本文主要是介绍机器学习算法模型评价指标ROC AUC,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【导读】在机器学习研究或项目中使用分类精度、均方误差这些方法衡量模型的性能。当然,在进行实验的时候,一种或两种衡量指标并不能说明一个模型的好坏,因此我们需要了解常用的几种机器学习算法衡量指标。 本文整理介绍了7种最常用的机器学习算法衡量指标:分类精度、对数损失、混淆矩阵、曲线下面积、F1分数、平均绝对误差、均方误差。相信阅读之后你能对这些指标有系统的理解。
1.分类精度
当我们使用“准确性”这个术语时,指的就是分类精度。它是 正确预测数 与 样本总数 的比值。
只有当属于每个类的样本数量相等时,它才有效。
例如,假设在我们的训练集中有98%的A类样本和2%的B类样本。然后,我们的模型可以通过简单预测每个训练样本都属于A类而轻松获得98%的训练准确性。
当在60%A级样品和40%B级样品的测试集上采用相同的模型时,测试精度将下降到60%。分类准确度很重要,但是它有时会带给我们一种错觉,使我们认为模型已经很好。真正的问题出现在,当少量样本类被误分类造成很大的损失的情况下。
1.诊断罕见但致命
如果我们处理一种 罕见但致命 的疾病,那么 真正的患者未被诊断出疾病 的造成的损失远高于 健康人未被诊断出疾病。
2. 地震的预测
对于地震的预测,我们希望的是Recall 非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
2.对数损失
对数损失,通过惩罚错误的分类来工作,它适用于多类分类。在处理对数损失时,分类器必须为所有样本分配属于每个类的概率。假设,有N个样本属于M类,那么对数损失的计算如下:
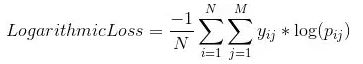
其中,yij 表示样本i是否属于类别 j,Pij表示样本i属于类j的概率
对数损失的值没有上限,它取值于[0,∞)范围内。对数损失接近0表示其有高的准确性,而如果对数损失远离0则表明准确度较低。
一般来说,最大限度地减少对数损失可以提高分类精度。(在模型训练时,经常最小化对数损失)
3.混淆矩阵
混淆矩阵顾名思义,通过一个矩阵描述了模型的完整性能。
假设我们有一个二元分类问题。我们有一些样本,它们只属于两个类别:是或否。另外,我们有自己的分类器,它用来预测给定输入样本的类。我们在样品上测试了我们的模型,得到了如下结果:
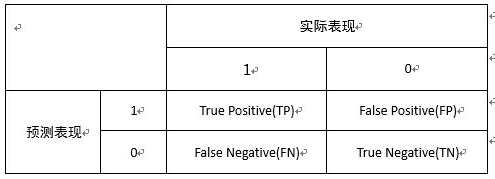
有四个重要的术语:
真阳(True Positives,TP): 模型预测“是”并且实际产出也是“是” 的情况
真阴(True Negatives,TN):模型预测“否”并且实际产出也是“是”的情况
假阳(False Positives,FP):模型预测“是”并且实际产出也是“否”的情况
假阴(False Negatives,FN): 模型预测“否”并且实际产出也是“否”的情况
精确率(precision):

召回率(recall):
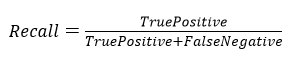
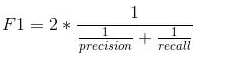
F1: F1分数用于衡量测试的准确性。
F1分数是精确度和召回率之间的调和平均值(Harmonic Mean)。 F1分数的范围是[0,1]。 它会告诉您分类器的精确程度(正确分类的实例数),以及它的稳健程度(它不会错过大量实例)。高精度和低召回率,会带来高的精度,但也会错过了很多很难分类的实例。 F1得分越高,我们模型的表现越好。 在数学上,它可以表示为:
可以看出,混淆矩阵是其他度量类型的基础。
4.ROC曲线(ROC curve)
用于度量分类中的非均衡性的工具是ROC曲线,ROC代表接收者操作特征(receiver operating characteristic),它最早在二战期间由电气工程师构建雷达系统时使用过。

一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting(比如图中绿线25到50可能就有问题,但是样本太少了),这个时候调模型可以只看AUC,面积越大一般认为模型越好。
True Positive Rate (真阳性率):它被定义为TP /(FN + TP)。 对于所有正数据点,它对应于正数据点被正确认为是正的比例。
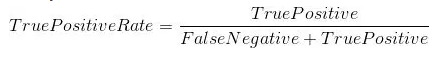
False Positive Rate (假阳性率) :它被定为FP /(FP + TN)。即对应于所有负数据点,负数据点被错误地认为是正的比例。
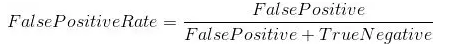
如图ROC曲线给出了两条线,一条虚线和一条实线。图中横轴是假阳率(FPR),纵轴是真阳率(TPR).ROC曲线给出的是当阈值变化时假阳率和真阳率的变化情况。左下角的点所对应的是将所有样例判为反例的情况,而右上角的点对应的则是将所有样例判为正例的情况。虚线 给出的是 随机猜测 的结果曲线。
理想情况下,最佳分类器应该尽可能地处于左上角,这就意味着分类器在假阳率很低的同时获得了很高真阳率 。
5.曲线下的面积(Area Under Curve, AUC)
对不同的ROC曲线进行比较的一个指标是曲线下的面积(Area Under Curve,AUC),曲线下面积(AUC)是评估中使用最广泛的指标之一。 它用于二分类问题。分类器的AUC等价于分类器随机选择正样本高于随机选择负样本的概率。 在定义AUC之前,让我们理解两个基本术语:
AUC(Area Under Curve)的值为ROC曲线下面的面积,若如上所述模型十分准确,则AUC为1。
但现实生活中尤其是工业界不会有如此完美的模型,一般AUC均在0.5到1之间,AUC越高,模型的区分能力越好
若AUC=0.5,即与上图中虚线重合,表示模型的区分能力与 随机猜测 没有差别。若AUC真的小于0.5,请检查一下是不是好坏标签标反了,或者是模型真的很差。
6.平均绝对误差
平均绝对误差是原始值与预测值之差的平均值。 它衡量预测与实际输出还差多远。 但是,它们并没有给我们提供任何关于错误方向的信息,即不能给出我们的模型到底是低于预测数据还是高于预测数据。 在数学上,它表示为:
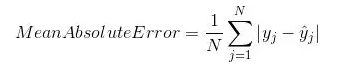
7.均方误差(MSE)
均方误差(MSE)与平均绝对误差非常相似,唯一的区别是MSE取原始值与预测值之差的平方的平均值。 MSE的优点是计算梯度更容易,而平均绝对误差需要复杂的线性编程工具来计算梯度。 由于我们采用误差的平方,更大的误差的影响变得更明显,因此模型现在可以更多地关注更大的误差。
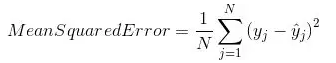
这篇关于机器学习算法模型评价指标ROC AUC的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




