本文主要是介绍基于灰狼优化算法优化RBF神经网络(GWO-RBF)的数据回归预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码原理及流程
基于灰狼优化算法优化RBF神经网络的数据回归预测,可以分为以下步骤:
1. 数据准备:首先,准备用于回归预测的数据集,包括输入特征和对应的输出目标。
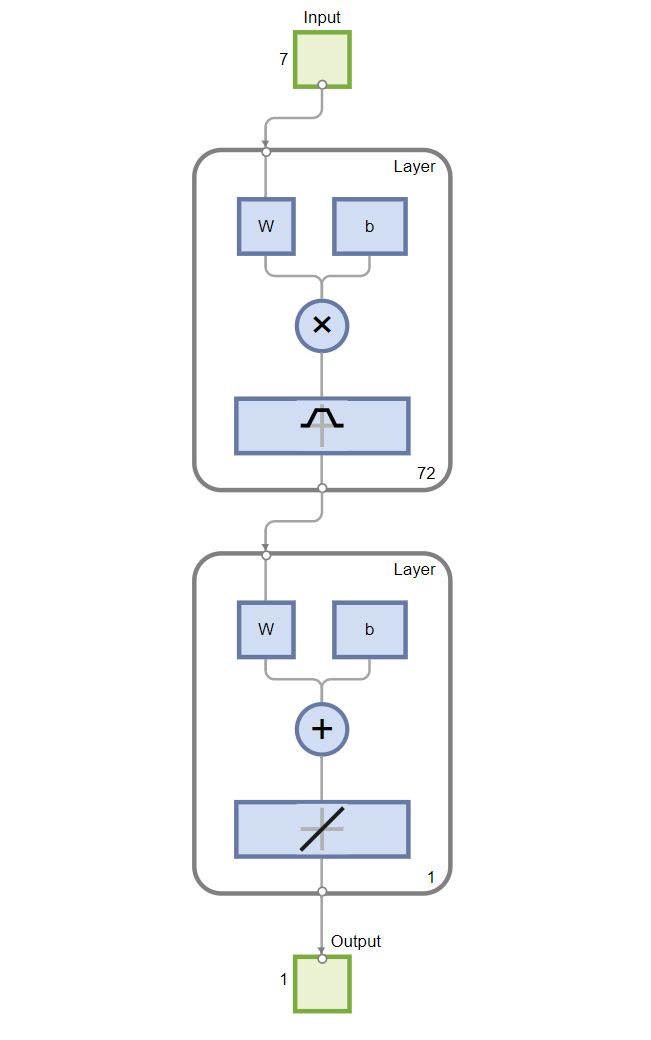
2. RBF神经网络的初始化:初始化RBF神经网络的参数,包括中心点(centers)、径向基函数的宽度(标准差)和输出层的权重。
3. 灰狼优化算法的初始化:初始化灰狼优化算法的参数,包括种群大小、迭代次数、搜索范围等。
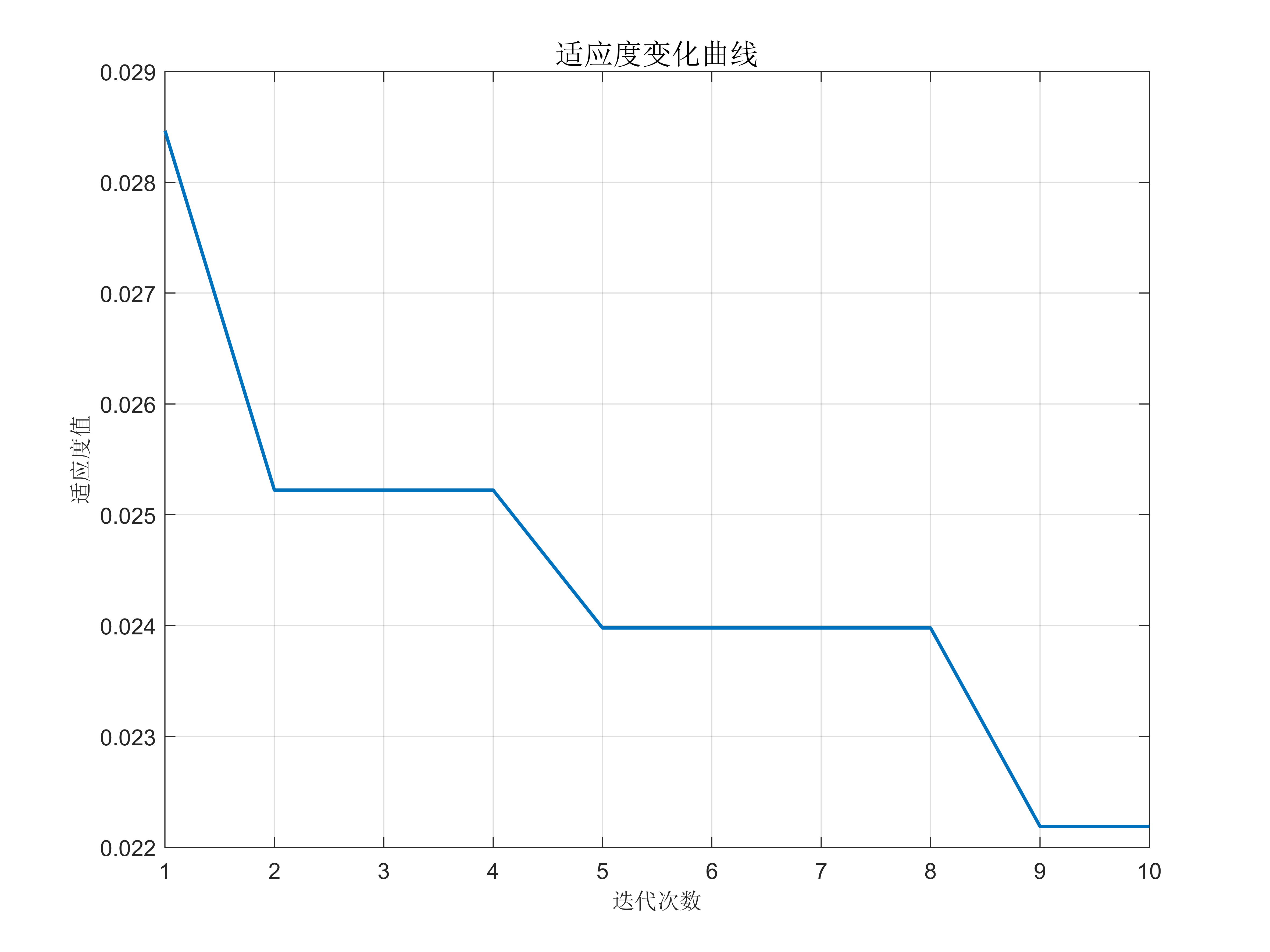
4. 灰狼优化算法的优化过程:在每一代中,通过灰狼优化算法更新RBF神经网络的参数。在更新过程中,根据灰狼群体中的每只灰狼的位置,计算适应度(损失函数值),然后更新参数以寻找最优解。
5. 灰狼优化算法结束条件:当达到设定的迭代次数或满足收敛条件时,停止优化算法,并得到优化后的RBF神经网络参数。
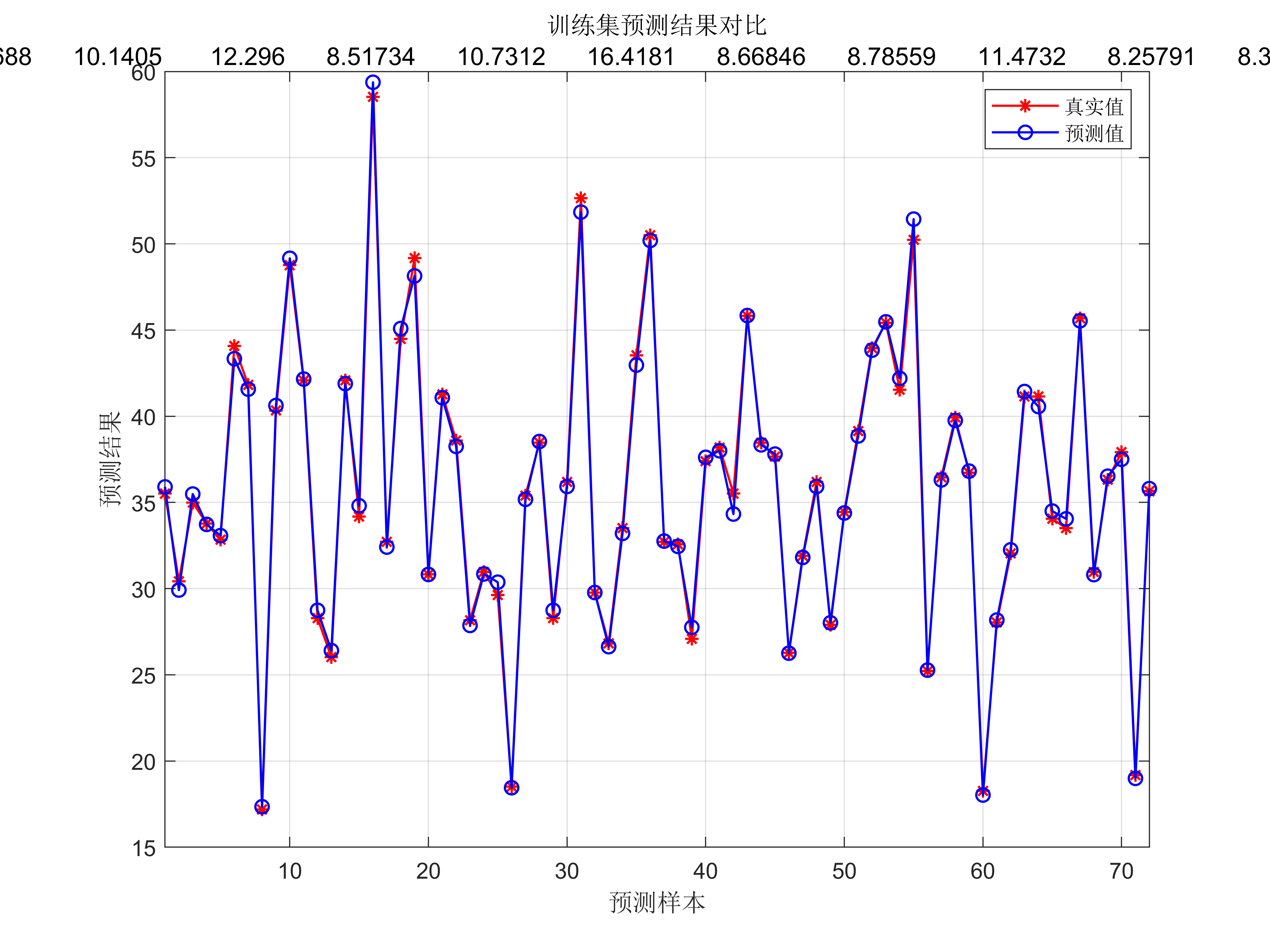
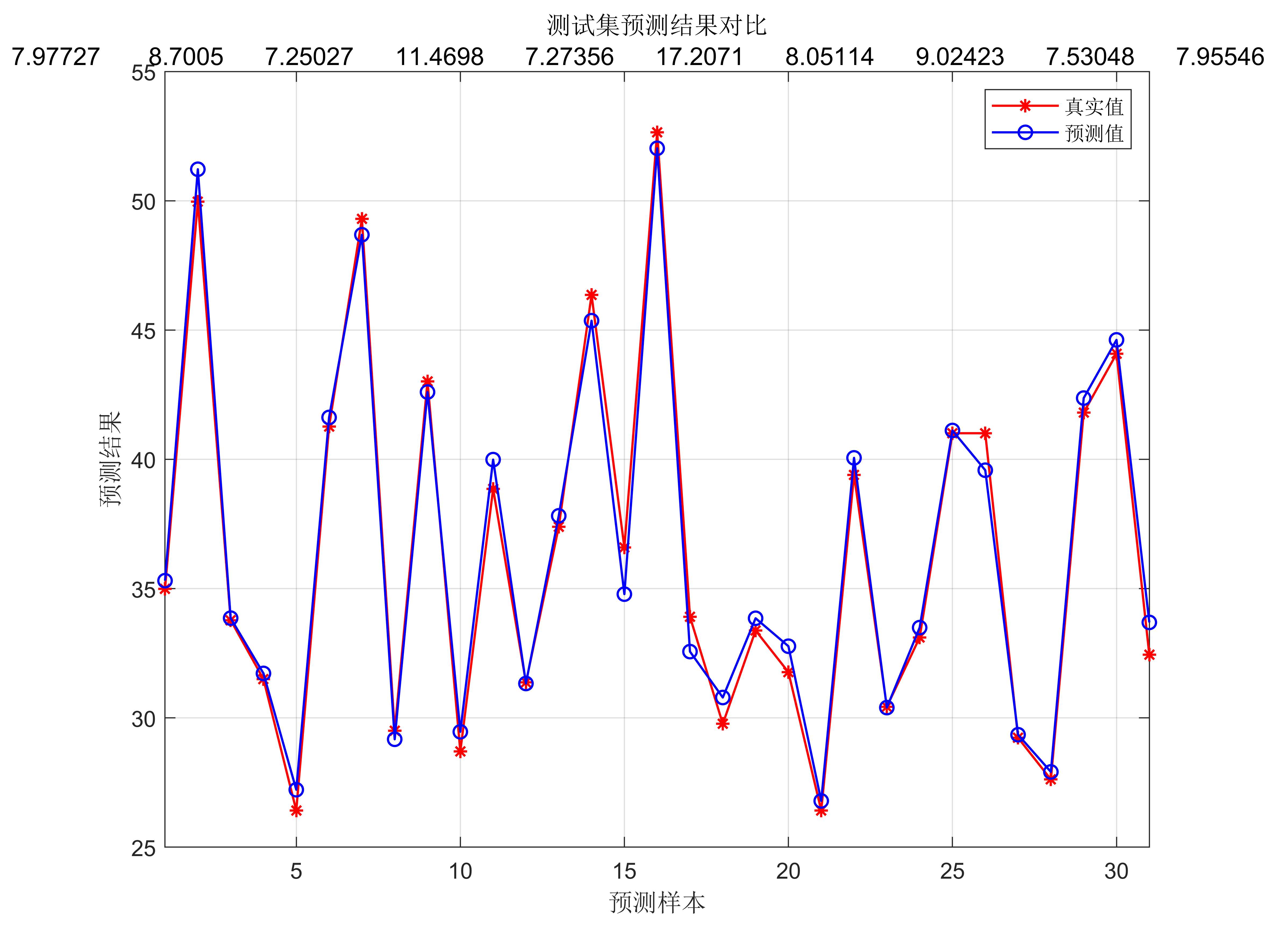
6. 模型预测:使用优化后的RBF神经网络模型进行数据回归预测,计算预测结果。
整体流程是将灰狼优化算法与RBF神经网络结合,利用灰狼优化算法寻找最佳的RBF神经网络参数,以实现更准确的回归预测效果。在实际的代码实现中,需要编写灰狼优化算法和RBF神经网络的代码,并将它们结合起来进行优化和预测。
代码效果图
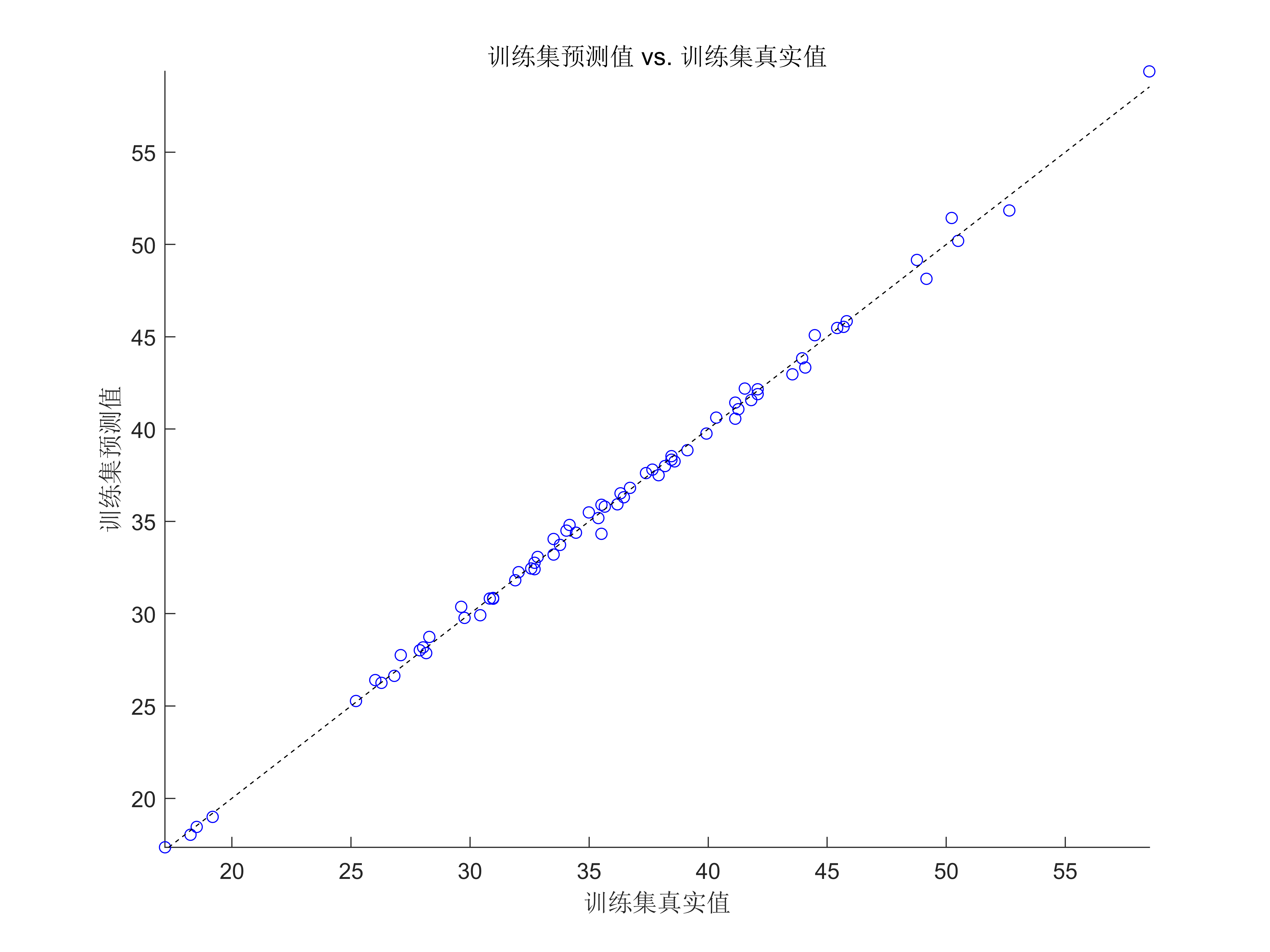
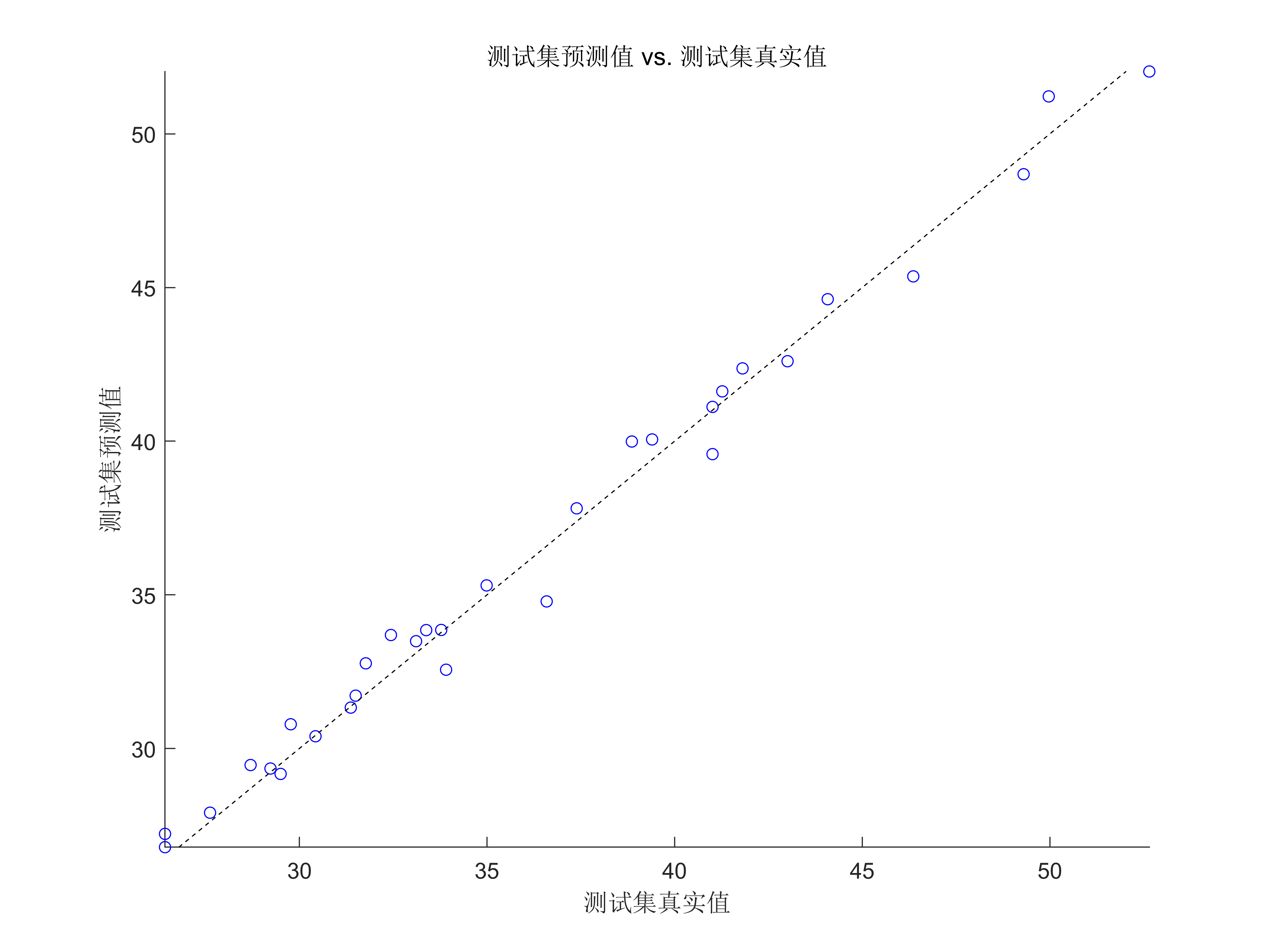
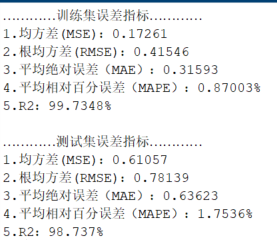
获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),并回复智能优化算法优化RBF本公众号致力于解决找代码难,写代码怵。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。
这篇关于基于灰狼优化算法优化RBF神经网络(GWO-RBF)的数据回归预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



