本文主要是介绍手机流畅运行470亿参数大模型,上交大发布PowerInfer-2推理框架,性能提升29倍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
苹果一出手,在手机等移动设备上部署大模型迅速成为行业焦点。
目前,移动设备上运行的模型相对较小(苹果的是3B,谷歌的是2B),并且消耗大量内存,这在很大程度上限制了其应用场景。
即使是苹果,也需要与OpenAI合作,通过将云端GPT-4o大模型嵌入到操作系统中来提供更强大的服务。
GPT-4o深夜发布!Plus免费可用!![]() https://www.zhihu.com/pin/1773645611381747712
https://www.zhihu.com/pin/1773645611381747712
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
这种混合方案引发了关于数据隐私的讨论和争议,甚至马斯克也参与了讨论。
既然本地部署大模型既能提供强大的AI功能,又能保护隐私,为什么苹果还要冒着隐私风险选择云端大模型呢?主要有两点挑战:
- 手机内存不足:根据大模型的Scaling Law法则,模型参数越大,能力越强,对内存的要求也越高。
- 手机算力不够:即使通过量化等手段将模型塞进手机,推理速度也慢,适用场景有限。
为了解决这些挑战,上海交大IPADS实验室推出了面向手机的大模型推理引擎PowerInfer-2.0。

论文地址:https://arxiv.org/pdf/2406.06282
PowerInfer-2.0能够在内存有限的智能手机上实现快速推理,让Mixtral 47B模型在手机上达到11 tokens/s的速度。
与热门开源推理框架llama.cpp相比,PowerInfer-2.0的推理加速比平均达到25倍,最高达29倍。
针对手机运行内存不足的问题,PowerInfer-2.0利用了稀疏模型推理的特点:每次只需激活一小部分神经元,即“稀疏激活”。
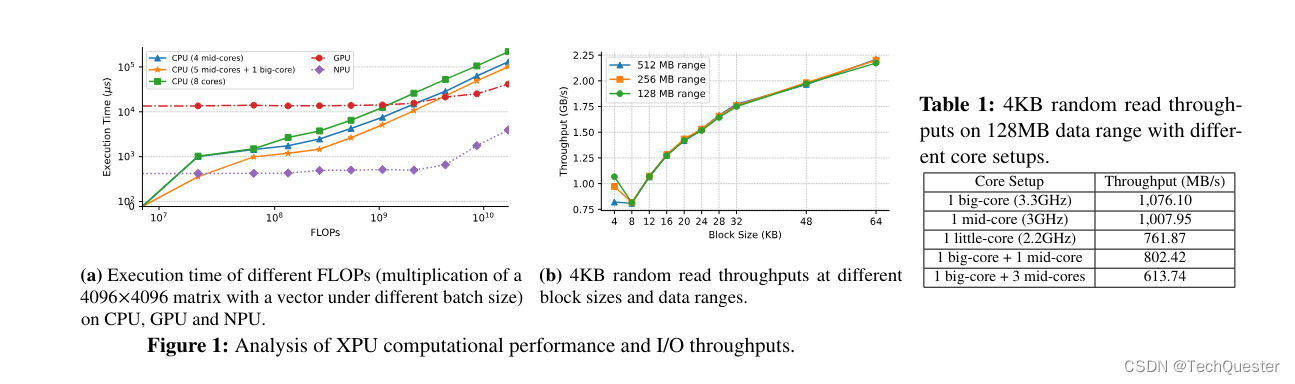
未激活的神经元不参与推理计算,不影响模型输出质量。
稀疏激活为降低模型推理的内存使用创造了机会。
PowerInfer-2.0将神经网络中的神经元分为冷、热两种,并在内存中基于LRU策略维护一个神经元缓存池。
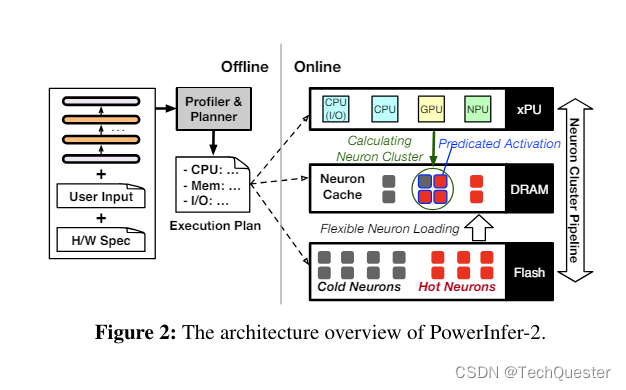
频繁激活的“热神经元”被放置在运行内存中,而“冷神经元”只有在被预测激活时才会被拉进内存,大幅降低了内存使用量。
冷热神经元分类继承自PowerInfer-1.0已有的做法。
去年12月,苹果在“LLM in a Flash”中提出了类似的“滑动窗口”技术,但这些工作主要针对PC环境,直接迁移到手机环境还会遇到新的难题。
手机平台的硬件条件远不及PC,无论是算力、内存总量还是存储带宽,都存在较大差距。
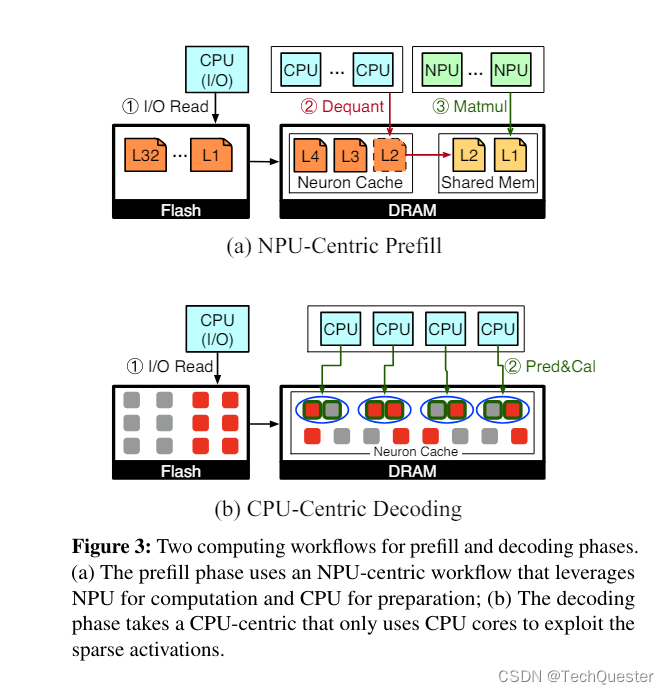
手机硬件平台存在CPU、GPU、NPU三种异构计算单元,十分复杂。
神经元簇概念不仅适应手机的异构计算环境,还能支持计算与存储I/O的流水线并行执行。
而对于Mistral 7B这种可以放进手机运行内存的模型,PowerInfer-2.0可以节约40%内存的情况下,达到与llama.cpp和MLC-LLM同水平甚至更快的解码速度:
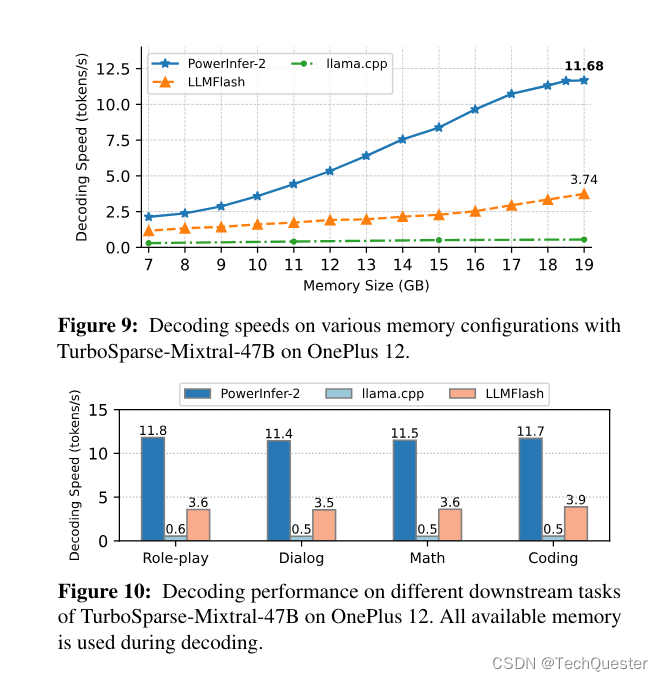
PowerInfer-2.0提出了分段神经元缓存和神经元簇级的流水线技术,在一个神经元簇等待I/O时,可以及时调度另一个已准备好的神经元簇到处理器上计算,从而隐藏I/O延迟。
这种基于神经元簇的流水线打破了传统推理引擎中逐矩阵计算的方式,允许来自不同参数矩阵的神经元簇交错执行,达到最高的并行效率。
如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!
官网有更详细介绍:WildCard
推荐阅读:
如何免费使用GPT-4o?如何升级GPT...
更强大Mamba-2正式发布啦!!!
黎曼猜想取得重大进展!!
这篇关于手机流畅运行470亿参数大模型,上交大发布PowerInfer-2推理框架,性能提升29倍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






