本文主要是介绍Apache Flink CDC 3.1.0版本知识学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Apache Flink CDC 3.1.0版本知识学习
- 一、Flink CDC 3.1 快速预览
- 二、Transformation 支持
- 三、分库分表合并支持
- 四、使用 Kafka Pipeline Sink 高效写入 Canal/Debezium 格式数据
- 五、更高效地实时入湖 Paimon
- 六、其他改进
- 七、Flink CDC 3.1 版本兼容性
一、Flink CDC 3.1 快速预览
作为 Flink CDC 成为 Apache Flink 子项目之后的首个版本,3.1 带来了许多新功能与稳定性提升。主要亮点包括:
- Transformation 支持:通过 YAML 管道定义中的 transform 部分,用户可以对数据变化事件进行投影、计算和添加常量列等转化,使用类似 SQL 的语法,提升数据集成管道的灵活性。
- 分库分表合并支持:可以通过在 YAML 管道定义中配置路由将多个表合并到一个目标表,自动处理业务数据在不同表或数据库的分区及源表的 schema 变化。
- 新连接器:引入了新的 Apache Kafka 和 Apache Paimon 的 Pipeline Sink,增强了生态系统的扩展性,其中Kafka Sink 使得用户可以发送原始Debeizum/ Canal Json 格式的CDC数据到消息队列,Paimon Sink 则是让用户可以简单高效地完成MySQL实时入湖。
- 连接器改进:如 MySQL 增加了 tables.exclude 选项和 MysqlDebeziumTimeConverter,OceanBase 支持 DebeziumDeserializationSchema,Db2 迁移到统一增量快照框架等。
二、Transformation 支持
Flink CDC 3.1.0 引入了在 CDC pipeline 中进行数据变换(transformation)的功能。通过在 YAML pipeline 定义中加入 transform 部分,用户现在可以轻松地对来源的数据变更事件应用各种变换,包括投影、计算和添加常量列,从而提高数据集成管道的效率。新特性利用类似 SQL 的语法定义这些转换,确保用户可以快速适应并使用它。例如,只需编写如下 YAML 语句块:
transform:- source-table: db.tbl1projection: id, age, weight, height, weight / (height * height) as bmifilter: age > 18 AND name IS NOT NULL
即可对传递的数据流应用投影操作(仅保留原表中的部分列)、计算操作(根据原列数据计算新列并追加到数据记录中)和过滤操作(从结果中清除符合条件的数据行)。可以书写多条 Transform 规则,它们会同时生效。
三、分库分表合并支持
Flink CDC 3.1.0 现在通过在 YAML pipeline 定义中配置 route,在分库分表场景下将多表合并为一个。由于业务数据量庞大,业务数据经常会被分别存放在多个表甚至数据库中。通过配置route,用户可以将多张源表映射至同一个目标表,在同步时,数据变更事件(DataChangeEvent)和 Schema 变更事件都将被合并到指定的目标表中。例如,只需编写如下 YAML 语句块:
route:- source-table: db.tbl\.*sink-table: db.unified- source-table: db.tbl_log\.*sink-table: db.log
即可将源库中所有匹配 tbl.*和 tbl_log.*正则表达式的分片表合并,并分别同步到下游的 db.unified和 db.log汇表中。(.用于分隔数据库名称和表名称,因此作为正则表达式关键字时需要使用 \进行转义。)可以书写多条 Route 规则,它们会同时生效。
四、使用 Kafka Pipeline Sink 高效写入 Canal/Debezium 格式数据
source:type: mysql# ...sink:type: kafkaproperties.bootstrap.servers: PLAINTEXT://localhost:62510value.format: canal-json
该作业将来自 MySQL 上游的变化数据编码为 Canal JSON 格式,并写入到指定的 Kafka 服务器中;相比于 Flink SQL Changelog 格式,Flink CDC 不会将数据更新事件拆分为 BEFORE 和 AFTER 两条记录,能够更高效地处理分区表场景,并支持将事件序列化为 Debezium 和 Canal JSON 格式。
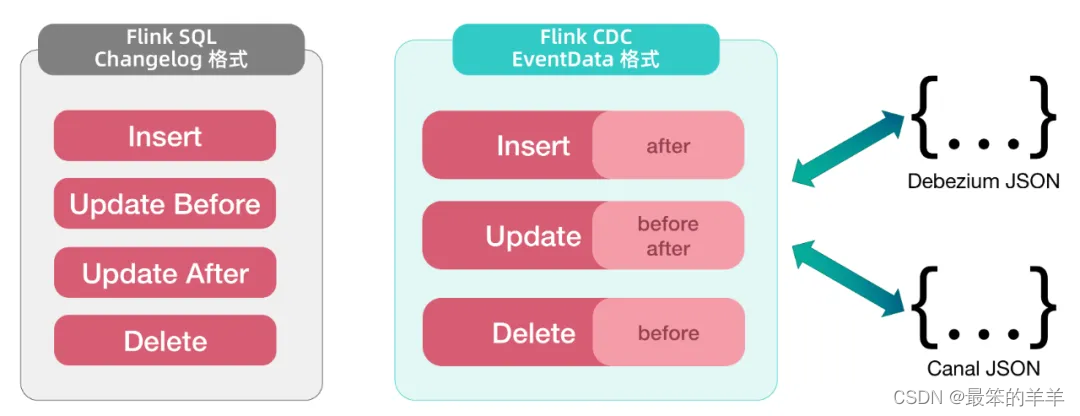
Flink 支持将上述格式解析为标准变更消息处理,因此您可以简单地使用以下 Flink SQL 将其摄入流式处理框架,整个过程无需额外部署 Canal 或 Debezium 集群,直接复用已有 Flink 集群即可:
CREATE TABLE topic_products (-- 上游的 Schema 结构
) WITH ('connector' = 'kafka',-- ...'properties.bootstrap.servers' = 'localhost:9092','format' = 'canal-json' -- 从 Kafka 摄取 Canal JSON 格式数据
)
完整的数据流示意图如下所示:

五、更高效地实时入湖 Paimon
Flink CDC 3.1.0 引入了新的 Apache Paimon Pipeline Sink(基于 Paimon 0.7.0 版本)。现在,您可以编写如下所示的 YAML 语句块来定义一个从 MySQL 捕获变化数据并写入下游 Paimon Sink 的 Pipeline 作业:
source:type: mysql# ...sink:type: paimoncatalog.properties.metastore: filesystemcatalog.properties.warehouse: /path/warehouse
可选择的下游元数据存储支持 FileSystem 和 Hive。在启用 Schema Evolution 选项时,Flink CDC 会同时捕获数据变更和表结构变更、在应用 Transform 和 Route 规则后将数据发送到下游,并将结构变更应用到 Catalog 中。完整的数据流示意图如下所示:
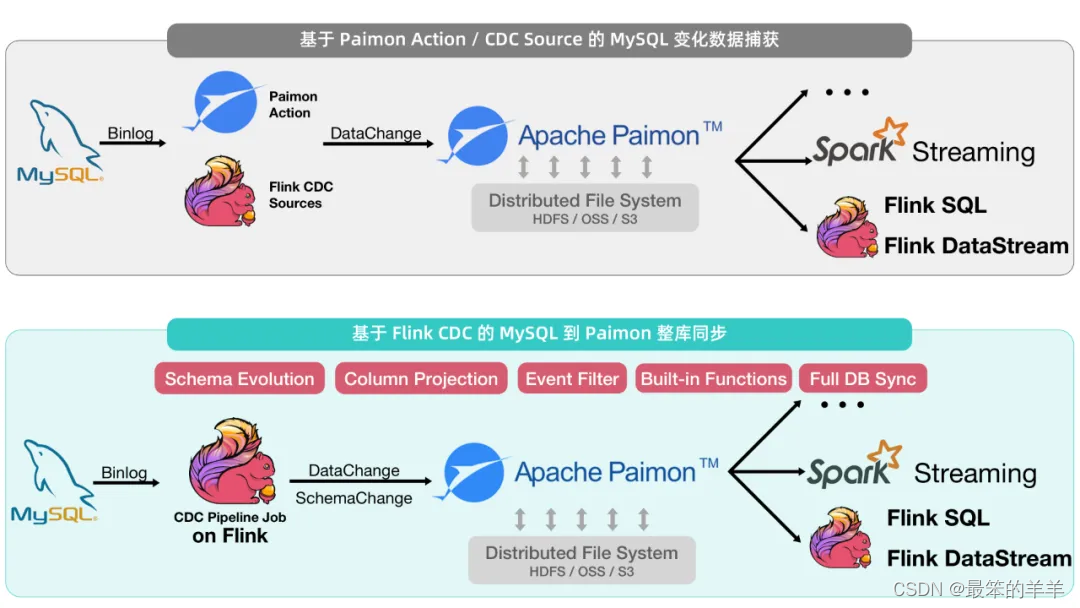
相比于使用 Flink SQL 和 Paimon CDC Action 的同步方案,Flink CDC Pipeline 作业支持将上游表结构变更动态应用至下游,且进一步支持了对上游表进行列投影和行过滤,提供细粒度的数据路由规则,追加计算列的逻辑配置更加简单。例如,以下 Paimon Action 变换语句:
flink run paimon-action.jar--metadata_column "table_name"--computed_column "name=UPPER(name)"--computed_column "nameage=CONCAT(name, age)"
可以使用 Flink CDC YAML 等效地表述为:
projection: \*, __table_name__, UPPER(name) as newage, CONCAT(name, age) as nam
六、其他改进
(1)MySQL Pipeline 连接器
在此版本中,MySQL pipeline source 引入了一个新的选项 tables.exclude,用户可以更简单地使用正则表达式排除不必要的表。
(2)MySQL Source 连接器
MySQL CDC source 同时新增了一个自定义转换器 MysqlDebeziumTimeConverter,用于将时间类型列转换为更易于读取和序列化的字符串。
(3)OceanBase Source 连接器
OceanBase CDC source 现在支持指定通用的 DebeziumDeserializationSchema,以重用现有的 Debezium 反序列化器。
(4)Db2 Source 连接器
Db2 CDC source 已经迁移至统一的增量快照框架。
(5)SinkFunction 支持
尽管 SinkFunction 在 Flink 中已被标记为弃用,但考虑到一些 Flink connector 仍在使用该 API,我们也为 CDC pipeline sink 支持 SinkFunction API 以帮助扩展 Flink CDC 的生态系统。
(6)CLI 支持从 savepoint 恢复
Flink CDC pipeline 提交 CLI 现在支持通过命令行参数 --from-savepoint 从特定的 savepoint 文件恢复 Flink 作业。
七、Flink CDC 3.1 版本兼容性
4.1 Group ID 和 Package 路径变更
如果正通过 Maven 或 Gradle 声明 Flink CDC 依赖,则需要在升级到 3.1 版本的同时将 Group ID 从 com.ververica.cdc改为 org.apache.flink.cdc,同时更改源代码中 import Package 路径。
4.2 用于 Flink SQL 作业的 Flink Source 连接器的重要更改
由于许可证与 Apache 2.0 License 不兼容,我们无法将以下连接器的 JDBC driver 包含在我们的二进制发布包中:
- Db2
- MySQL
- Oracle
- OceanBase
请手动将相应的 JDBC 驱动程序下载到 Flink 集群的 $FLINK_HOME/lib 目录中,或在使用 --jar 提交 YAML pipeline 时指定驱动程序的路径。如果您在使用 Flink SQL,请确保它们在 classpath 下。
4.3 作业 State 兼容性
由于以上不兼容的变更,使用 Flink CDC 3.1 以前版本保存的作业 State 无法在较新版本上恢复。因此,您需要在升级 Flink CDC 版本后进行一次无状态重启。
附上官方发布连接:
- Apache Flink CDC 3.1.0 发布公告
这篇关于Apache Flink CDC 3.1.0版本知识学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




