本文主要是介绍#######好好好好好#########笔记︱信用风险模型(申请评分、行为评分)与数据准备(违约期限、WOE转化),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
巴塞尔协议定义了金融风险类型:市场风险、作业风险、信用风险。信用风险ABC模型有进件申请评分、行为评分、催收评分。

————————————————————————————————————
一、数据准备
1、排除一些特定的建模客户
用于建模的客户或者申请者必须是日常审批过程中接触到的,需要排除以下两类人:
异常行为:销户、按条例拒绝、特殊账户;
特殊账户:出国、卡丢失/失窃、死亡、未成年、员工账户、VIP;
其他:欺诈(根据反欺诈评分)、主动销户者(流失评分)
2、解释指标的选取
(1)申请评分所需指标
信用风险中,申请评分所采纳的指标有很多,譬如可以参考FICO信用分中的一些,参考:笔记︱金融风险控制基础常识——巴塞尔协议+信用评分卡Fico信用分
其中2.1FICO信用分的计算方法给出了一些评判标准
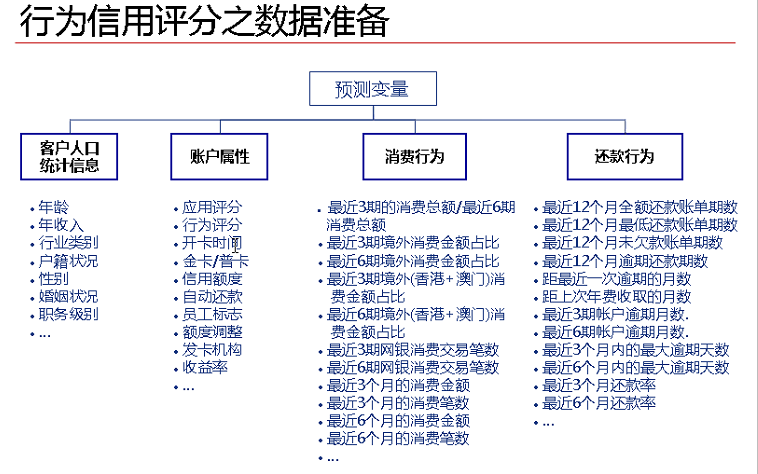
(2)行为评分所需指标
图片来自CDA-DSC课程中。
3、目标变量的确立
对于预测建模,定义目标变量是最重要、对建模结果影响最大的一步。银行业信用评分解决方案默认的目标时间定义选择二分类变量为:不良/逾期、良好。
不良/逾期:观察窗口内,观察窗口内,60/90/120天算逾期日期;
良好:从未或截止逾期;从未或在观察期内截止逾期
其中关于不良/逾期需要界定以下两项内容:确定违约日期时长、观察窗口期设置。
————————————————————————————————————
二、确定违约日期时长、观察窗口期设置
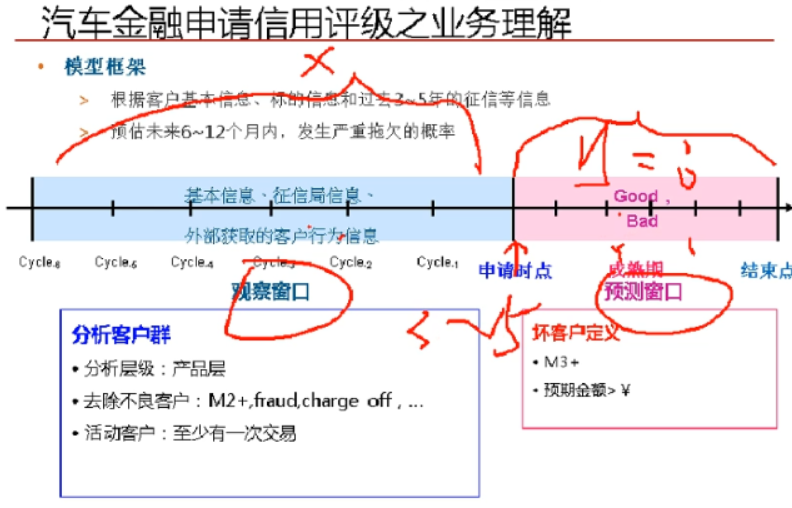
其中有两个时期,观察窗口期、预测窗口期。预测窗口期时间由账龄分析获取,观察窗口期大约就是预测窗口的3-5倍。巴塞尔协议中规定预测窗口期一般为12个月,所以一般实务中以12个月为窗口期。在已知预测窗口期之下,通过转移矩阵了解违约期具体时长。
(PS:虽然做了总结,但是还没明白老师上课所讲的,为什么这么做?怎么出结果?)
评论区网友Love_sf留言:
窗口期为一年12个月,观察窗口为预测窗口的3-5倍,即观察窗口为9个月,预测窗口3个月,或者观察窗口为10个月,预测窗口2个月,定义M2+或者M3+作为违约用户,这样才能用来建模预测坏用户出现概率。
1、违约日期的确定——转移矩阵
不同账期客户转移到更坏概率不同,选取显著变化的节点。
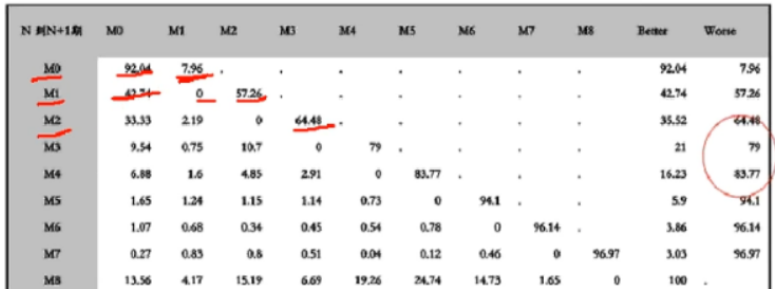
图中可以看出,第一个月不还拖欠到下一个月的概率为M0=7.96%,第二个月不还拖欠到下个月的有M1=57.26%,M2=64.48%,M3=79%,M4=83.77%。
从这里可以看出,第五个月是一个拐点,说明第五月之后就很难催到账务。所以,催帐日期可以选择3月。同时,超过5月包括5月的都属于违约行为。
2、违约窗口期设置——账龄分析
一般情况下巴塞尔协议硬性要求12个月及以上作为窗口期。一般情况下,观察窗口=3-5倍的预测窗口。

决定信用评等模型开发所需数据期间长度,一般会从最新资料的留存时点开始推算,利用账龄分析观察目标客户的违约成熟期长度,借此设定观察期长度(预测窗口的时间长度)。比如200901开卡的人,第10个月,稳定成熟了,绩效时间可以确定为10-12个月;200902开卡的人,第11个月,稳定成熟了,11-12个月。
————————————————————————————————————
三、数据重编码——WOE转换
由于制作评分卡的某些需要,通常会在建立评分模型时将自变量(连续+离散都可以)做离散化处理(等宽切割,等高切割,或者利用决策树来切割),但是模型本身没办法很好地直接接受分类自变量的输入。所以信用评分卡中常用的WOE转换。
WOE转换=分箱法=Logit值,与等深、等宽不同是根据被解释变量来重新定义一个WOE值(R语言︱噪声数据处理、数据分组——分箱法(离散化、等级化))。
WOE的公式就是:WOE=ln(好客户占比/坏客户占比)*100%=优势比
好客户占比=数量(x︱y=好)/总人数
WOE转化的优势:提升模型的预测效果,提高模型的可理解性。
1、WOE与违约概率具有某种线性关系
从而通过这种WOE编码可以发现自变量与目标变量之间的非线性关系(例如U型或者倒U型关系)。提升预测效果
2、WOE变量出现负值情况。
在此基础上,我们可以预料到模型拟合出来的自变量系数应该都是正数,如果结果中出现了负数,应当考虑是否是来自自变量多重共线性的影响。
3、标准化的功能。
WOE编码之后,自变量其实具备了某种标准化的性质,也就是说,自变量内部的各个取值之间都可以直接进行比较(WOE之间的比较),而不同自变量之间的各种取值也可以通过WOE进行直接的比较。
4、WOE能反映自变量的贡献情况。
自变量内部WOE值的变异(波动)情况,结合模型拟合出的系数,构造出各个自变量的贡献率及相对重要性。一般地,系数越大,woe的方差越大,则自变量的贡献率越大(类似于某种方差贡献率),这也能够很直观地理解。
5、异常值处理。
很多极值变量通过WOE可以变为非异常值.
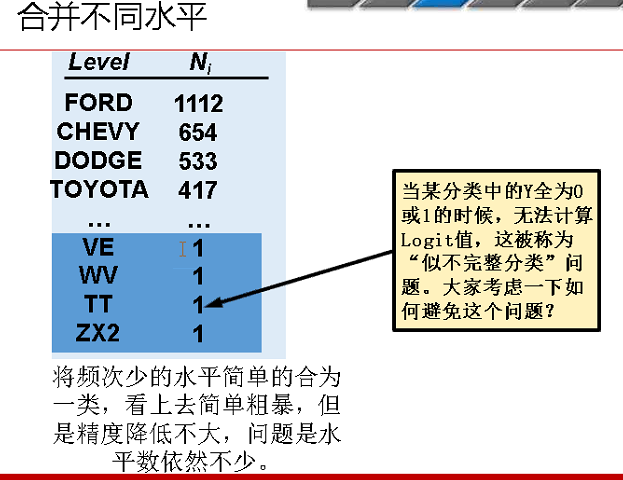
譬如解决分类之后,一些案例个数过少的情况。案例个数过少的情况一般情况下可以合并,也可以用WOE转化来实现。
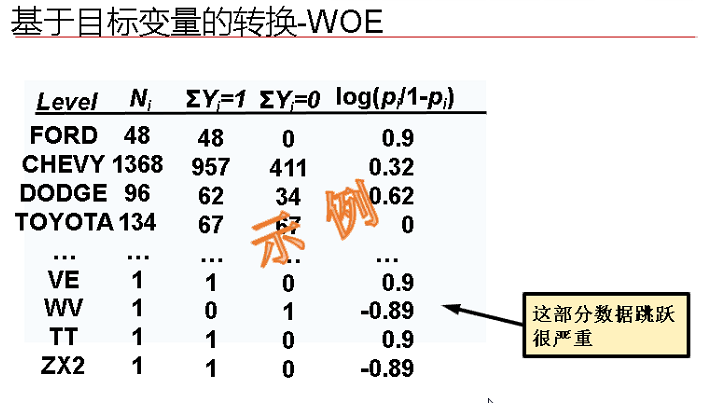
转化之后可能值变成这个样子,跳跃很大,可以作为用盖帽法等方法解决。
——————————————————————————————————————————
延伸案例一:机器学习算法基于信用卡消费记录做信用评分
- intercepy表示的是截距
- Unscaled是原始的权重值
- Scaled是分数更改指标,比如对于pay_0这个特征,如果特征落在(-1,0]之间分数就减29,如果特征落在(0,1]之间分数就加上27.
- importance表示每个特征对于结果的影响大小,数值越大表示影响越大
这篇关于#######好好好好好#########笔记︱信用风险模型(申请评分、行为评分)与数据准备(违约期限、WOE转化)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





