本文主要是介绍处理Mini-ImageNet数据集,用于分类任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Mini-ImageNet数据集介绍
ImageNet 1000类的数据太大了,全部下载大概有100GB左右。
2016年google DeepMind团队从ImagNet数据集中抽取的一小部分(大小约3GB)制作了Mini-ImageNet数据集,共有100个类别,每个类别有600张图片,共6w张(都是.jpg结尾的文件),而且图像的大小并不是固定的,作为小样本学习(Few-shot Learning)常用数据集。
训练,验证,测试数据集中的类别不交叉重复。基础集(Base Class,64个类别),验证集(Validation Class,16个类别)和新类别集(Novel Class,20个类别)。
1、数据集结构
├── mini-imagenet: 数据集根目录├── images: 所有的图片都存在这个文件夹中├── train.csv: 对应训练集的标签文件├── val.csv: 对应验证集的标签文件└── test.csv: 对应测试集的标签文件2、数据集下载
百度网盘链接
下载地址:https://pan.baidu.com/s/1bQTtrkEgWfs_iaVRwxPF3Q
提取码:33e7
标签对应类别名json文件下载
imagenet_class_index.json文件是每个类别对应的实际物体名称,这个文件是ImageNet1000类数据集中对应的标签文件。
imagenet_class_index.json文件部分内容如下,n01440764标签对应类别为tench。
{"0": ["n01440764", "tench"], "1": ["n01443537", "goldfish"], "2": ["n01484850", "great_white_shark"],...
}ImageNet数据集风格——WordNet层次结构
ImageNet是是目前深度学习图像领域应用得非常多的,根据WordNet层次结构组织的图像数据集,由李飞飞团队创建,目前常用的是2012年版本的。
官网链接下载需要教育邮箱登录。
WordNet层次结构,文件夹名为类别名,文件夹下是该类别的所有图片,如下所示,实际更加复杂,可嵌套很多层。
ImageNet
│
├── Dog
│ ├── img_dog_0001.jpg
│ ├── img_dog_0002.jpg
│ ├── ...
├── Cat
│ ├── img_cat_0001.jpg
│ ├── img_cat_0002.jpg
│ ├── ...
└── ...
二、python处理数据集为分类数据集
1、文件目录结构
├── data
│ ├── images
│ ├── train.csv
│ ├── val.csv
│ ├── test.csv
│ └── imagenet_class_index.json
│
├── classification_process.py
└── dataset_process.py 2、classification_process.py
划分出新的CSV文件和json文件:new_train.csv 、new_val.csv、classes_name.json。
import os
import json
import pandas as pd
from PIL import Image
import matplotlib.pyplot as pltdef read_csv_classes(csv_dir: str, csv_name: str):data = pd.read_csv(os.path.join(csv_dir, csv_name))label_set = set(data["label"].drop_duplicates().values)print("{} have {} images and {} classes.".format(csv_name,data.shape[0],len(label_set)))return data, label_setdef calculate_split_info(path: str, label_dict: dict, rate: float = 0.2):# read all imagesimage_dir = os.path.join(path, "images")images_list = [i for i in os.listdir(image_dir) if i.endswith(".jpg")]print("find {} images in dataset.".format(len(images_list)))train_data, train_label = read_csv_classes(path, "train.csv")val_data, val_label = read_csv_classes(path, "val.csv")test_data, test_label = read_csv_classes(path, "test.csv")# Union operationlabels = (train_label | val_label | test_label)labels = list(labels)labels.sort()print("all classes: {}".format(len(labels)))# create classes_name.jsonclasses_label = dict([(label, [index, label_dict[label]]) for index, label in enumerate(labels)])json_str = json.dumps(classes_label, indent=4)with open('data/classes_name.json', 'w') as json_file:json_file.write(json_str)# concat csv datadata = pd.concat([train_data, val_data, test_data], axis=0)print("total data shape: {}".format(data.shape))# split data on every classesnum_every_classes = []split_train_data = []split_val_data = []for label in labels:class_data = data[data["label"] == label]num_every_classes.append(class_data.shape[0])# shuffleshuffle_data = class_data.sample(frac=1, random_state=1)num_train_sample = int(class_data.shape[0] * (1 - rate))split_train_data.append(shuffle_data[:num_train_sample])split_val_data.append(shuffle_data[num_train_sample:])# imshowimshow_flag = Falseif imshow_flag:img_name, img_label = shuffle_data.iloc[0].valuesimg = Image.open(os.path.join(image_dir, img_name))plt.imshow(img)plt.title("class: " + classes_label[img_label][1])plt.show()# plot classes distributionplot_flag = Falseif plot_flag:plt.bar(range(1, 101), num_every_classes, align='center')plt.show()# concatenate datanew_train_data = pd.concat(split_train_data, axis=0)new_val_data = pd.concat(split_val_data, axis=0)# save new csv datanew_train_data.to_csv(os.path.join(path, "new_train.csv"))new_val_data.to_csv(os.path.join(path, "new_val.csv"))def main():data_dir = "data/" # 指向数据集的根目录json_path = "data/imagenet_class_index.json" # 指向imagenet的索引标签文件# load imagenet labelslabel_dict = json.load(open(json_path, "r"))label_dict = dict([(v[0], v[1]) for k, v in label_dict.items()])calculate_split_info(data_dir, label_dict)if __name__ == '__main__':main()3、dataset_process.py
利用划分出的新文件将图片按照ImageNet风格进行划分。
import csv
import os
from PIL import Image
import jsontrain_csv_path = "data/new_train.csv"
val_csv_path = "data/new_val.csv"json_path = "data/classes_name.json"
label_dict = json.load(open(json_path, "r"))train_label = {}
val_label = {}with open(train_csv_path) as csvfile:csv_reader = csv.reader(csvfile)birth_header = next(csv_reader)for row in csv_reader:train_label[row[1]] = label_dict[row[2]][1]with open(val_csv_path) as csvfile:csv_reader = csv.reader(csvfile)birth_header = next(csv_reader)for row in csv_reader:val_label[row[1]] = label_dict[row[2]][1]img_path = "data/images"
new_img_path = "data/mini-imagenet"
for png in os.listdir(img_path):path = img_path + '/' + pngim = Image.open(path)if (png in train_label.keys()):tmp = train_label[png]temp_path = new_img_path + '/train' + '/' + tmpif (os.path.exists(temp_path) == False):os.makedirs(temp_path)t = temp_path + '/' + pngim.save(t)elif (png in val_label.keys()):tmp = val_label[png]temp_path = new_img_path + '/val' + '/' + tmpif (os.path.exists(temp_path) == False):os.makedirs(temp_path)t = temp_path + '/' + pngim.save(t)4、最终目录结构
├── data
│ ├── images
│ ├── mini-imagenet
│ │ ├── train: 新生成的训练集,100个类别,4.8w张图片
│ │ └── val: 新生成的测试集,100个类别,1.2w张图片
│ │
│ ├── class_name.json
│ ├── new_train.csv
│ ├── new_val.csv
│ ├── imagenet_class_index.json
│ ├── test.csv
│ ├── train.csv
│ └── val.csv
│
├── classification_process.py
└── dataset_process.py 5、最终用于分类的数据集
生成的mini-imagenet数据集,包含两个子文件夹train训练集,val测试集(按照8:2随机划分)。

训练集下有100个子文件夹,代表100个类别,一共4.8w张图片。
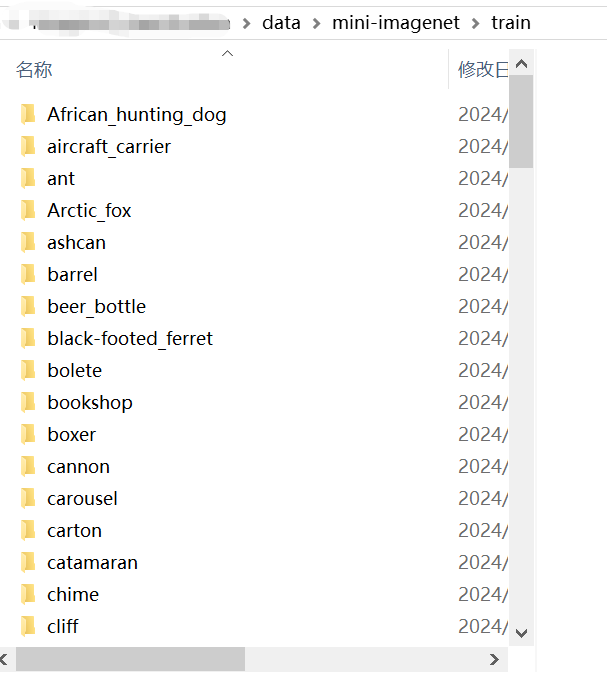
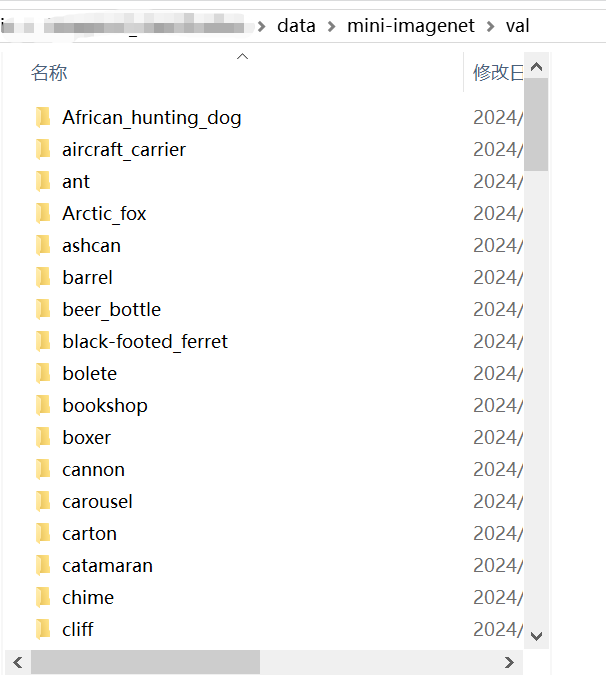
测试集包括100个子文件夹,代表100个类别,一共1.2w张图片。
这篇关于处理Mini-ImageNet数据集,用于分类任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





