lda专题

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出
线性判别分析LDA算法
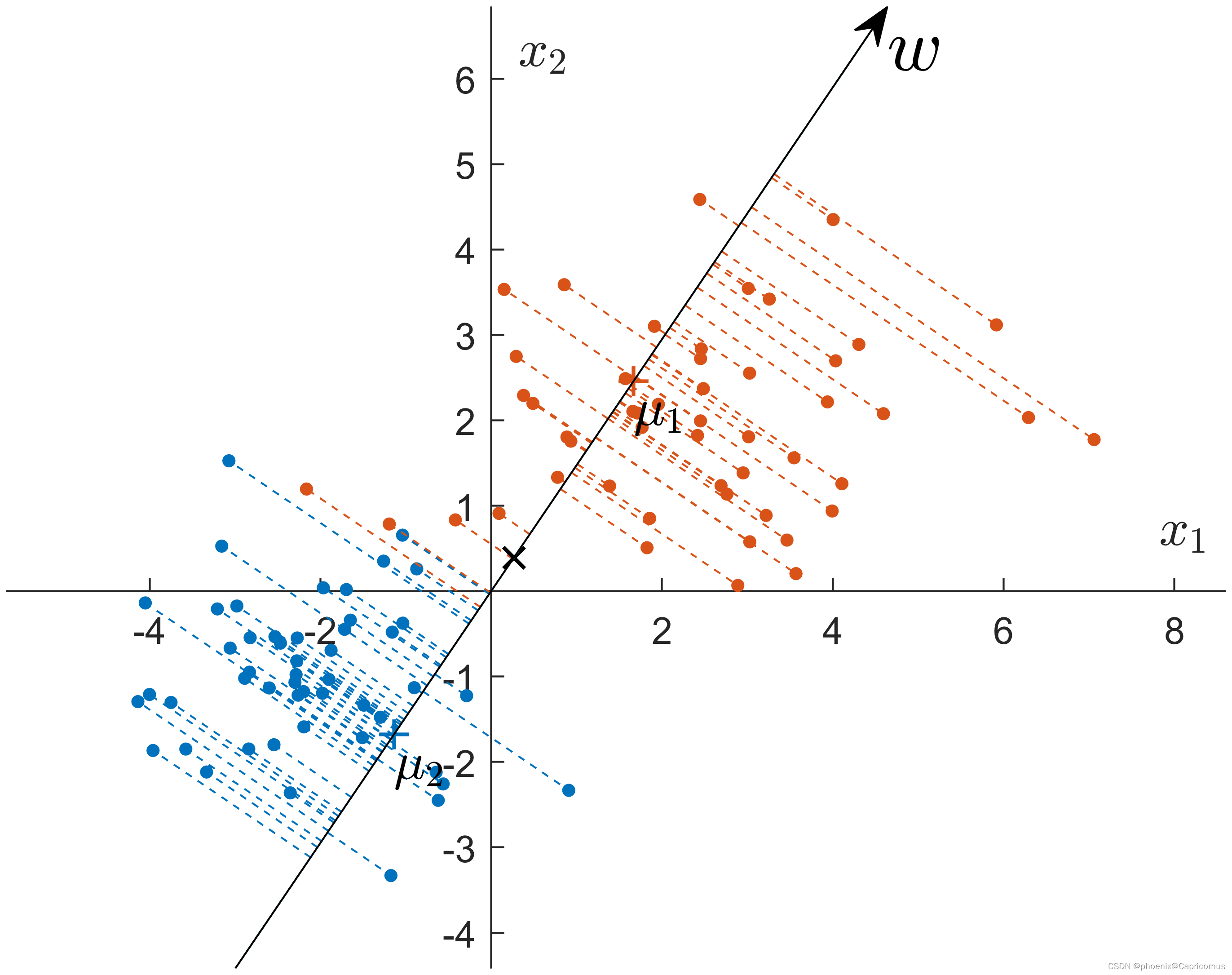
LDA算法入门 一. LDA算法概述: 线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引入模式识别和人工智能领域的。性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和

各种数据降维方法ICA、 ISOMAP、 LDA、LE、 LLE、MDS、 PCA、 KPCA、SPCA、SVD、 JADE
独立分量分析 ICA 等度量映射 ISOMAP 线性判别分析 LDA (拉普拉斯)数据降维方法 LE 局部线性嵌入 LLE 多维尺度变换MDS 主成分分析 PCA 核主成分分析 KPCA 稀疏主成分分析SPCA 奇异值分解SVD 特征矩阵的联合近似对角化 JADE 各种数据降维方法(matlab代码)代码获取戳此处代码获取戳此处 降维目的:克服维数灾难,获取本质特征,节省存储空

python实现线性判别分析 (LDA) 降维算法
目录 1.线性判别分析 (LDA) 降维算法的Python实现2.LDA算法的基本思想2.1类间方差矩阵 S B S_B SB2.2类内方差矩阵 S W S_W SW2.3优化目标 3.LDA的Python实现4.代码解析5.实际应用场景:手写数字识别5.1数据准备5.2使用LDA降维5.3分类效果 6.总结 1.线性判别分析 (LDA) 降维算法的Python实现

用Python解决分类问题_线性判别分析(LDA)模板
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的线性学习方法,属于监督学习,主要用于数据的分类和降维。LDA的目标是在特征空间中寻找一个最优的直线(或超平面),以区分不同的类别。它通过最大化类间差异和最小化类内差异来实现这一目标。LDA通常用于高维数据的降维,并且可以提高分类器的性能 。 LDA的数学原理涉及到瑞利商(Rayleigh quotie

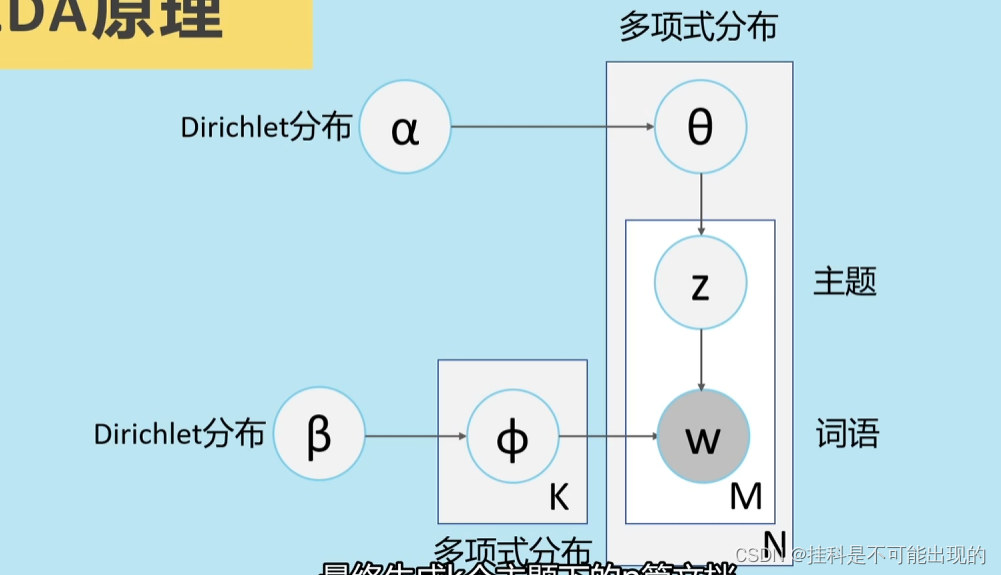
spark mllib 入门学习(二)--LDA文档主题模型
http://www.aboutyun.com/thread-22359-1-1.html 问题导读: 1.什么是LDA文档问题模型? 2.LDA 建模算法是什么样的? 3.spark MLlib中的LDA模型如何调优? 4.运行LDA有哪些小技巧? 上次我们简单介绍了聚类算法中的 KMeans算法 ,并且介绍了一个简单的KMeans的例
Spark MLlib LDA主题模型(1)
转http://blog.csdn.net/sunbow0/ Spark MLlib LDA主题模型是Spark1.3开始加入的,具体介绍看以下文档: 官方编程指南: http://spark.apache.org/docs/latest/mllib-clustering.html#latent-dirichlet-allocation-lda Spark MLlib LDA 简介: h
文本分类之降维技术之特征抽取之LDA线性判别分析
背景:为什么需要特征抽取? 基于的向量空间模型有个缺点,即向量空间中的每个关键词唯一地代表一个概念或语义单词,也就是说它不能处理同义词和多义词,然而实际情况是:一个词往往有多个不同的含义,多个不同的词可以代表一个概念。在这种情况下,基于的向量空间模型不能很好的解决这种问题。 特征抽取方法则可以看作从测量空间到特征空间的一种映射或变换,一般是通过构造一个特征评分函数,把测量空间的

基于某评论的TF-IDF下的LDA主题模型分析
完整代码: import numpy as npimport reimport pandas as pdimport jiebafrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.decomposition import LatentDirichletAllocationdf1 = pd.re
lda模型:官方处理方式和自己处理数据对比
自己处理数据,然后分批训练,第一步先对比自己处理的方式和官方是否一致。 官方的代码 import gensimfrom gensim import corporafrom gensim.models import LdaModel# 示例数据documents = ["Human machine interface for lab abc computer applications"
![[数智人文实战] 02.舆情分析之词云可视化、文本聚类和LDA主题模型文本挖掘](https://img-blog.csdnimg.cn/20200306163821515.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Vhc3Rtb3VudA==,size_16,color_FFFFFF,t_70#pic_center)
[数智人文实战] 02.舆情分析之词云可视化、文本聚类和LDA主题模型文本挖掘
【数智人文与文本挖掘】知识星球建立且正式运营,欢迎新老博友和朋友加入,一起分享更多数智人文知识和交流进步。该星球计划每周至少分享7个资源或文章,包括数智人文、文本挖掘、人工智能、大数据分析和图书情报的技术文章、代码及资源。同时,欢迎进入星球的朋友咨询我图情和AI人文技术、论文、求职、考研考博等问题,可以帮助大家修改一份简历(含考研、考博、求职),并给出真诚建议。感谢大家的支持,比较良心的星球,从

LDA(Latent Dirichlet Allocation)相关论文阅读小结
关于主题挖掘,LDA(Latent Dirichlet Allocation)已经得到了充分的应用。本文是我对自己读过的相关文章的总结。 1. 《LDA数学八卦》http://pan.baidu.com/s/18KUBG 把标准LDA的由来讲解得通俗易懂,细致入微。真的是了解LDA的最佳入门读物。 Gamma函数: 通过分部积分可以推导其具有递归性质 ,因此Gamma函数可以当成是阶乘在实

深入理解LDA和pLSA
主题模型LDA 在开始下面的旅程之前,先来总结下我们目前所得到的最主要的几个收获: 通过上文的第2.2节,我们知道beta分布是二项式分布的共轭先验概率分布: “对于非负实数和,我们有如下关系 其中对应的是二项分布的计数。针对于这种观测到的数据符合二项分布,参数的先验分布和后验分布都是Beta分布的情况,就是Beta-Binomia

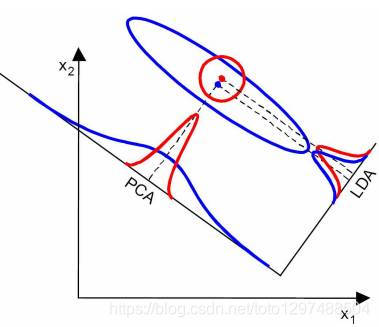
【16-降维技术:PCA与LDA在Scikit-learn中的应用】
文章目录 前言主成分分析(PCA)原理简介Scikit-learn中的PCA实现应用示例 线性判别分析(LDA)原理简介Scikit-learn中的LDA实现应用示例 总结 前言 降维是机器学习中一种常见的数据预处理方法,旨在减少数据集的特征数量,同时尽量保留原始数据集的重要信息。这不仅有助于减少计算资源的消耗,还能在一定程度上改善模型的性能。在Scikit-learn

python笔记:gensim进行LDA
理论部分:NLP 笔记:Latent Dirichlet Allocation (介绍篇)-CSDN博客 参考内容:DengYangyong/LDA_gensim: 用gensim训练LDA模型,进行新闻文本主题分析 (github.com) 1 导入库 import jieba,os,refrom gensim import corpora, models, similarities

[机器学习] 第三章 线性模型 1.线性回归 逻辑回归 线性判别分析LDA
参考:西瓜书,葫芦书 参考:https://www.cnblogs.com/LittleHann/p/10498579.html#_lab2_0_0 katex:https://www.pianshen.com/article/82691450250/ latex:https://www.cnblogs.com/veagau/articles/11733769.html 参考:https://bl

07_数据降维,降维算法,主成分分析PCA,NMF,线性判别分析LDA
1、降维介绍 保证数据所具有的代表性特性或分布的情况下,将高维数据转化为低维数据。 聚类和分类都是无监督学习的典型任务,任务之间存在关联,比如某些高维数据的分类可以通过降维处理更好的获得。 降维过程可以被理解为数据集的组成成分进行分解(decomposition)的过程,因此sklearn为降维模块命名为decomposition。在对降维算法调用需要使用sklearn.decomposit

LDA理论、变形、优化、应用、工具库
原文地址:http://site.douban.com/204776/widget/notes/12599608/note/287085506/ 2013-07-08 19:22:18 http://www.douban.com/note/287085419/ 啥了不说了,这几天简直成魔了。 自己的LDA框架也整理好了,接下来重新梳理一遍这边就算任督二脉打通啦! #

基于豆瓣影评数据的文本分析系统【数据爬取+数据清洗+数据库存储+LDA主题挖掘+词云可视化】
本分析中很多的工作都是基于评论数据来进行的,比如:滴滴出行的评价数据、租房的评价数据、电影的评论数据等等,从这些语料数据中能够挖掘出来客户群体对于某种事物或者事情的看法,较为常见的工作有:舆情分析、热点挖掘和情感分析。 如果想要了解关于文本分类或者是情感分析相关的工作内容,可以阅读我的《数据建模实战》专栏文章,下面是链接信息:


独家 | 使用Python的LDA主题建模(附链接)
作者:Kamil Polak翻译:刘思婧校对:孙韬淳本文约2700字,建议阅读5分钟本文为大家介绍了主题建模的概念、LDA算法的原理,示例了如何使用Python建立一个基础的LDA主题模型,并使用pyLDAvis对主题进行可视化。 图片来源:Kamil Polak 引言 主题建模包括从文档术语中提取特征,并使用数学结构和框架(如矩阵分解和奇异值分解)来生成彼此可区分的术语聚类(clust

Python数据分析案例39——电商直播间评论可视化分析(LDA)
1. 引言 1.1 直播电商的发展背景 随着互联网技术的飞速发展,电商行业迎来了新的变革——直播电商。直播电商是一种结合了直播技术和电子商务的新型销售模式。在这种模式下,商家或主播通过实时视频直播的方式,展示产品并与消费者互动,促进产品销售。这种新兴的电商形式因其独特的互动性和即时性,在短时间内迅速发展并受到了消费者的广泛欢迎。 1.2 研究的重要性与目的 直播电商的快速发展不仅改变了传统