本文主要是介绍百面算法工程师 | 模型评价指标及优化策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文给大家带来的百面算法工程师是深度学习模型评价指标的面试总结,文章内总结了常见的提问问题,旨在为广大学子模拟出更贴合实际的面试问答场景。在这篇文章中,我们还将介绍一些常见的评价方案,并提供参考的回答及其理论基础,以帮助求职者更好地准备面试。通过对这些问题的理解和回答,求职者可以展现出自己的算法语法领域的专业知识、解决问题的能力以及对实际应用场景的理解。同时,这也是为了帮助求职者更好地应对深度学习目标检测岗位的面试挑战,提升面试的成功率和竞争力。
目录
16.1 回归模型评估常用的方法
16.2 混淆矩阵
16.3 查准率,查全率,F1-score,准确率
16.4 PR曲线图
16.5 AP与mAP

欢迎大家订阅我的专栏一起学习共同进步
祝大家早日拿到offer! let's go
🚀🚀🚀http://t.csdnimg.cn/dfcH3🚀🚀🚀
16.1 回归模型评估常用的方法
| 指标 | 描述 |
| Mean Square Error (MSE, RMSE) | 平均方差 |
| Absolute Error (MAE, RAE) | 绝对误差 |
| R-Squared | R平方值 |
16.2 混淆矩阵
混淆矩阵是用于评估分类模型性能的一种表格形式。它将模型的预测结果与真实标签进行比较,并将它们分类为四种不同的情况:真正例 (True Positive, TP)、真负例 (True Negative, TN)、假正例 (False Positive, FP) 和假负例 (False Negative, FN)。
在混淆矩阵中,行表示实际类别,列表示预测类别。这个矩阵的一个简单示例是:
| Predicted Negative | Predicted Positive | |
| Actual Negative | TN | FP |
| Actual Positive | FN | TP |
其中:
- TP(真正例):模型正确地将猫标记为猫的数量。例如,图像中确实有一只猫,而模型也成功地将其检测为猫。
- TN(真负例):模型正确地将非猫标记为非猫的数量。例如,图像中没有猫,而模型也正确地将其识别为非猫【其他类别】。
- FP(假正例):模型错误地将非猫标记为猫的数量。例如,图像中没有猫,但模型错误地将一只狗误判为猫。
- FN(假负例):模型错误地将猫标记为非猫的数量。例如,图像中有一只猫,但模型未能将其识别为猫。
混淆矩阵提供了对模型性能的全面评估,可以从中计算出各种性能指标,如准确率、召回率、精确率和F1分数等
16.3 查准率,查全率,F1-score,准确率
下面是性能指标及其作用的表格形式:
| Metric | Formula | Purpose |
| 准确率 (Accuracy) | | 准确率是指模型正确预测的样本数量与总样本数量之比。 |
| 精确率 (Precision) | | 评估模型在预测为正例的样本中的准确程度 |
| 召回率 (Recall) | | 评估模型对正例的预测能力 |
| F1 分数 (F1 Score) | 综合考虑精确率和召回率的调和平均值,综合评估模型的性能 |
1. 准确率(Accuracy):准确率是指模型正确预测的样本数量占总样本数量的比例。
举例:在100张图像中,模型正确地识别了80张图像中的对象,那么准确率为80%。
2. 查准率(Precision):查准率是指模型预测为正例的样本中,真正为正例的样本数量占所有预测为正例的样本数量的比例。
举例:模型预测了20张图像中有猫,但实际上只有15张图像中确实有猫,那么查准率为15/20 = 0.75。
3. 查全率(Recall):查全率是指模型正确预测为正例的样本数量占所有真正为正例的样本数量的比例。
举例:在100张图像中有50张图像中确实有猫,而模型成功地识别了其中的40张,那么查全率为40/50 = 0.8。
4. F1-Score:F1-Score是查准率和查全率的调和平均值,它综合了查准率和查全率的性能。
举例:如果一个模型的查准率为0.75,查全率为0.8,那么F1-Score为2 * (0.75 * 0.8) / (0.75 + 0.8) = 0.774。
16.4 PR曲线图
在根据测试集数据评估模型时,得到各特征线性组合后的置信度得分,当确定某阈值后,若得分小于阈值则判为负类,否则为正类,计算出此时的Precision和Recall结果并保存。将阈值从大往小调整得到不同阈值下的Precision和Recall,然后以Recall为横坐标,Precision为纵坐标绘制出P-R曲线图。如果检测器的Precision随着Recall的提升而保持较高,也就是说当改变阈值,Precision和Recall仍然很高,则表示性能较优。
PR曲线的横坐标是精确率P,纵坐标是召回率R。评价标准和ROC一样,先看是否平滑。一般来说,在同一测试集,上面的比下面的好。当P和R的值接近时,F1值最大,此时画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1,此时的F1对于PRC就好像AUC对于ROC一样。一个数字比一条线更方便调型。
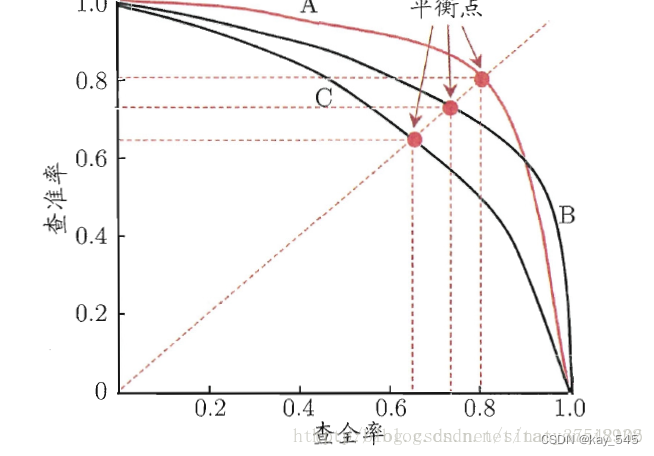
在目标检测任务中,我们通常通过比较模型的PR曲线来评估它们的性能。如果一个模型的PR曲线完全包含另一个模型的PR曲线,则可以确定前者的性能优于后者。但是,如果两个模型的PR曲线发生交叉,性能的判断就不那么直接了。
在这种情况下,我们可以利用PR曲线中P(查准率)和R(查全率)相等时的平衡点来进行比较,这个点也被称为平衡点(BEP)。平衡点处的查准率和查全率值相等,即P=R。另外,我们也可以使用F1值来评估模型的性能,F1值越大,我们可以认为该模型的性能较好。
16.5 AP与mAP
平均准确率(Average Precision, AP)和平均精确率 (mAP) 是用于评估目标检测或语义分割等任务性能的指标。
平均准确率 (AP):
AP是指在不同的类别下,模型对每个类别的预测结果计算出的准确率的平均值。在目标检测任务中,通常使用Precision-Recall曲线来计算AP。Precision-Recall曲线显示了在不同召回率下的精确率。
在计算AP时,首先计算Precision-Recall曲线下的面积 (Area Under the Curve, AUC),然后将其作为AP。具体计算公式为:
其中,p(r) 是在召回率 r 处的精确率。
平均精确率 (mAP):
mAP是指在所有类别上计算的AP的平均值。它提供了模型在所有类别上的综合性能评估。
下面是一个简单的例子,假设我们有一个目标检测模型,在三个类别上进行了评估(猫、狗、鸟),每个类别的AP分别为0.8、0.7和0.6。那么mAP为:
这意味着该模型在这三个类别上的平均准确率为0.7。
通过计算AP和mAP,我们可以更全面地评估目标检测模型的性能,而不仅仅是单个类别的性能评估。
16.6 影响mAP的因素
mAP(Mean Average Precision)是用于评估目标检测模型性能的重要指标之一,它考虑了模型在所有类别上的准确率和召回率的平均值。以下是影响mAP指标的一些重要因素:
1. 目标检测算法的准确性:目标检测算法本身的准确性对mAP指标的影响非常大。准确性包括模型对目标的识别能力和定位能力。
2. 模型的训练数据质量:训练数据的质量直接影响了模型的泛化能力和性能。更丰富、更多样化的训练数据通常可以提高模型的mAP指标。
3. 超参数调优:模型的超参数设置(如学习率、批量大小、优化器等)会影响模型的收敛速度和性能,进而影响mAP指标。
4. 数据增强策略:合适的数据增强策略(如随机裁剪、旋转、缩放等)可以增加训练数据的多样性,有助于提高模型的泛化能力和mAP指标。
5. 先验框(Anchor Boxes)的设置:一些目标检测模型(如YOLO和SSD)使用先验框来预测目标的位置和类别,先验框的设置会影响模型的检测精度和mAP指标。
6. 后处理策略:目标检测模型通常会在预测后进行后处理,如非极大值抑制(NMS)等,以过滤重叠的边界框。后处理策略的设计会影响模型的准确性和mAP指标。
综上所述,mAP指标受到多种因素的影响,包括模型本身的设计、训练数据的质量、超参数设置以及数据增强和后处理策略等。
16.7 优化策略
1. 数据增强:通过对训练数据进行各种变换,增加数据的多样性,提高模型对不同场景和变化的适应能力,改善模型的泛化能力和鲁棒性。
2. 模型优化:采用先进的模型结构或微调现有模型可提高性能。更深、更复杂的模型结构通常具有更好的特征提取能力,提高目标检测的准确性。
3. 损失函数优化:选择合适的损失函数可使模型更关注难以识别的样本,提高在目标检测任务中的性能。例如,Focal Loss可减少易分类的样本对模型训练的影响,IoU Loss可更好地优化目标的位置和形状。
4. 多尺度训练:使用不同尺度的输入训练模型可使其更好地适应不同大小的目标。这种策略可提高模型对目标的检测能力,尤其在存在尺度差异较大的情况下。
5. 网络融合:将不同的检测网络进行融合可结合它们的优点,提高模型的表现。例如,融合多尺度注意力机制和修改特征提取器,可充分利用它们在不同方面的优势,改善目标检测的性能。
这篇关于百面算法工程师 | 模型评价指标及优化策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



