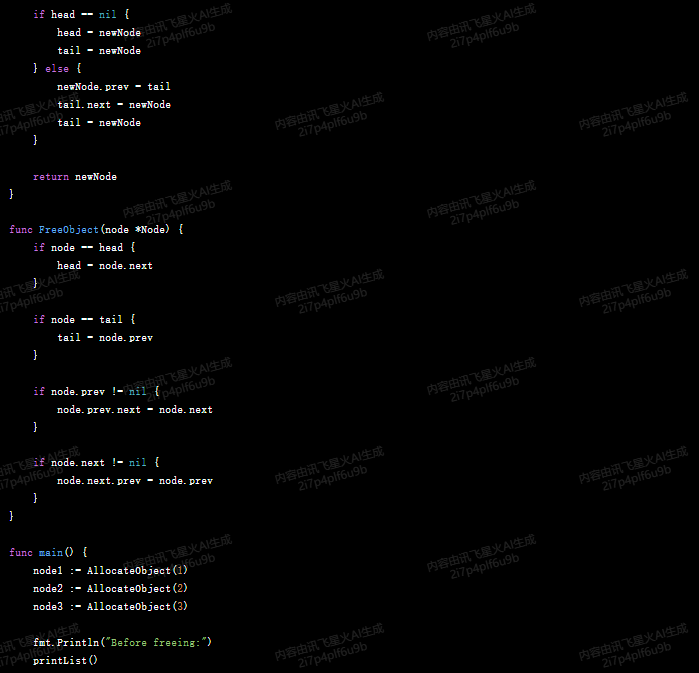
var tail *Nodefunc AllocateObject(data int) *Node {newNode := &Node{prev: nil,next: nil,data: data,}if head == nil {head = newNodetail = newNode} else {newNode.prev = tailtail.next = newNodetail = newNode}return newNode
}func FreeObject(node *Node) {if node == head {head = node.next}if node == tail {tail = node.prev}if node.prev != nil {node.prev.next = node.next}if node.next != nil {node.next.prev = node.prev}
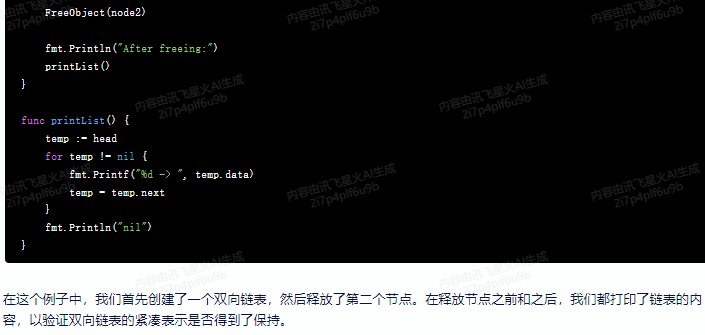
}func main() {node1 := AllocateObject(1)node2 := AllocateObject(2)node3 := AllocateObject(3)fmt.Println("Before freeing:")printList()FreeObject(node2)fmt.Println("After freeing:")printList()
}func printList() {temp := headfor temp != nil {fmt.Printf("%d -> ", temp.data)temp = temp.next}fmt.Println("nil")
}
在这个例子中,我们首先创建了一个双向链表,然后释放了第二个节点。在释放节点之前和之后,我们都打印了链表的内容,以验证双向链表的紧凑表示是否得到了保持。
360智脑:
这个问题涉及到内存分配和释放,以及栈的数组实现。在Go语言中,可以使用malloc和free函数进行内存的分配和释放。但是,使用malloc和free可能会导致内存碎片,影响程序的性能。因此,可以考虑使用栈的数组来实现内存的分配和释放。
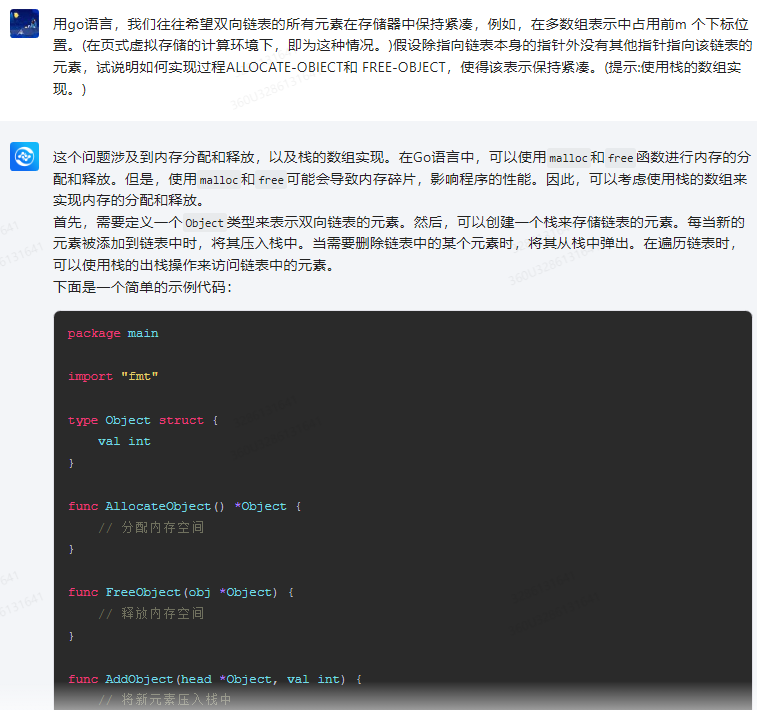
首先,需要定义一个Object类型来表示双向链表的元素。然后,可以创建一个栈来存储链表的元素。每当新的元素被添加到链表中时,将其压入栈中。当需要删除链表中的某个元素时,将其从栈中弹出。在遍历链表时,可以使用栈的出栈操作来访问链表中的元素。
下面是一个简单的示例代码:
package mainimport "fmt"type Object struct {val int
}func AllocateObject() *Object {// 分配内存空间
}func FreeObject(obj *Object) {// 释放内存空间
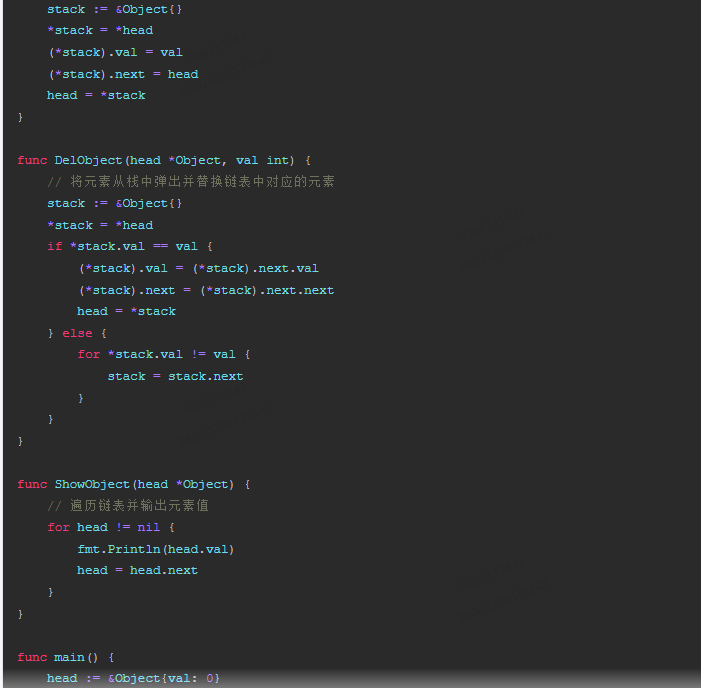
}func AddObject(head *Object, val int) {// 将新元素压入栈中stack := &Object{}*stack = *head(*stack).val = val(*stack).next = headhead = *stack
}func DelObject(head *Object, val int) {// 将元素从栈中弹出并替换链表中对应的元素stack := &Object{}*stack = *headif *stack.val == val {(*stack).val = (*stack).next.val(*stack).next = (*stack).next.nexthead = *stack} else {for *stack.val != val {stack = stack.next}}
}func ShowObject(head *Object) {// 遍历链表并输出元素值for head != nil {fmt.Println(head.val)head = head.next}
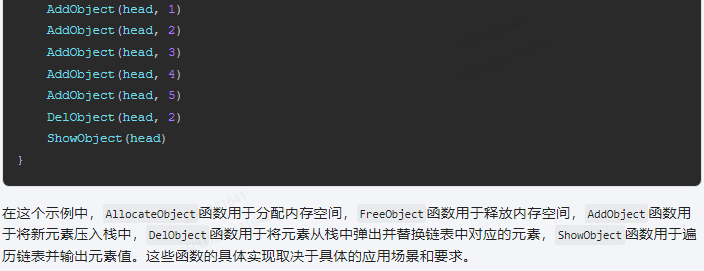
}func main() {head := &Object{val: 0}AddObject(head, 1)AddObject(head, 2)AddObject(head, 3)AddObject(head, 4)AddObject(head, 5)DelObject(head, 2)ShowObject(head)
}
在这个示例中,AllocateObject函数用于分配内存空间,FreeObject函数用于释放内存空间,AddObject函数用于将新元素压入栈中,DelObject函数用于将元素从栈中弹出并替换链表中对应的元素,ShowObject函数用于遍历链表并输出元素值。这些函数的具体实现取决于具体的应用场景和要求。
智谱清言:
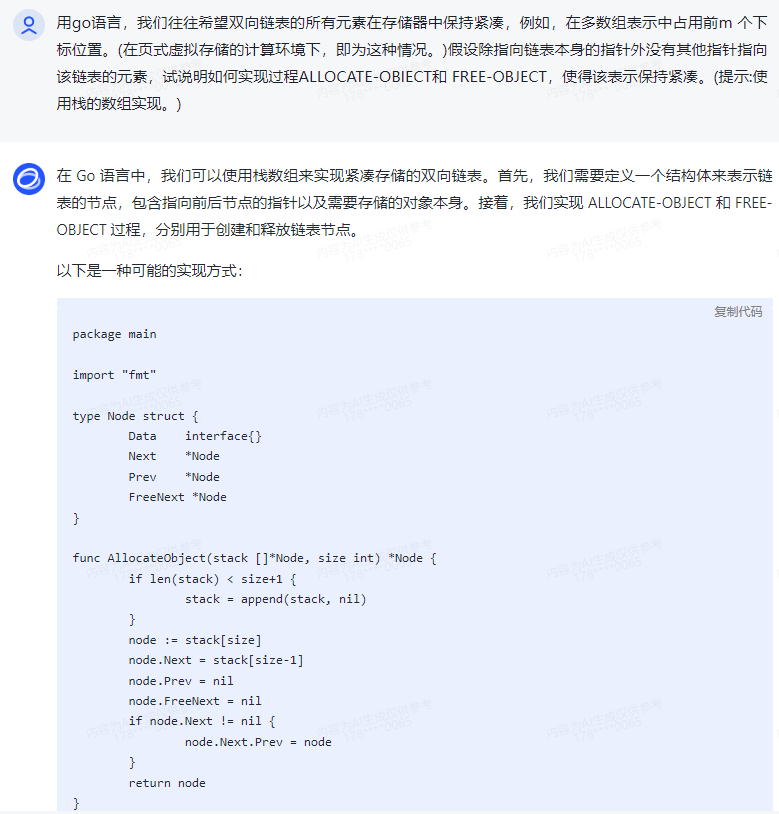
在 Go 语言中,我们可以使用栈数组来实现紧凑存储的双向链表。首先,我们需要定义一个结构体来表示链表的节点,包含指向前后节点的指针以及需要存储的对象本身。接着,我们实现 ALLOCATE-OBJECT 和 FREE-OBJECT 过程,分别用于创建和释放链表节点。
以下是一种可能的实现方式:
package main
import "fmt"
type Node struct { Data interface{} Next *Node Prev *Node FreeNext *Node
}
func AllocateObject(stack []*Node, size int) *Node { if len(stack) < size+1 { stack = append(stack, nil) } node := stack[size] node.Next = stack[size-1] node.Prev = nil node.FreeNext = nil if node.Next != nil { node.Next.Prev = node } return node
}
func FreeObject(stack []*Node, node *Node) { if node.Prev != nil { node.Prev.Next = node.Next } else { stack = stack[:len(stack)-1] } if node.Next != nil { node.Next.Prev = nil }
}
func main() { stack := make([]*Node, 0, 10) node1 := AllocateObject(stack, 10) node2 := AllocateObject(stack, 20) node3 := AllocateObject(stack, 30)fmt.Println("链表节点:", node1, node2, node3)FreeObject(stack, node2) fmt.Println("链表节点:", node1, node3)
}
在这个例子中,我们使用栈数组来存储链表的节点。当需要创建新的节点时,我们使用 AllocateObject 函数,将新节点插入到栈顶。当需要释放节点时,我们使用 FreeObject 函数,将节点从栈中移除。这样,链表的元素在存储器中保持紧凑。

通义千问:
在这个问题中,我们可以使用栈的数组来实现双向链表的分配和释放。首先,我们需要定义一个双向链表节点的数据结构:
type Node struct {Next *NodePrev *NodeData int
}
然后,我们可以定义一个栈的数组来存储双向链表的节点:
var stack [N]Node
其中,N是我们希望存储的节点的最大数量。
在ALLOCATE-OBJECT函数中,我们需要分配一个新的节点。首先,我们需要检查栈是否已满。如果已满,我们就返回一个错误。否则,我们就从栈顶弹出一个节点,然后将其数据字段设置为新的值,最后返回这个节点。
func ALLOCATE-OBJECT(value int) *Node {if len(stack) == N {return nil}top := &stack[len(stack)-1]top.Data = valuereturn top
}
在FREE-OBJECT函数中,我们需要释放一个节点。首先,我们需要找到这个节点,然后将其从栈中删除。如果这个节点没有前驱节点,我们就将栈顶节点的前驱指针设置为nil。如果这个节点没有后继节点,我们就将栈顶节点的后继指针设置为nil。
func FREE-OBJECT(node *Node) {if node.Prev != nil {node.Prev.Next = nil} else {stack[len(stack)-1].Next = nil}if node.Next != nil {node.Next.Prev = nil} else {stack[len(stack)-1].Prev = nil}stack[len(stack)-1] = *node
}
这样,我们就可以通过栈的数组实现双向链表的分配和释放,并保持链表的所有元素在存储器中保持紧凑。

天工:
在实现双向链表时,我们可以使用一个栈的数组来实现元素的存储和管理。栈的数组可以通过下标来访问元素,因此可以很好地保持元素在存储器中的紧凑表示。
具体来说,我们可以将每个元素表示为一个包含以下字段的结构体:
-
value:元素的值
-
prev:指向前一个元素的指针
-
next:指向后一个元素的指针
我们可以使用一个大小为n的栈的数组来存储这些元素,其中n是链表的长度。栈的数组的下标范围为[1, n],因为下标0用于表示链表的头部。
在实现ALLOCATE-OBJECT过程时,我们可以按照以下步骤进行:
1.检查栈的数组是否已满。如果已满,则返回一个错误。
2.分配一个新元素的空间,并将其初始化为一个新的双向链表节点。
3.将新节点的prev和next指针设置为相应的NULL值。
4.将新节点的值设置为输入参数value。
5.将新节点的下标设置为栈的数组的最后一个下标+1。
6.将新节点的prev指针设置为栈的数组中最后一个元素的next指针。
7.将新节点的next指针设置为NULL。
8.将栈的数组中最后一个元素的next指针设置为新节点。
9.返回新节点的下标。
在实现FREE-OBJECT过程时,我们可以按照以下步骤进行:
1.检查输入参数是否为NULL。如果是,则返回一个错误。
2.检查输入参数的下标是否在栈的数组的范围内。如果不是,则返回一个错误。
3.获取输入参数的前一个节点的指针prev和后一个节点的指针next。
4.将输入参数的prev指针设置为NULL,将输入参数的next指针设置为NULL。
5.将栈的数组中输入参数的下标处的元素的prev指针设置为输入参数的next指针。
6.将栈的数组中输入参数的下标处的元素的next指针设置为输入参数的prev指针。
7.返回输入参数的下标。
通过这种方式,我们可以在保持元素紧凑表示的同时,实现双向链表的所有操作。


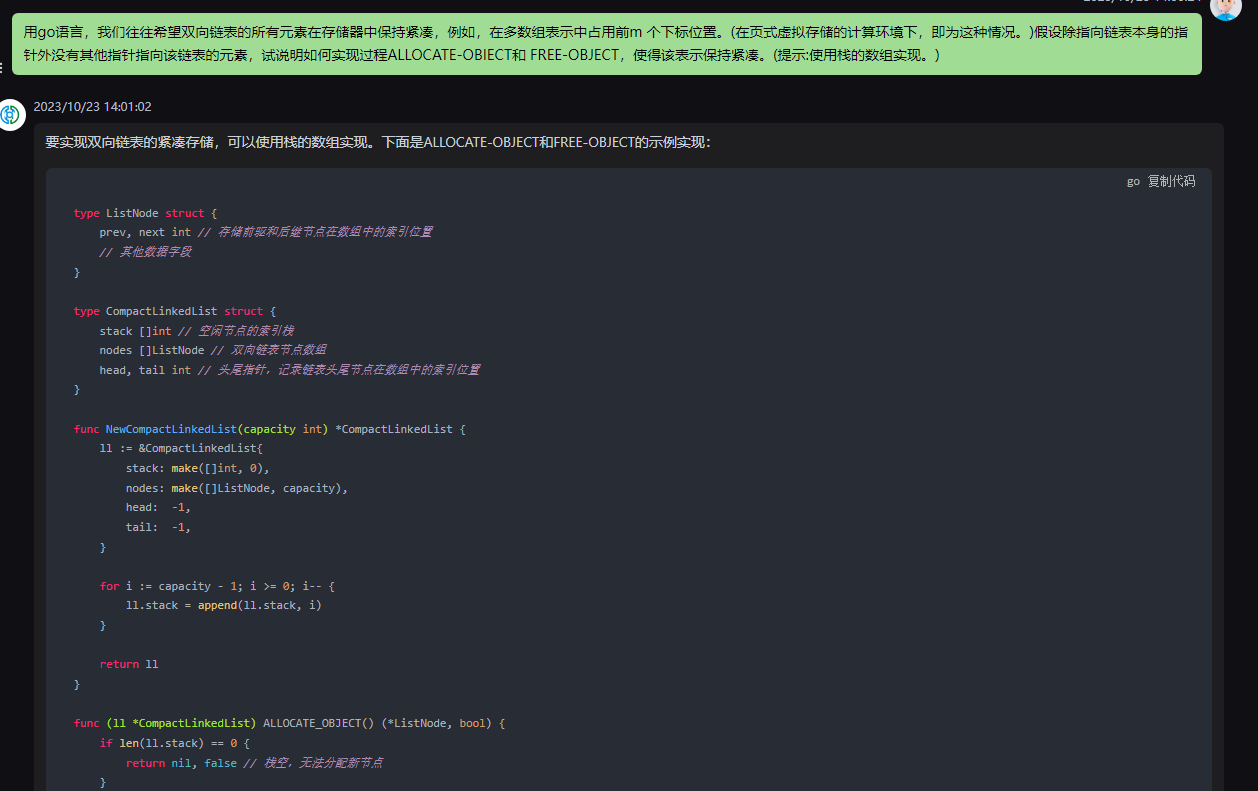
chatgpt:
要实现双向链表的紧凑存储,可以使用栈的数组实现。下面是ALLOCATE-OBJECT和FREE-OBJECT的示例实现:
type ListNode struct {prev, next int // 存储前驱和后继节点在数组中的索引位置// 其他数据字段
}type CompactLinkedList struct {stack []int // 空闲节点的索引栈nodes []ListNode // 双向链表节点数组head, tail int // 头尾指针,记录链表头尾节点在数组中的索引位置
}func NewCompactLinkedList(capacity int) *CompactLinkedList {ll := &CompactLinkedList{stack: make([]int, 0),nodes: make([]ListNode, capacity),head: -1,tail: -1,}for i := capacity - 1; i >= 0; i-- {ll.stack = append(ll.stack, i)}return ll
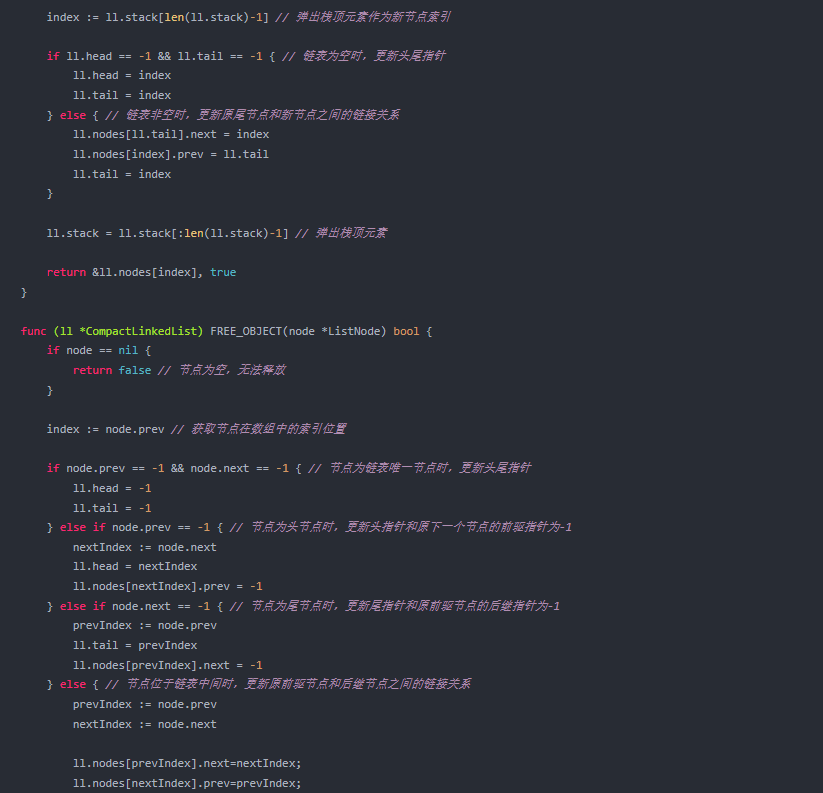
}func (ll *CompactLinkedList) ALLOCATE_OBJECT() (*ListNode, bool) {if len(ll.stack) == 0 {return nil, false // 栈空,无法分配新节点}index := ll.stack[len(ll.stack)-1] // 弹出栈顶元素作为新节点索引if ll.head == -1 && ll.tail == -1 { // 链表为空时,更新头尾指针ll.head = indexll.tail = index} else { // 链表非空时,更新原尾节点和新节点之间的链接关系ll.nodes[ll.tail].next = indexll.nodes[index].prev = ll.tailll.tail = index}ll.stack = ll.stack[:len(ll.stack)-1] // 弹出栈顶元素return &ll.nodes[index], true
}func (ll *CompactLinkedList) FREE_OBJECT(node *ListNode) bool {if node == nil {return false // 节点为空,无法释放}index := node.prev // 获取节点在数组中的索引位置if node.prev == -1 && node.next == -1 { // 节点为链表唯一节点时,更新头尾指针ll.head = -1ll.tail = -1} else if node.prev == -1 { // 节点为头节点时,更新头指针和原下一个节点的前驱指针为-1nextIndex := node.nextll.head = nextIndexll.nodes[nextIndex].prev = -1} else if node.next == -1 { // 节点为尾节点时,更新尾指针和原前驱节点的后继指针为-1prevIndex := node.prevll.tail = prevIndexll.nodes[prevIndex].next = -1 } else { // 节点位于链表中间时,更新原前驱节点和后继节点之间的链接关系prevIndex := node.prev nextIndex := node.next ll.nodes[prevIndex].next=nextIndex;ll.nodes[nextIndex].prev=prevIndex;}ll.stack = append(ll.stack, index) // 将释放的节点索引入栈return true
}
以上是一个基于栈的数组实现的紧凑双向链表。通过ALLOCATE_OBJECT方法可以分配新节点,FREE_OBJECT方法可以释放节点。该实现将所有元素存储在紧凑的连续内存中,并使用栈来管理空闲节点。

这篇关于文心一言 VS 讯飞星火 VS chatgpt (119)-- 算法导论10.3 4题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









