本文主要是介绍数据分享|R语言零膨胀泊松回归ZERO-INFLATED POISSON(ZIP)模型分析露营钓鱼数据实例估计IRR和OR...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
全文链接:http://tecdat.cn/?p=26915
零膨胀泊松回归用于对超过零计数的计数数据进行建模。此外,理论表明,多余的零点是通过与计数值不同的过程生成的,并且可以独立地对多余的零点进行建模。因此,zip模型有两个部分,泊松计数模型和用于预测多余零点的 logit 模型。
相关视频
零膨胀泊松回归示例
示例 。野生动物生物学家想要模拟公园的渔民捕获了多少鱼。游客会被问到他们逗留了多长时间,团队中有多少人,团队中是否有儿童以及捕获了多少鱼。一些游客不钓鱼,但没有关于一个人是否钓鱼的数据。一些钓鱼的游客没有钓到任何鱼,因此数据中存在多余的零,因为人们没有钓鱼。
数据说明
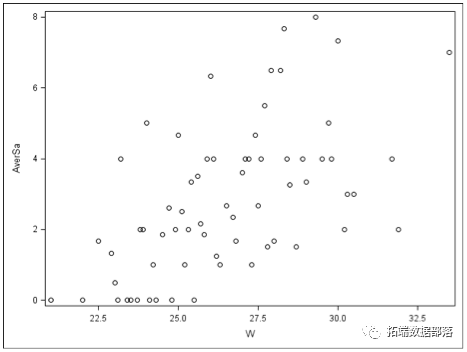
我们有 250 个去公园的团体的数据(查看文末了解数据获取方式)。每个小组都被询问他们捕获了多少鱼(count),小组中有多少孩子(child),小组中有多少人(persons),以及他们是否带露营者到公园(camper)。
让我们看一下数据。
summary(zib)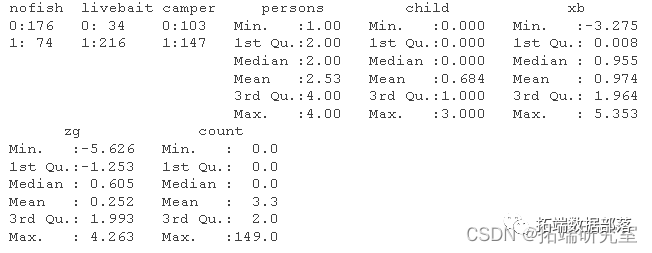
## 直方图的X轴为对数10标
ggplot(znb, aes(ount))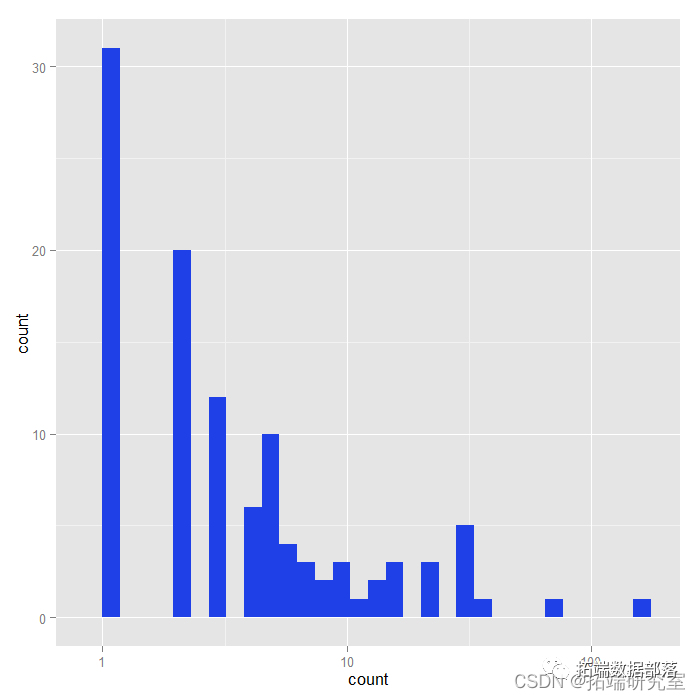
点击标题查阅往期内容

R语言泊松Poisson回归模型分析案例

左右滑动查看更多
01
02
03
04
您可能会考虑的分析方法
以下是您可能遇到的一些分析方法的列表。列出的一些方法是相当合理的,而另一些方法要么失宠,要么有局限性。
零膨胀泊松回归。
零膨胀负二项式回归——负二项式回归在分散数据时表现更好,即方差远大于平均值。
普通计数模型 。
OLS 回归——您可以尝试使用 OLS 回归分析这些数据。然而,计数数据是高度非正态的,并且不能通过 OLS 回归很好地估计。
零膨胀泊松回归
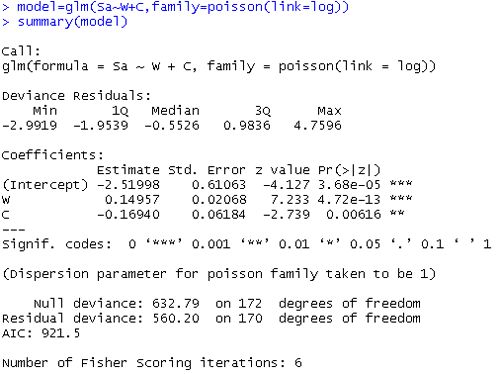
summary(m1)
输出看起来非常像 R 中两个 OLS 回归的输出。在模型调用下方,您会发现一个输出块,其中包含每个变量的泊松回归系数以及标准误差、z 分数和 p 值系数。接下来是对应于通货膨胀模型的第二个块。这包括用于预测多余零点的 logit 系数及其标准误差、z 分数和 p 值。
模型的计数和膨胀部分中的所有预测变量都具有统计显着性。该模型对数据的拟合显着优于空模型,即仅截距模型。为了证明情况确实如此,我们可以使用对数似然差异的卡方检验将当前模型与没有预测变量的空模型进行比较。
mnl <- update(m1, . ~ 1)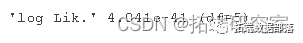
由于我们在完整模型中有三个预测变量,因此卡方检验的自由度为 3。这会产生较高的显着 p 值;因此,我们的整体模型具有统计学意义。
请注意,上面的模型输出并没有以任何方式表明我们的零膨胀模型是否是对标准泊松回归的改进。我们可以通过运行相应的标准 Poisson 模型然后对这两个模型进行 Vuong 检验来确定这一点。

vuong(p, m)
Vuong 检验将零膨胀模型与普通泊松回归模型进行比较。在这个例子中,我们可以看到我们的检验统计量是显着的,表明零膨胀模型优于标准泊松模型。
我们可以使用自举获得参数和指数参数的置信区间。对于泊松模型,这些将是事件风险比,对于零通胀模型,优势比。此外,对于最终结果,可能希望增加重复次数以帮助确保结果稳定。
dt(coef(m1, "count"))
dpt(coef(m1, "zero"))
res <- boot(znb, f, R = 1200, pralel = "snow", ncus = 4)
## 输出结果
res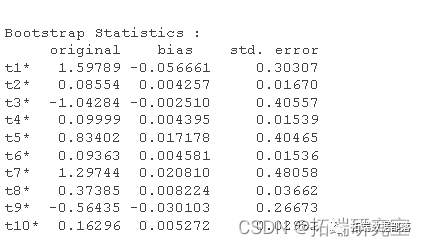
结果是交替的参数估计和标准误差。也就是说,第一行具有我们模型的第一个参数估计值。第二个具有第一个参数的标准误差。第三列包含自举的标准误差。
现在我们可以得到所有参数的置信区间。我们从原始比例开始,使用百分位数和偏差调整的 CI。我们还将这些结果与基于标准误差的置信区间进行比较。
## 带百分位数和偏差调整的CI的基本参数估计值## 添加行名
row.names(pms) <- names(coef(m))
## 输出结果
parms
## 与基于正常的近似值相比
confint(m1)
bootstrap置信区间比基于正态的近似值要宽得多。使用稳健标准误差时,自举 CI 与来自 Stata 的 CI 更加一致。
现在我们可以估计泊松模型的事件风险比 (IRR) 和逻辑(零通胀)模型的优势比 (OR)。
## 带百分位数和偏差调整的CI的指数化参数估计值
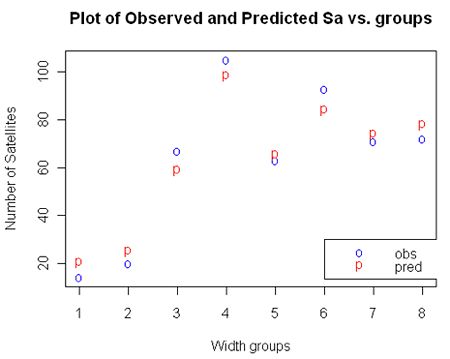
exps <- t(sapply(c(1, 3, 5, 7, 9), function(i) {out <- boot.ci为了更好地理解我们的模型,我们可以计算预测变量的不同组合所捕获的鱼的预期数量。事实上,由于我们基本上使用的是分类预测,我们可以使用函数来计算所有组合的期望值来创建所有组合。最后我们创建一个图表。
ggplot(neda1, aes(x = cld, y = pat, colour = factor(pos))) +geom_point() +geom_line() +facet_wrap(~cmp)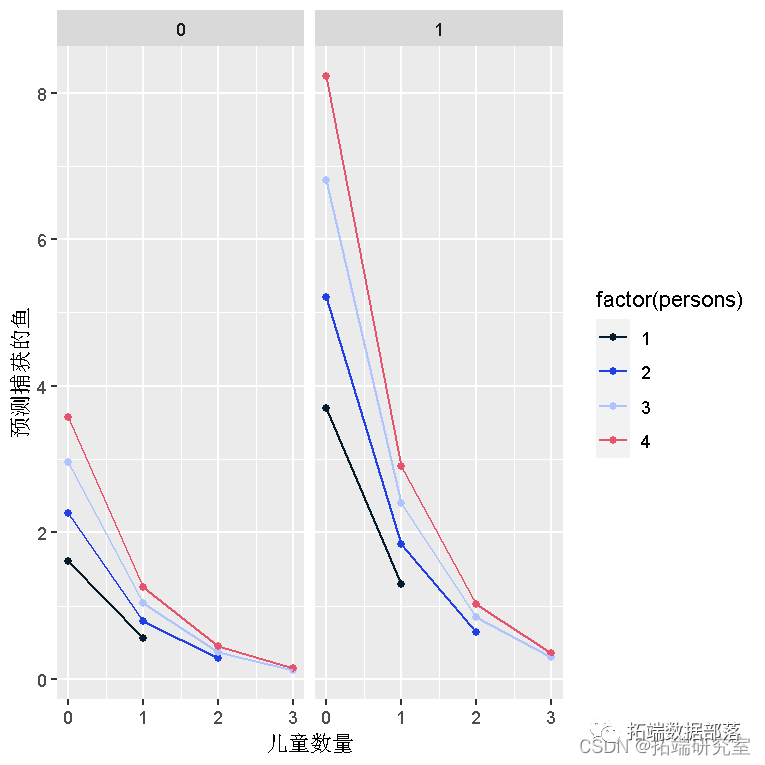
需要考虑的事项
由于 zip 同时具有计数模型和 logit 模型,因此这两个模型中的每一个都应该具有良好的预测器。这两个模型不一定需要使用相同的预测变量。
零膨胀模型的逻辑部分可能会出现完美预测、分离或部分分离的问题。
计数数据通常使用暴露变量来指示事件可能发生的次数。
不建议将零膨胀泊松模型应用于小样本。
数据获取
在下面公众号后台回复“钓鱼数据”,可获取完整数据。

点击文末“阅读原文”
获取全文完整资料。
本文选自《R语言零膨胀泊松回归ZERO-INFLATED POISSON(ZIP)模型分析露营钓鱼数据实例估计IRR和OR》。
点击标题查阅往期内容
R语言贝叶斯Poisson泊松-正态分布模型分析职业足球比赛进球数
R语言贝叶斯METROPOLIS-HASTINGS GIBBS 吉布斯采样器估计变点指数分布分析泊松过程车站等待时间
R语言和Python用泊松过程扩展:霍克斯过程Hawkes Processes分析比特币交易数据订单到达自激过程时间序列
数据分享|R语言广义线性模型GLM:线性最小二乘、对数变换、泊松、二项式逻辑回归分析冰淇淋销售时间序列数据和模拟
生态学模拟对广义线性混合模型GLMM进行功率(功效、效能、效力)分析power analysis环境监测数据
广义线性模型glm泊松回归的lasso、弹性网络分类预测学生考试成绩数据和交叉验证
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
R语言贝叶斯广义线性混合(多层次/水平/嵌套)模型GLMM、逻辑回归分析教育留级影响因素数据
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言广义线性模型GLM、多项式回归和广义可加模型GAM预测泰坦尼克号幸存者
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言广义线性模型(GLMs)算法和零膨胀模型分析
R语言中广义线性模型(GLM)中的分布和连接函数分析
R语言中GLM(广义线性模型),非线性和异方差可视化分析
R语言中的广义线性模型(GLM)和广义相加模型(GAM):多元(平滑)回归分析保险资金投资组合信用风险敞口
用广义加性模型GAM进行时间序列分析
R和Python机器学习:广义线性回归glm,样条glm,梯度增强,随机森林和深度学习模型分析
在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析
用广义加性模型GAM进行时间序列分析
R和Python机器学习:广义线性回归glm,样条glm,梯度增强,随机森林和深度学习模型分析
在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析

![]()

这篇关于数据分享|R语言零膨胀泊松回归ZERO-INFLATED POISSON(ZIP)模型分析露营钓鱼数据实例估计IRR和OR...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





