本文主要是介绍【视频】R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险|数据分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于逻辑回归的研究报告,包括一些图形和统计输出。本文介绍了逻辑回归并在R语言中用逻辑回归(Logistic回归)模型分类预测病人冠心病风险数据。
相关视频:R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
,时长06:48
逻辑回归是机器学习借用的另一种统计分析方法。当我们的因变量是二分或二元时使用它。
它只是表示一个只有 2 个输出的变量,例如,预测抛硬币(正面/反面)的情况。结果是二进制的:如果硬币是正面,则为 1,如果硬币为反面,则为 0。这种回归技术类似于线性回归,可用于预测分类问题的概率。
为什么我们使用逻辑回归而不是线性回归?
我们现在知道它仅在我们的因变量是二元的而在线性回归中该因变量是连续时使用。
现在,如果我们使用线性回归来找到旨在最小化预测值和实际值之间距离的最佳拟合线,这条线将是这样的:
这里的阈值为 0.5,这意味着如果 h(x) 的值大于 0.5,则我们预测为恶性肿瘤(1),如果小于 0.5,则我们预测为良性肿瘤(0)。
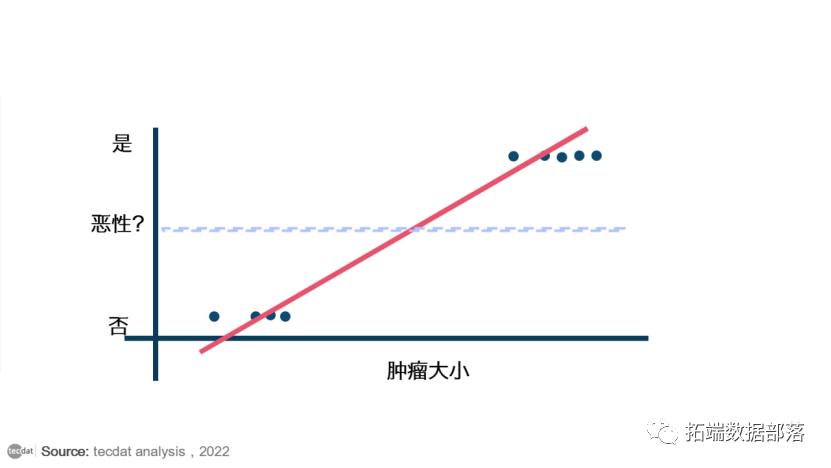
这里一切似乎都很好,但现在让我们稍微改变一下,我们在数据集中添加一些异常值,现在这条最佳拟合线将移动到该点。像这样:
你看到这里有什么问题吗?蓝线代表新阈值,此处可能为 0.2。为了保持我们的预测正确,我们不得不降低我们的阈值。因此,我们可以说线性回归容易出现异常值。现在如果预测值大于 0.2,那么只有这个回归会给出正确的输出。
线性回归的另一个问题是预测值可能超出范围。我们知道概率可以在 0 和 1 之间,但是如果我们使用线性回归,这个概率可能会超过 1 或低于 0。

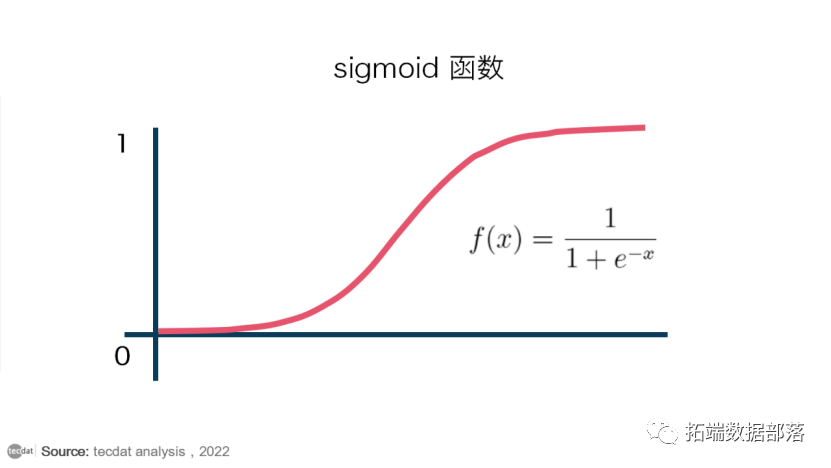
Sigmoid函数
为此,我们最好有一个函数将任何实际值映射到 0 和 1 之间的区间内的值。您一定想知道逻辑回归如何将线性回归的输出压缩在 0 和 1 之间。
Sigmoid 函数是一种数学函数,用于将预测值映射到概率。该函数能够将任何实际值映射到 0 和 1 范围内的另一个值。
规则是逻辑回归的值必须在 0 和 1 之间。由于它不能超过值 1 的限制,在图形上它会形成一条“S”形的曲线。这是识别 Sigmoid 函数或逻辑函数的简单方法。
关于逻辑回归,使用的概念是阈值。阈值有助于定义 0 或 1 的概率。例如,高于阈值的值趋于 1,低于阈值的值趋于 0。
这就是所谓的 sigmoid 函数,它是这样定义的:
最远离 0 的 x值 映射到接近 0 或接近 1 的 y值。x接近 0 的值 将是我们算法中概率的一个很好的近似值。然后我们可以选择一个阈值并将概率转换为 0 或 1 预测。
Sigmoid 是逻辑回归的激活函数。
成本函数
成本函数是用于计算误差的数学公式,它是我们的预测值和实际值之间的差异。它只是衡量模型在估计 x 和 y 之间关系的能力方面的错误程度。当我们考虑成本函数时,首先想到的是经典的平方误差函数。
m - 示例数,
x(i) - 第i个示例 的特征向量 ,
y(i) - 第i个示例 的实际值 ,
θ - 参数向量。

如果我们有一个线性激活函数h θ (x) 那就没问题了。但是使用我们的新 sigmoid 函数,我们没有平方误差的正二阶导数。这意味着它是非凸函数。我们不想陷入局部最优,因此我们定义了一个新的成本函数:
这称为交叉熵成本。如果您仔细观察,您可能会注意到,当预测值接近实际值时,0 和 1 实际值的成本都将接近于零。

让我们看看当 y=1 和 y=0 时成本函数的图形是什么
这里的蓝线代表1类(y=1),代价函数的右项会消失。现在,如果预测概率接近 1,那么我们的损失会更小,当概率接近 0 时,我们的损失函数会达到无穷大。
红线代表 0 类(y=0),左项将在我们的成本函数中消失,如果预测概率接近 0,那么我们的损失函数会更小,但如果我们的概率接近 1,那么我们的损失函数会达到无穷大。
此成本函数也称为对数损失。它还确保随着正确答案的概率最大化,错误答案的概率最小化。此成本函数的值越低,精度越高。

如果我们结合这两个图,我们将得到一个只有 1 个局部最小值的凸图,现在在这里使用梯度下降很容易。
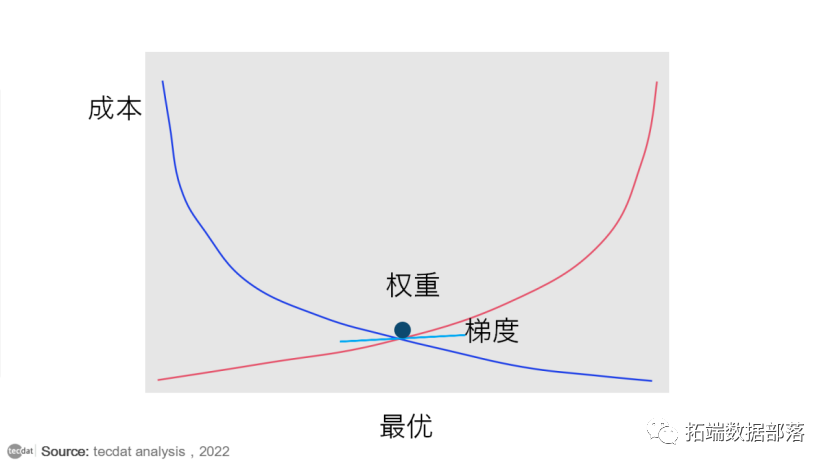
梯度下降优化
我们将尝试了解如何利用梯度下降来计算最小成本。
梯度下降以这样一种方式改变我们的权重值,它总是收敛到最小点,或者我们也可以说,它旨在找到最小化模型损失函数的最优权重。它是一种迭代方法,通过计算随机点的斜率然后沿相反方向移动来找到函数的最小值。
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
本文的目的是完成一个逻辑回归分析。使你对分析步骤和思维过程有一个基本概念。
library(tidyverse)
library(broom)这些数据来自一项正在进行的对镇居民的心血管研究。其目的是预测一个病人是否有未来10年的冠心病风险。该数据集包括以下内容。
-
男性:0=女性;1=男性
-
年龄。
-
教育。1 = 高中以下;2 = 高中;3 = 大学或职业学校;4 = 大学以上
-
当前是否吸烟。0=不吸烟;1=吸烟者
-
cigsPerDay: 每天抽的烟数量(估计平均)。
-
BPMeds: 0 = 不服用降压药;1 = 正在服用降压药
-
中风。0 = 家族史中不存在中风;1 = 家族史中存在中风
-
高血压。0 =高血压在家族史上不流行;1 =高血压在家族史上流行
-
糖尿病:0 = 没有;1 = 有
-
totChol: 总胆固醇(mgdL)
-
sysBP: 收缩压(mmHg)
-
diaBP: 舒张压(mmHg)
-
BMI: 体重指数
-
心率
-
葡萄糖:总葡萄糖mgdL
-
TenYearCHD: 0 = 患者没有未来10年冠心病的风险; 1 = 患者有未来10年冠心病的风险
加载并准备数据
read_csv("fraingha") %>%drop_na() %>% #删除具有缺失值的观察值ageCent = age - mean(age), totCholCent = totChol - mean(totChol),拟合逻辑回归模型
glm(TenYearCHD ~ age + Smoker + CholCent, data = data, family = binomial)
预测
对于新病人
data_frame(ageCent = (60 - 49.552), totCholCent = (263 - 236.848),
预测对数几率
predict(risk_m, x0)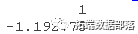
预测概率

根据这个概率,你是否认为这个病人在未来10年内有患冠心病的高风险?为什么?
risk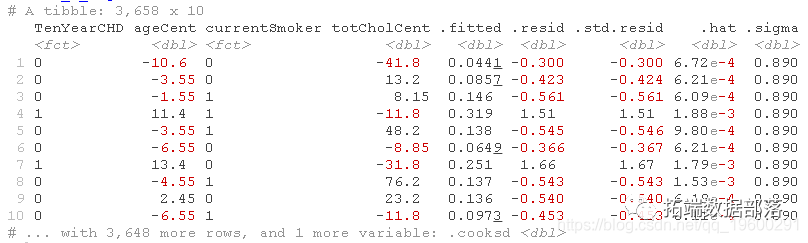
混淆矩阵
risk_m %>%group\_by(TenYearCHD, risk\_predict) %>%kable(format="markdown")
mutate( predict = if_else(.fitted > threshold, "1: Yes", "0: No"))
有多大比例的观察结果被错误分类?
依靠混淆矩阵来评估模型的准确性有什么缺点?
ROC曲线
ggplot(risk\_m\_aug, oc(n.cuts = 10, labelround = 3) + geom_abline(intercept = 0) +
auc(roc )$AUC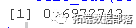
一位医生计划使用你的模型的结果来帮助选择病人参加一个新的心脏病预防计划。她问你哪个阈值最适合为这个项目选择病人。根据ROC曲线,你会向医生推荐哪个阈值?为什么?
假设
为什么我们不绘制原始残差?
ggplot(data = risk aes(x = .fitted, y = .resid)) +labs(x = "预测值", y = "原始残差")
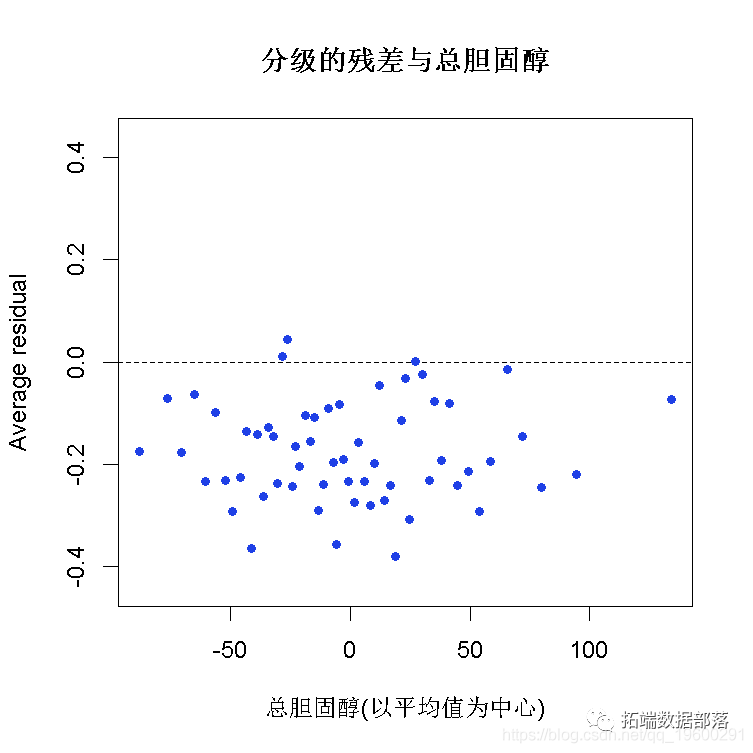
分级的残差图
plot(x = fitted, y = resid,xlab = "预测概率", main = "分级后的残值与预测值的对比",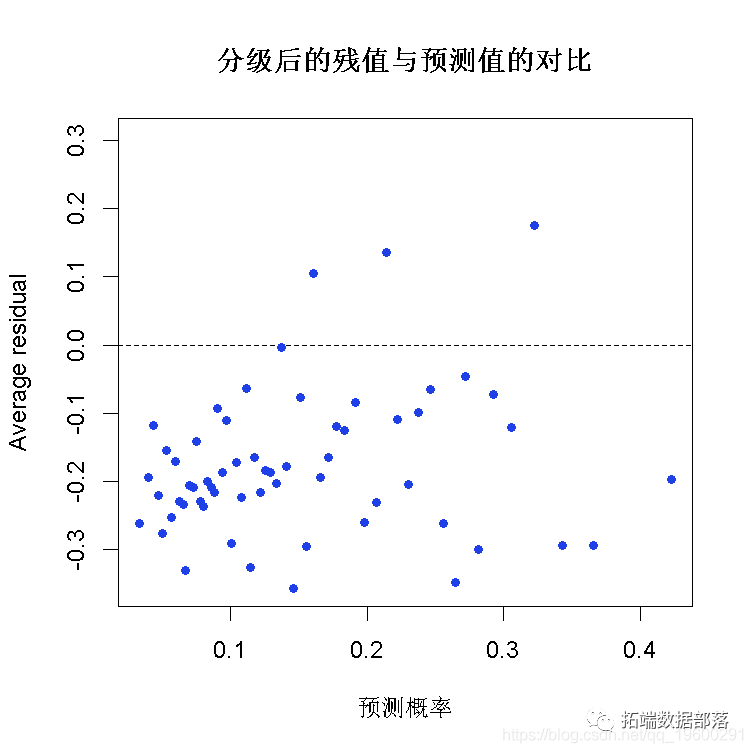

## # A tibble: 2 x 2
## currentSmoker mean_resid
## <fct> <dbl>
## 1 0 -2.95e-14
## 2 1 -2.42e-14检查假设:
- 线性?- 随机性?- 独立性?
系数的推断
currentSmoker1的测试统计量是如何计算的?
在统计学上,totalCholCent是否是预测一个人患冠心病高风险的重要因素?
用检验统计量和P值来证明你的答案。
用置信区间说明你的答案。
偏离偏差检验
glm(TenYearCHD ~ ageCent + currentSmoker + totChol, data = heart_data, family = binomial)
anova
AIC

根据偏离偏差检验,你会选择哪个模型?
基于AIC,你会选择哪个模型?
使用step逐步回归选择模型
step(full_model )

kable(format = "markdown" )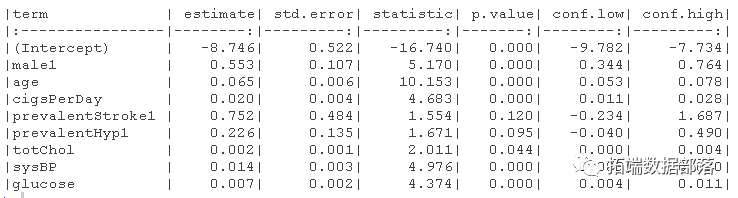

这篇关于【视频】R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险|数据分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




