本文主要是介绍Prometheus Metrics指标类型 Histogram、Summary分析数据分布情况,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Histogram 直方图 、Summary 摘要 使用Histogram和Summary分析数据分布情况
除了 Counter 和 Gauge 类型的监控指标以外,Prometheus 还定义了 Histogram 和 Summary 的指标类型。Histogram 和 Summary 主用用于统计和分析样本的分布情况。
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间,这种方式也有很明显的问题,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数上,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。
Histogram 和 Summary 都是为了能够解决这样的问题存在的,通过 Histogram 和Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Summary
摘要用于记录某些东西的平均大小,可能是计算所需的时间或处理的文件大小,摘要显示两个相关的信息:count(事件发生的次数)和 sum(所有事件的总大小),如下图计算摘要指标可以返回次数为 3 和总和 15,也就意味着 3 次计算总共需要 15s 来处理,平均每次计算需要花费 5s。下一个样本的次数为 10,总和为 113,那么平均值为 11.3,因为两组指标都记录有时间戳,所以我们可以使用摘要来构建一个图表,显示平均值的变化率,比如图上的语句表示的是 5 分钟时间段内的平均速率。

例如,指标 prometheus_tsdb_wal_fsync_duration_seconds 的指标类型为 Summary,它记录了 Prometheus Server 中 wal_fsync 的处理时间,通过访问 Prometheus Server 的 /metrics 地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216



和单一的counter和gauge不同的是,summary里面有多个指标。(事件发生的总数和事件发生的总大小,以及事件的分布情况)
- 事件总数和事件总大小:从上面的样本中可以得知当前 Prometheus Server 进行
wal_fsync操作的总次数为 216 次,耗时 2.888716127000002s。 - 分布情况:其中中位数(quantile=0.5 百分之50的操作耗时)的耗时为 0.012352463,9 分位数(quantile=0.9 百分之90的操作)的耗时为 0.014458005s,百分之99的操作耗时0.017316173。
Histogram
摘要非常有用,但是平均值会隐藏一些细节,上图中 10 与 113 的总和包含非常广的范围,如果我们想查看时间花在什么地方了,那么我们就需要直方图了。
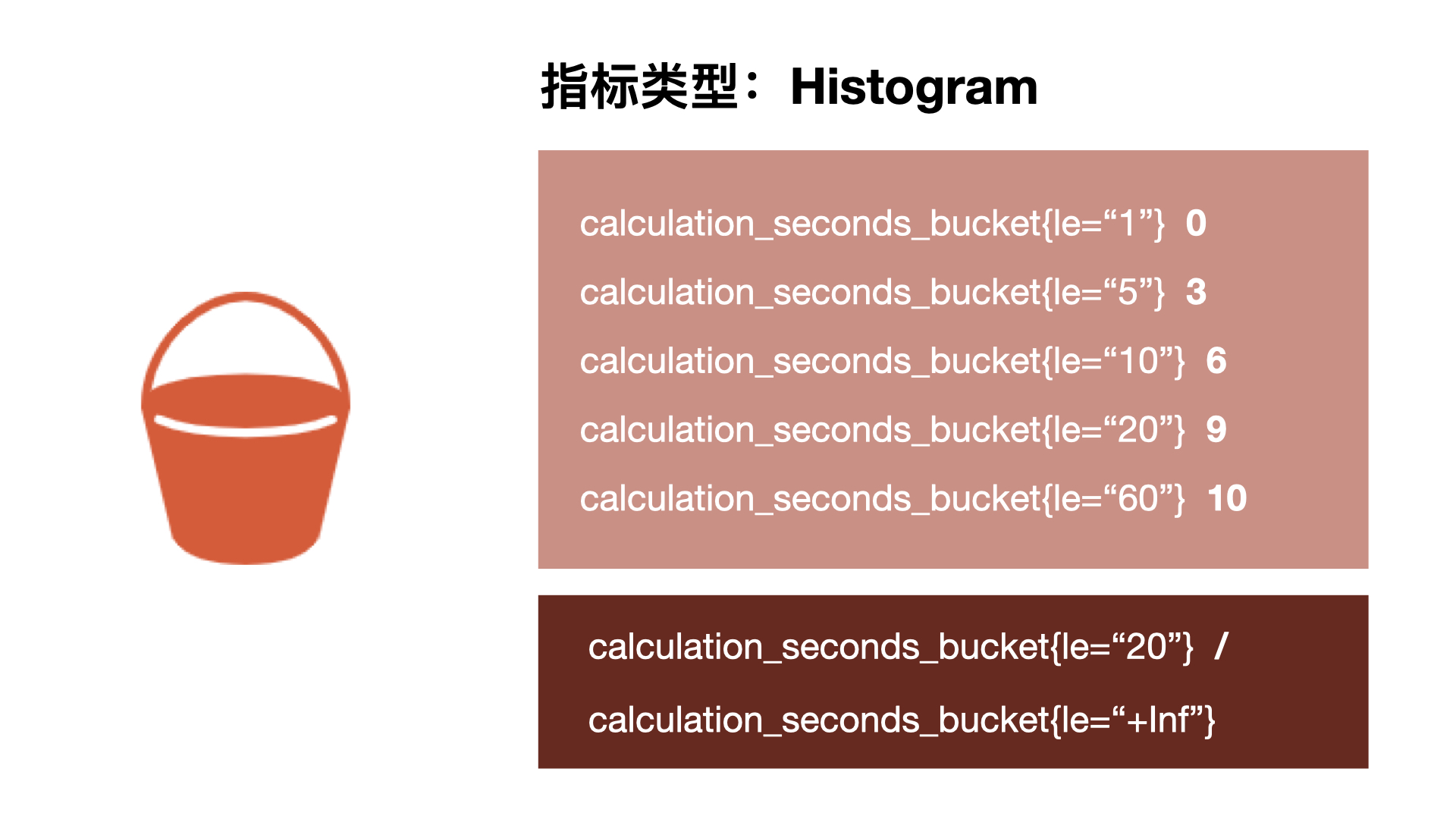
直方图以 bucket 桶的形式记录数据,所以我们可能有一个桶用于需要 1s 或更少的计算,另一个桶用于 5 秒或更少、10 秒或更少、20 秒或更少、60 秒或更少。该指标返回每个存储桶的计数,其中 3 个在 5 秒或更短的时间内完成,6 个在 10 秒或更短的时间内完成。
Prometheus 中的直方图是累积的,因此所有 10 次计算都属于 60 秒或更少的时间段,而在这 10 次中,有 9 次的处理时间为 20 秒或更少,这显示了数据的分布。所以可以看到我们的大部分计算都在 10 秒以下,只有一个超过 20 秒,这对于计算百分位数很有用。
在 Prometheus Server 自身返回的样本数据中,我们也能找到类型为 Histogram 的监控指标prometheus_tsdb_compaction_chunk_range_seconds_bucket:可以看到这个值是一直增加的,因为是累计增加的,因为1600是包含前面400和100的。
# HELP prometheus_tsdb_compaction_chunk_range_seconds Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range_seconds histogram
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="100"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1600"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="25600"} 405
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="102400"} 25690
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="409600"} 71863
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1.6384e+06"} 115928
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6.5536e+06"} 2.5687892e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="2.62144e+07"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="+Inf"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_sum 4.7728699529576e+13
prometheus_tsdb_compaction_chunk_range_seconds_count 2.5687896e+07
与 Summary 类型的指标相似之处在于 Histogram 类型的样本同样会反应当前指标的记录的总数(以 _count 作为后缀)以及其值的总量(以 _sum 作为后缀)。
不同在于 Histogram 指标直接反应了在不同区间内样本的个数,区间通过标签 le 进行定义。histogram有专门的函数去计算,后面介绍。
同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。
不同在于Histogram通过histogram_quantile函数是在服务器端计算的分位数。 而Sumamry的分位数则是直接在客户端计算完成。因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择
这篇关于Prometheus Metrics指标类型 Histogram、Summary分析数据分布情况的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





