本文主要是介绍一文讲透彻初学者怎么入门大语言模型(LLM)?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于如何入门LLM,大多数回答都提到了调用API、训练微调和应用。但是大模型更新迭代太快,这个月发布的大模型打榜成功,仅仅过了一个月就被其他模型超越。训练微调也已经不是难事,有大量开源的微调框架(llamafactory、firefly等),你只要懂部署,配置几个参数就能启动训练。甚至现在有大量云上项目,你根本不需要部署,直接上传数据,就能启动。
这我让想起来之前的算法工程师都被调侃成调参师,新出一个大模型,下载下来跑一遍,运行一遍AutoTokenizer.from_pretrained(model_path),对于自己理解和入门大模型没有任何意义。
对于初学者如何入门,我的建议是从一个开源大模型入手,全面了解它的运行原理以及如何应用。可以将大模型比作一辆车,我开车无需理解车是如何做的,但是车出问题了,了解原理能够帮我们快速找到其中的问题。
为了更好入门大模型,我建议按照如下顺序,分为编程基础准备、大模型原理理解和大模型应用三个部分。
一、编程基础准备
1.熟练Python编程语言
我一般使用numpy用于数据处理,matplotlib用于画图分析(比如分析位置编码、注意力矩阵),numpy很多函数与pytorch类似放后面讲,这里主要讲常用的matplotlib画图函数,学好matplotlib库有利于我们以可视化的角度去理解一些大模型原理。
plt.bar(x,y,width)
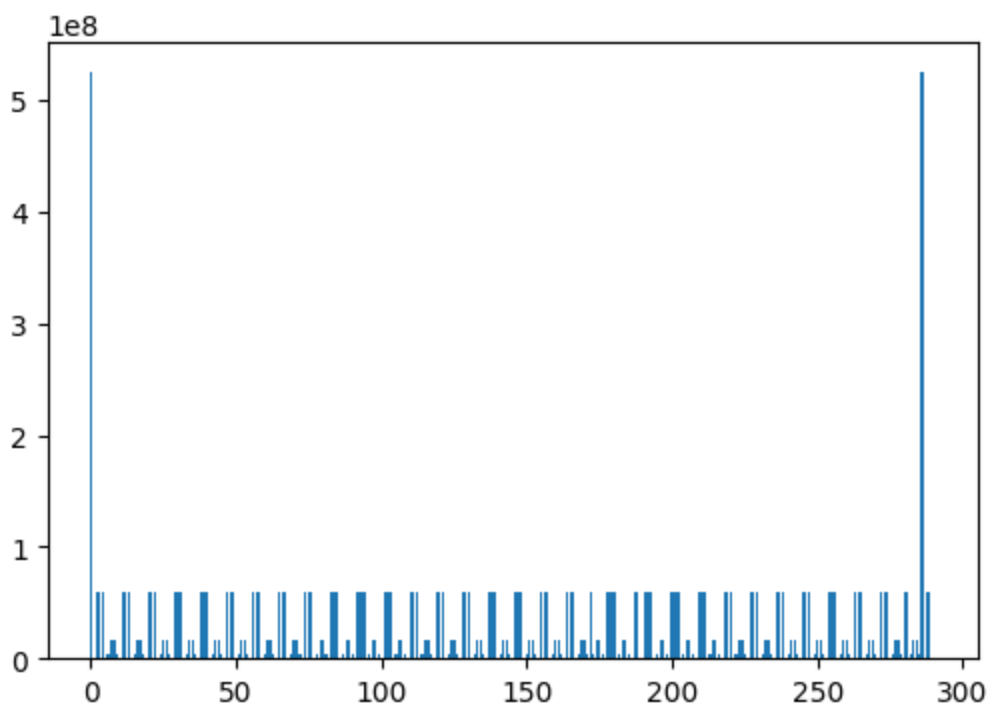
举个例子,画直方图分析llama3 8B中参数分布情况,可以发现有2个峰值,分别是embedding层和最后输出logits层,两者参数量一致。
plt.plot(x,y,width)
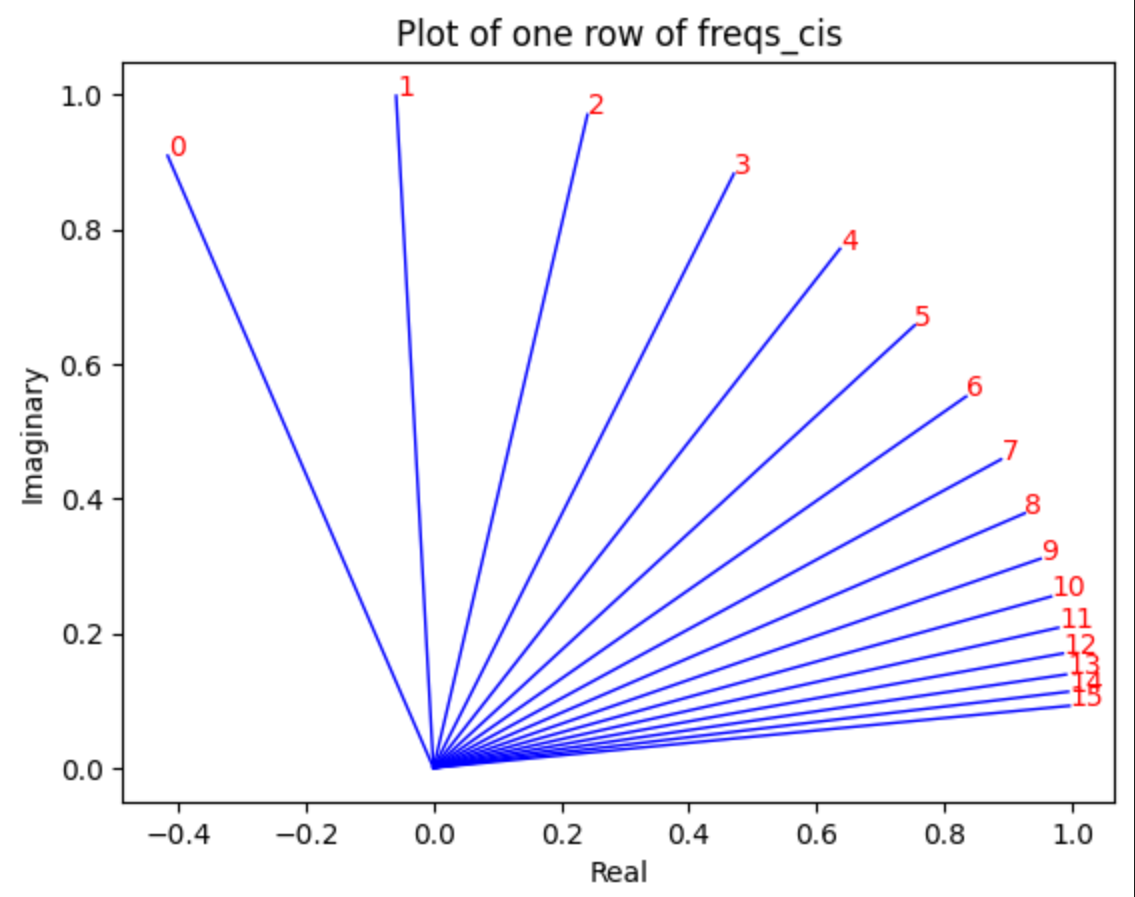
举个例子,画点图分析llama3 8B中的位置编码RoPE。在同一位置m下,可以发现向量中的元素 q m , i {q_{m,i}} qm,i,在i比较小的时候变化较快,i较大的时候变化较慢。
plt.colorbar(x,y)
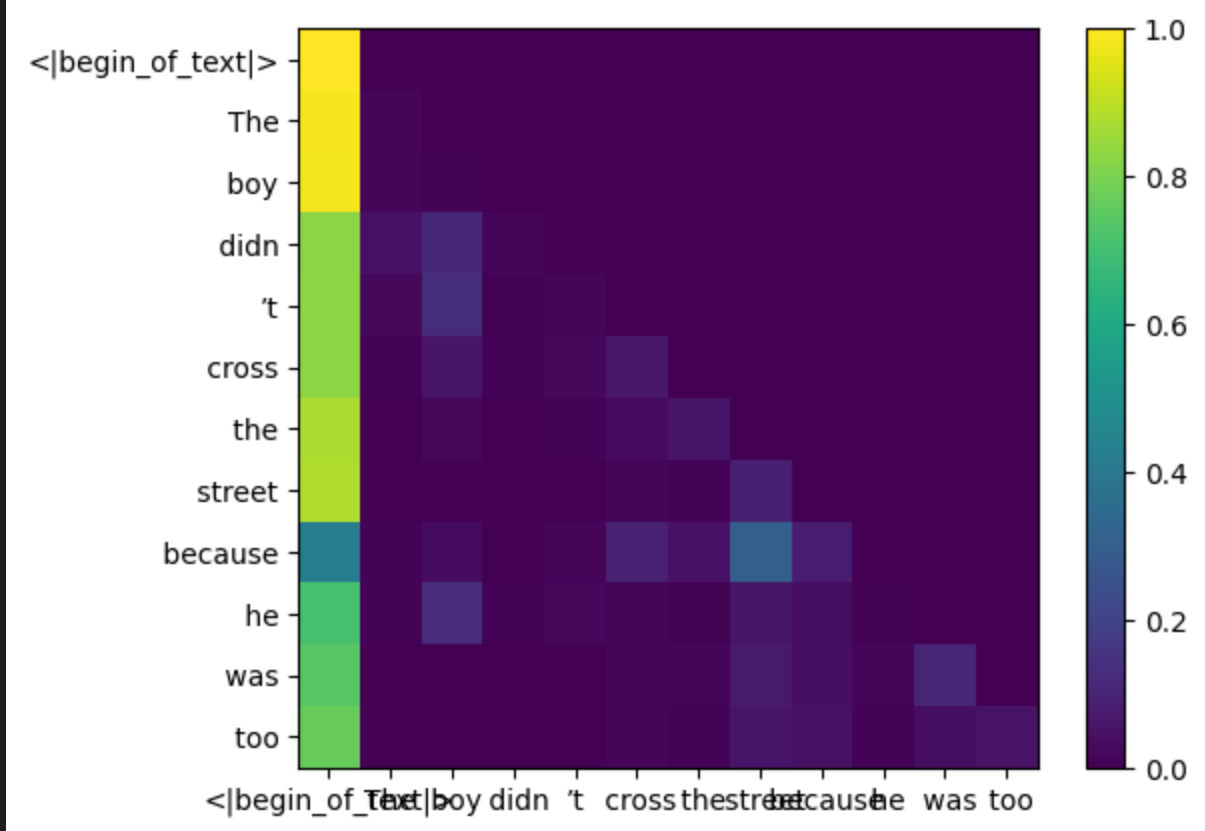
举个例子,画热力图分析llama3 8B中的Attenion矩阵。我的intput为“The boy didn’t cross the street because he was too ”,要预测下一个词。观察第10行(分析注意力矩阵都是以行为单位)可以发现"he"这个toke与"boy"这个token关联度很高,而不是“street”这个token。
所以说画图很重要,深度学习本质上都是矩阵运算,单看数字看不出什么结论,需要结合画图等可视化工具分析。
2.熟悉pytorch等深度学习框架
目前主流大模型基本上都是用pytorch写的,pytorch语法太多了,下面介绍在LLM中常用的pytorch语法(排序不分先后)
(1).torch.nn.Embedding(num_embeddings, embedding_dim...)
其中num_embeddings代表词表的大小,embedding_dim代表词向量的维度。embedding.weight的size为[num_embeddings,embedding_dim]。举个例子,输入索引i,输出embedding.weight 的第 i 行。
(2).torch.matmul(x,y) 、 x*y 、 torch.dot(x,y) 与 torch.mul(x,y)之间的区别
其中torch.matmul(x,y)代表矩阵相乘,torch.mul(x,y)与x*y均代表矩阵对应元素相乘, torch.dot(x,y)代表向量之间的点积。
(3).torch.full(size, fill_value)
torch.full([2,3],2.0)
#tensor([[2,2,2],[2,2,2]])
(4).torch.triu(x)
import torch
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = torch.triu(a)
print(b)# tensor([[1, 2, 3], [0, 5, 6], [0, 0, 9]])
用于注意力机制中的mask计算
(5). torch.outer(x,y)
x = torch.arange(1,5)
y = torch.arange(1,4)
print(torch.outer(x,y))
# tensor([[ 1, 2, 3],[ 2, 4, 6],[ 3, 6, 9],[ 4, 8, 12]])
一般用于大模型位置编码计算中,比如正弦余弦位置编码、相对位置编码、 旋转位置编码等。
(6). torch.view_as_complex(x)
x=torch.randn(4, 2)
# tensor([[ 0.0024, 1.5686],[-1.2883, 1.0111],[ 0.8764, 0.1839],[ 0.8543, -0.0061]])
torch.view_as_complex(x)
# tensor([0.0024+1.5686j, -1.2883+1.0111j, 0.8764+0.1839j, 0.8543-0.0061j])
大模型位置编码有两种计算方法,一种是在实数域计算、一种是复数域计算。该函数一般用于复数域计算。
(7). torch.view_as_real(x)
x= torch.tensor([ 0.0024+1.5686j, -1.2883+1.0111j, 0.8764+0.1839j, 0.8543-0.0061j])
torch.view_as_real(x)
# tensor([[ 0.0024, 1.5686],[-1.2883, 1.0111],[ 0.8764, 0.1839],[ 0.8543, -0.0061]])
同上
(8). 弄清楚torch.reshape(input,shape) 和torch.view(input,shape)
我建议从内存分配的角度来理解reshape。无论一个张量 shape 怎么改变,它的分量在内存中的存储顺序也是不变的。
import numpy as np
a = np.arange(6)# 其中order="C"、"F"、"A"分别代表不同读取顺序,
print(np.reshape(a, (2, 3), order='C'))
#[[0 1 2][3 4 5]]
print(np.reshape(a, (2, 3), order='F'))
#[[0 2 4][1 3 5]]
print(np.reshape(a, (2, 3), order='A'))
#[[0 1 2][3 4 5]]
(9). 弄清楚torch.transpose(tensor,dim0,dim1)和torch.permute(dim0, dim1, dim2, dim3)
两者均代表矩阵的转置,在二维的时候很容易想明白转置之后的情况,但是高维度的时候就糊涂了。举个例子:
arr = torch.arange(16)
arr = arr.reshape(2,2,4)
# tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7]],[[ 8, 9, 10, 11],[12, 13, 14, 15]]])
arr = arr.transpose(1,2)
# tensor([[[ 0, 4],[ 1, 5],[ 2, 6],[ 3, 7]],[[ 8, 12],[ 9, 13],[10, 14],[11, 15]]])
上面这个三维数组例子,我定义为(batch,H,W),transpose(1,2)等效于长和宽转置。类似这样的例子我们已经练习过很多次了。
不过如何理解arr.transpose(0,1)?,batch和H之间转置没有直接的物理含义。这需要借用矩阵stride概念来理解。
详解见:https://www.bilibili.com/video/BV1pN4y117rD
(10). torch.cat 和 torch.stack的区别
(11). 以及一些常用的数学计算公式torch.rsqrt、tensor.pow、torch.mean等等
二、大模型原理理解
整体要干什么?
简单来说通过基于Transformer架构预测下一个词出现的概率。就不放Attention is all you Need论文里的图了。我这里放一张llama3-8B的网络架构图。这个网络架构里的每一个模块,你都能手写出来,就算是大模型原理这一块入门了。建议学习网络架构的时候带着问题去学习,不要局限于矩阵中的元素怎么乘,pytorch语法只是工具,真正需要做的是思考为什么这样做以及背后的数学含义。下面分享一下我亲身学习大模型原理,思考的一些点,希望对大家有帮助。
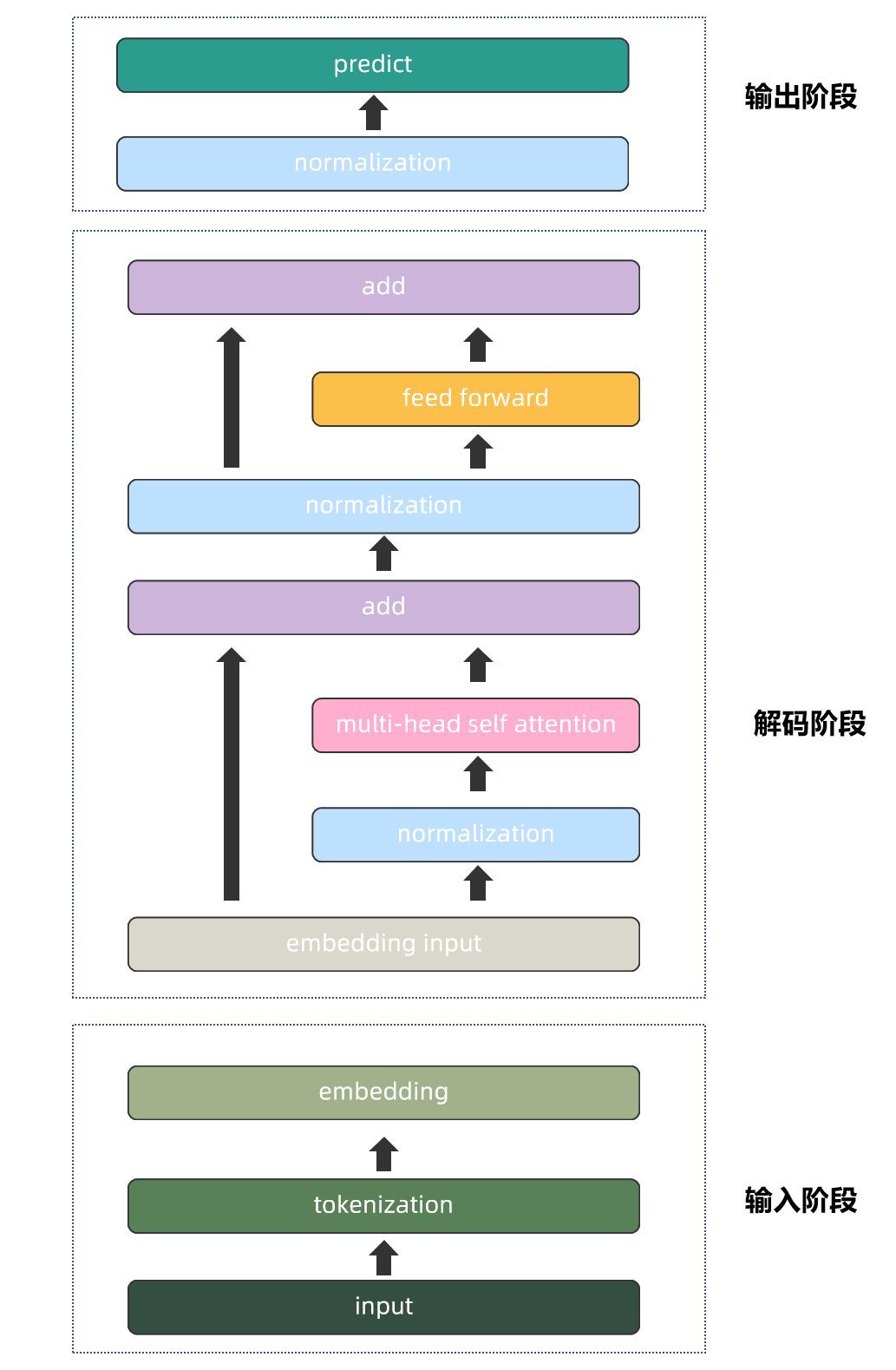
1.自注意力机制的理解
-
了解单头注意力机制,什么是K矩阵、V矩阵和Q矩阵,以及如下公式为什么要除 d k {\sqrt{d_k}} dk
o u t p u t = s o f t m a x ( Q K T ) d k V output = {softmax({QK^T})\over{\sqrt{d_k}}}V output=dksoftmax(QKT)V -
分析为什么在注意力机制中要加入mask?
-
分析
attention is all you need这篇文章中的多头注意力机制(MHA),分析为什么要多头?单头注意力机制为什么不行? -
分析为什么要搞Grouped-query Attention(GQA),它相比MHA的好处在哪里?以及应用在哪些方面。
上面四点弄明白,对于注意力机制差不多算入门了。
2.位置编码的理解
- 为什么需要位置编码?它解决了常规NLP网络架构中的什么问题
- 绝对位置编码和相对位置编码,他们各有什么优点和缺点
- 为什么现在大模型都在用旋转位置编码RoPE?它在实数域和复数域的实现方式是怎样的?RoPE的缺点有哪些?顺带可以了解下最新的上下文位置编码CoPE。
- 大模型为什么有Long-Context问题以及如何利用位置编码去解决长文本问题?
3.前馈网络(feed forwad)的理解
-
为什么需要前馈网络?
-
为什么llama3要使用SwiGLU?
4.归一化(normalization )
- 为什么需要归一化?
- batch normalization 、layer normalization有什么区别?为什么语言模型用layer normalization,不去用batch normalization?
- 详细理解layer normalization中RMS Norm,分析其相比常规layer normalization的优势。
5.推理
-
本质上每次推理都是一次吐一个字?如何加速推理?可以去了解KV Cache。
-
句子长度参差不齐,batch推理如何补齐长度?
-
如果最后大模型输出
logits取最大值,那么大模型生成式能力从何体现?这就需要去了解大模型参temperature和top p参数理解
三、大模型应用
1.微调训练
- 大模型训练分为预训练、指令微调和人类反馈强化学习。大模型训练对于硬件要求高,平民玩家没卡,建议去了解Lora、QLora等高效微调算法。
- 了解llamfactory、Firefly等大模型微调框架,自己做个数据集,在大模型的基础上微调子任务。
- 如果有卡,可以尝试多卡多机跑跑模型,因为我也没什么卡,所以没法给出建议。
2.RAG
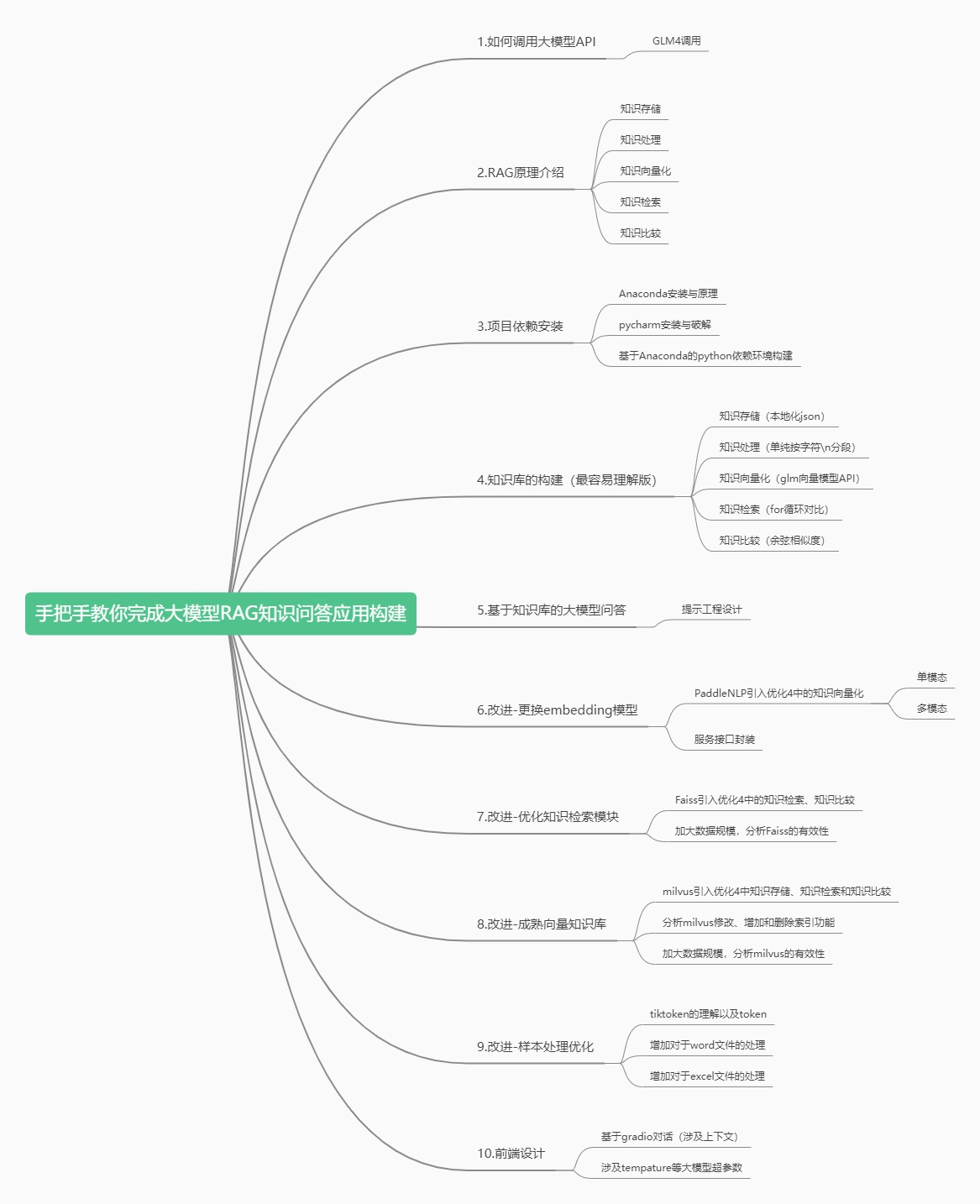
- 思考为什么要RAG?RAG和Long Context之间是什么关系?
- RAG分为知识库构建、知识检索和智能问答,从零实现一个最简单的RAG。教程见https://zhuanlan.zhihu.com/p/696872562
- 在最简单RAG的基础上,学一学Faiss、Milvus等向量数据库,优化RAG中涉及的检索、知识存储
- 学一学成熟的RAG框架ragflow
3.Agent
- 从零手写一个Agent框架,见https://github.com/KMnO4-zx/TinyAgent
- 学一学成熟的Agent框架langchain、dify等
最后,我也在持续学习中,如果文章有错误欢迎评论区各位大佬指出!
这篇关于一文讲透彻初学者怎么入门大语言模型(LLM)?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




