本文主要是介绍基于DenseNet网络实现Cifar-10数据集分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1.作者介绍
- 2.Cifar-10数据集介绍
- 3.Densenet网络模型
- 3.1网络背景
- 3.2网络结构
- 3.2.1Dense Block
- 3.2.2Bottleneck层
- 3.2.3Transition层
- 3.2.4压缩
- 4.代码实现
- 4.1数据加载
- 4.2建立 DenseNet 网络模型
- 4.3模型训练
- 4.4训练代码
- 4.5测试代码
- 参考链接
1.作者介绍
吴思雨,女,西安工程大学电子信息学院,2023级研究生
研究方向:机器视觉与人工智能
电子邮件:2879944563@qq.com
陈梦丹,女,西安工程大学电子信息学院,2022级研究生
研究方向:机器视觉与人工智能
电子邮件:1169738496@qq.com
2.Cifar-10数据集介绍
Cifar-10数据集由10个类别的60000张32x32彩色图像组成,每个类别有6000张图像。有50000个训练图像和10000个测试图像。
数据集分为五个训练批次和一个测试批次,每个批次有10000张图像。测试批次恰好包含从每个类别中随机选择的1000幅图像。训练批包含按随机顺序排列的剩余图像,但某些训练批可能包含来自一个类的图像多于另一类的图像。在它们之间,训练批次恰好包含每个类的5000个图像。
以下是数据集中的类,以及每个类的10张随机图像:

这些类是完全不同的。汽车和卡车之间没有重叠。“汽车”包括轿车,SUV,诸如此类的东西。“卡车”只包括大卡车。两者都不包括皮卡。
Cifar-10官网下载链接:http://www.cs.toronto.edu/~kriz/cifar.html
Cifar-10数据集有三个版本,本文采用的是第一个版本:Cifar-10 python version。

3.Densenet网络模型
3.1网络背景
DenseNet(《Densely connected convolutional networks》) 斩获CVPR 2017的最佳论文奖,它的基本思路与ResNet一致,但是在参数和计算成本更少的情形下实现了比ResNet更优的性能,它建立的是前面所有层与后面层的密集连接(即相加变连结),它的名称也是由此而来。
DenseNet的另一大特色是通过特征在通道上的连接来实现特征重用。这些特点让DenseNet的参数量和计算成本都变得更少了,效果也更好了。ResNet解决了深层网络梯度消失问题,它是从深度方向研究的。宽度方向是GoogleNet的Inception。而DenseNet是从feature入手,通过对feature的极致利用能达到更好的效果和减少参数。
3.2网络结构

上图是一个包含5layer的Dense Block。可以看出Dense Block互相连接所有的层,具体来说就是每一层的输入都来自于它前面所有层的特征图,每一层的输出均会直接连接到它后面所有层的输入。所以对于一个L层的DenseBlock,共包含
L*(L+1)/2 个连接,如果是ResNet的话则为(L-1)2+1。从这里可以看出:相比ResNet,Dense Block采用密集连接。而且Dense Block是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
Dense Net的网络结构主要由Dense Block和Transition*组成;如下图所示。一个DenseNet中有3个或4个DenseBlock。而一个DenseBlock中也会有多个Bottleneck layers。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器,得到每个类别所属分数。

3.2.1Dense Block
1.Dense connective
为了进一步改善层之间的信息流,提出了一种不同的连接模式:引入了从任何层到所有后续层的直接连接。因此,第l层接收所有先前层的特征图:X0,X1,…Xl-1作为输入: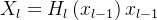
2.Composite function—复合功能
将 Hℓ(⋅)定义为三个连续运算的复合函数:批量归一化(BN),然后是 ReLU 和一个 3×3的卷积(Conv)。

 其中,ℓ表示第几层;将第ℓ 层的输出表示为Xℓ; [X0,X1,…]表示将第0,1…(ℓ-1)层的特征图进行组合。将非线性变换Hℓ(⋅)定义为三个连续操作的符合函数:BN+ReLU+一个3×3的Conv。
其中,ℓ表示第几层;将第ℓ 层的输出表示为Xℓ; [X0,X1,…]表示将第0,1…(ℓ-1)层的特征图进行组合。将非线性变换Hℓ(⋅)定义为三个连续操作的符合函数:BN+ReLU+一个3×3的Conv。
3.Growth rate—增长率
k–DenseNet中的growth rate(增长率),这是一个超参数。一般情况下使用较小的k,就可以得到较佳的性能。假定输入层的特征图的通道数为k0,那么L层输入的channel数为 k0+k*(L-1),因此随着层数增加,尽管k设定得较小,DenseBlock中每一层输入依旧会越来越多。
3.2.2Bottleneck层
尽管每一层仅生成k个输出特征图,但通常具有更多输入。可以在每次3×3卷积之前引入1×1卷积作为瓶颈层,以减少输入特征图的数量,从而提高计算效率。并且将具有此类瓶颈层的网络称为DenseNet-B,瓶颈层如下图所示。

3.2.3Transition层
当特征图的大小改变时,不能直接连接。然而,卷积网络的重要组成部分是降低特征图大小的下采样层。为了便于在体系结构中进行下采样,将网络划分为多个密集连接的密集块。如下图所示,将块之间的层称为过渡层,它们进行卷积和池化。实验中使用的过渡层包括批处理规范化层和1×1卷积层,然后是一个 2×2的平均池化层。

3.2.4压缩
为了进一步提高模型的紧凑性,可以减少转换层的特征图数量。引入一个压缩因子θ(0 < θ ≤1),当θ=1时转换层的输入和输出特征数不变,也就是经过转换层后特征数不变;当θ <1时,输入特征图数为m时,输出为⌊θm⌋。将θ<1的DenseNet称为DenseNet-C (在实验中设置θ=0.5)。
4.代码实现
4.1数据加载
CIFAR 数据集可以从官网下载后使用,也可以使用 datasets 类自动加载(如果本地路径没有该文件则自动下载)。大型训练数据集不能一次性加载全部样本来训练,可以使用 Dataloader 类自动加载数据。Dataloader 是一个迭代器,基本功能是传入一个 Dataset 对象,根据参数 batch_size 生成一个 batch 的数据。
4.2建立 DenseNet 网络模型
建立一个 DenseNet 网络模型进行训练,包括三个步骤:
1.实例化 DenseNet 模型对象;
2.设置训练的损失函数;
3.设置训练的优化器。
4.3模型训练
在模型训练过程中,可以使用验证集数据评价训练过程中的模型精度,以便控制训练过程。模型验证就是用验证数据进行模型推理,前向计算得到模型输出,但不反向计算模型误差,因此需要设置 torch.no_grad()。
4.4训练代码
# 经典模型: 使用 DenseNet 模型 进行 CIFAR10 图像分类,使用 Torchvision 预定义模型
# 使用 torchvision.models.densenet.DenseNet 类
# Copyright: youcans@qq.com
# Crated: Huang Shan, 2023/05/20# _*_coding:utf-8_*_
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import transforms, models
from matplotlib import pyplot as plt
import numpy as np# 优化结果写入数据文件
import pandas as pd
def WriteDataFile(epoch_list, loss_list, accu_list, filepath):# print("def WriteDataFile()")optRecord = {"epoch": epoch_list,"train_loss": loss_list,"accuracy": accu_list}dfRecord = pd.DataFrame(optRecord)dfRecord.to_csv(filepath, index=False, encoding="utf_8_sig")print("写入数据文件: %s 完成。" % filepath)returnif __name__ == '__main__':device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)# (1) 将[0,1]的PILImage 转换为[-1,1]的Tensortransform_train = transforms.Compose([transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomRotation(10), # 随机旋转transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),transforms.Resize((32, 32)), # 图像大小调整为 (w,h)=(32,32)transforms.ToTensor(), # 将图像转换为张量 Tensortransforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261))])# 测试集不需要进行数据增强transform = transforms.Compose([transforms.Resize((32, 32)), # 图像大小调整为 (w,h)=(32,32)transforms.ToTensor(), # 将图像转换为张量 Tensortransforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261))])# (2) 加载 CIFAR10 数据集batchsize = 128# 加载 CIFAR10 数据集, 如果 root 路径加载失败, 则自动在线下载# 加载 CIFAR10 训练数据集, 50000张训练图片train_set = torchvision.datasets.CIFAR10(root='', train=True,download=True, transform=transform_train)train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize)# 加载 CIFAR10 验证数据集, 10000张验证图片test_set = torchvision.datasets.CIFAR10(root='', train=False,download=True, transform=transform)test_loader = torch.utils.data.DataLoader(test_set, batch_size=1000)# 创建生成器,用 next 获取一个批次的数据valid_data_iter = iter(test_loader) # _SingleProcessDataLoaderIter 对象valid_images, valid_labels = next(valid_data_iter) # images: [batch,3,224,224], labels: [batch]valid_size = valid_labels.size(0) # 验证数据集大小,batchprint(valid_images.shape, valid_labels.shape)# 定义类别名称,CIFAR10 数据集的 10个类别classes = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')# (3) 从 torchvision.model 加载预定义模型 DenseNet (不加载模型权值)model = models.DenseNet(num_init_features=32, num_classes=10) # 实例化 DenseNet 模型类model.to(device) # 将网络分配到指定的 device中# print(model)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss() # 定义损失函数 CrossEntropyoptimizer = torch.optim.SGD(model.parameters(), momentum=0.8, lr=0.01) # 定义优化器 SGD# (4) 训练 DenseNet 网络模型epoch_list = [] # 记录训练轮次loss_list = [] # 记录训练集的损失值accu_list = [] # 记录验证集的准确率num_epochs = 99 # 训练轮次for epoch in range(num_epochs): # 训练轮次 epochrunning_loss = 0.0 # 每个轮次的累加损失值清零for step, data in enumerate(train_loader, start=0): # 迭代器加载数据optimizer.zero_grad() # 损失梯度清零inputs, labels = data # inputs: [batch,3,224,224] labels: [batch]outputs = model(inputs.to(device)) # 正向传播loss = criterion(outputs, labels.to(device)) # 计算损失函数loss.backward() # 反向传播optimizer.step() # 参数更新# 累加训练损失值running_loss += loss.item()# print("\t epoch {}, step {}: loss = {:.4f}".format(epoch, step, loss.item()))if step%100==99: # 每 100 个 step 打印一次训练信息print("\t epoch {}, step {}: loss = {:.4f}".format(epoch, step, loss.item()))# 计算每个轮次的验证集准确率with torch.no_grad(): # 验证过程, 不计算损失函数梯度outputs_valid = model(valid_images.to(device)) # 模型对验证集进行推理, [batch, 10]pred_labels = torch.max(outputs_valid, dim=1)[1] # 预测类别, [batch]accuracy = torch.eq(pred_labels, valid_labels.to(device)).sum().item() / valid_size * 100 # 计算准确率print("Epoch {}: train loss={:.4f}, accuracy={:.2f}%".format(epoch, running_loss, accuracy))# 记录训练过程的统计数据epoch_list.append(epoch) # 记录迭代次数loss_list.append(running_loss) # 记录训练集的损失函数accu_list.append(accuracy) # 记录验证集的准确率# 训练结果可视化plt.figure(figsize=(11, 5))plt.suptitle("DenseNet Model in CIFAR10")plt.subplot(121), plt.title("Train loss")plt.plot(epoch_list, loss_list)plt.xlabel('epoch'), plt.ylabel('loss')plt.subplot(122), plt.title("Valid accuracy")plt.plot(epoch_list, accu_list)plt.xlabel('epoch'), plt.ylabel('accuracy')plt.show()# 保存图像文件plt.savefig('/data/Users/wusy/myProject/efficient_densenet_pytorch-master/images')print("Plot saved to /data/Users/wusy/myProject/efficient_densenet_pytorch-master/images")# (5) 保存 DenseNet 网络模型save_path = "/data/Users/wusy/myProject/efficient_densenet_pytorch-master/dir1"#model_cpu = model.cpu() # 将模型移动到 CPUmodel_path = save_path + ".pth" # 模型文件路径torch.save(model.state_dict(), model_path) # 保存模型权值# 优化结果写入数据文件result_path = save_path + ".csv" # 优化结果文件路径WriteDataFile(epoch_list, loss_list, accu_list, result_path)
经过 20 轮左右的训练,使用验证集中的 1000 张图片进行验证,模型准确率达到 80%。继续训练可以进一步降低训练损失函数值,经过 100轮左右的训练验证集的准确率保持在 80%左右。
 ## 4.4测试阶段
## 4.4测试阶段
使用加载的 DenseNet 模型,输入新的图片进行模型推理,可以由模型输出结果确定输入图片所属的类别。从测试集中提取几张图片,或者读取图像文件,进行模型推理,获得图片的分类类别。在提取图片或读取文件时,要注意对图片格式和图片大小进行适当的转换。
从测试集中提取图片,结果如下:

读取图像文件,结果如下:

4.5测试代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import transforms, models
from matplotlib import pyplot as plt
import numpy as npdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检测并指定设备if __name__ == '__main__':device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)# (1) 将[0,1]的PILImage 转换为[-1,1]的Tensortransform_train = transforms.Compose([transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomRotation(10), # 随机旋转transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),transforms.Resize((32, 32)), # 图像大小调整为 (w,h)=(32,32)transforms.ToTensor(), # 将图像转换为张量 Tensortransforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261))])# 测试集不需要进行数据增强transform = transforms.Compose([transforms.Resize((32, 32)), # 图像大小调整为 (w,h)=(32,32)transforms.ToTensor(), # 将图像转换为张量 Tensortransforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261))])# (2) 加载 CIFAR10 数据集batchsize = 128# 加载 CIFAR10 数据集, 如果 root 路径加载失败, 则自动在线下载# 加载 CIFAR10 训练数据集, 50000张训练图片# 加载 CIFAR10 验证数据集, 10000张验证图片test_set = torchvision.datasets.CIFAR10(root='/cifar-10-python.tar.gz', train=False,download=True, transform=transform)test_loader = torch.utils.data.DataLoader(test_set, batch_size=1000)# 创建生成器,用 next 获取一个批次的数据valid_data_iter = iter(test_loader) # _SingleProcessDataLoaderIter 对象valid_images, valid_labels = next(valid_data_iter) # images: [batch,3,224,224], labels: [batch]valid_size = valid_labels.size(0) # 验证数据集大小,batchprint(valid_images.shape, valid_labels.shape)# 定义类别名称,CIFAR10 数据集的 10个类别classes = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')# (3) 从 torchvision.model 加载预定义模型 DenseNet (不加载模型权值)model = models.DenseNet(num_init_features=32, num_classes=10) # 实例化 DenseNet 模型类model.to(device) # 将网络分配到指定的 device中# print(model)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss() # 定义损失函数 CrossEntropyoptimizer = torch.optim.SGD(model.parameters(), momentum=0.8, lr=0.01) # 定义优化器 SGD# 加载 DenseNet 预训练模型# model = DenseNet(num_classes=10) # 实例化 DenseNet 网络模型model = models.DenseNet(num_init_features=32, num_classes=10) # 实例化 DenseNet 模型类model.to(device) # 将网络分配到指定的device中model_path = '/dir.pth'model.load_state_dict(torch.load(model_path))model.eval() # 模型推理模式# 模型检测
correct = 0
total = 0
for data in test_loader: # 迭代器加载测试数据集imgs, labels = data # torch.Size([batch,3,32,32) torch.Size([batch])# print(imgs.shape, labels.shape)outputs = model(imgs.to(device)) # 正向传播, 模型推理, [batch, 10]labels_pred = torch.max(outputs, dim=1)[1] # 模型预测的类别 [batch]# _, labels_pred = torch.max(outputs.data, 1)total += labels.size(0)correct += torch.eq(labels_pred, labels.to(device)).sum().item()
accuracy = 100. * correct / total
print("Test samples: {}".format(total))
print("Test accuracy={:.2f}%".format(accuracy))# 提取测试集图片进行模型推理
batch = 8 # 批次大小
data_set = torchvision.datasets.CIFAR10(root='/cifar-10-python.tar.gz', train=False, download=True, transform=None)
plt.figure(figsize=(9, 6))
for i in range(batch):imgPIL = data_set[i][0] # 提取 PIL 图片label = data_set[i][1] # 提取 图片标签# 预处理/模型推理/后处理imgTrans = transform(imgPIL) # 预处理变换, torch.Size([3,32,32])imgBatch = torch.unsqueeze(imgTrans, 0) # 转为批处理,torch.Size([batch=1,3,32,32])outputs = model(imgBatch.to(device)) # 模型推理, 返回 [batch=1, 10]indexes = torch.max(outputs, dim=1)[1] # 注意 [batch=1], device = 'deviceindex = indexes[0].item() # 预测类别,整数# 绘制第 i 张图片imgNP = np.array(imgPIL) # PIL -> Numpyout_text = "label:{}/model:{}".format(classes[label], classes[index])plt.subplot(2, 4, i+1)plt.imshow(imgNP)plt.title(out_text)plt.axis('off')
plt.tight_layout()
plt.show()
plt.savefig('/images1')# 读取图像文件进行模型推理
from PIL import Image
filePath = '' # 数据文件的地址和文件名
imgPIL = Image.open(filePath) # PIL 读取图像文件, <class 'PIL.Image.Image'># 预处理/模型推理/后处理
imgTrans = transform(imgPIL) # 预处理变换, torch.Size([3, 224, 224])
imgBatch = torch.unsqueeze(imgTrans, 0) # 转为批处理,torch.Size([batch=1, 3, 224, 224])
outputs = model(imgBatch.to(device)) # 模型推理, 返回 [batch=1, 10]
indexes = torch.max(outputs, dim=1)[1] # 注意 [batch=1], device = 'device
percentages = nn.functional.softmax(outputs, dim=1)[0] * 100
index = indexes[0].item() # 预测类别,整数
percent = percentages[index].item() # 预测类别的概率,浮点数# 绘制第 i 张图片
imgNP = np.array(imgPIL) # PIL -> Numpy
out_text = "Prediction:{}, {}, {:.2f}%".format(index, classes[index], percent)
print(out_text)
plt.imshow(imgNP)
plt.title(out_text)
plt.axis('off')
plt.tight_layout()
# 保存图像到指定路径
output_image_path = '/prediction_result.jpg'
plt.savefig(output_image_path, bbox_inches='tight', pad_inches=0)
plt.show()
参考链接
[1]DenseNet 模型-CIFAR10图像分类: http://t.csdnimg.cn/InzLt
[2]经典神经网络论文超详细解读: http://t.csdnimg.cn/jVmaw
这篇关于基于DenseNet网络实现Cifar-10数据集分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




