本文主要是介绍【目标检测】DEtection TRansformer (DETR),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
论文: End-to-End Object Detection with Transformers
作者: Facebook AI
代码: DEtection TRansformer (DETR)
特点: 无proposal(R-CNN系列)、无anchor(YOLO系列)、无NMS的、端到端的目标检测方法。
二、框架
DETR总体框架图如下:

可见,其主要结构包括四个部分:backbone、encoder、decoder、prediction heads。
2.1 Backbone
输入图像先经过backbone进行特征提取,原文使用ResNet-50。此时,通道数变为2048,图像高宽变为原来的 1 32 \frac{1}{32} 321。再经过一个卷积核大小为1*1的卷积层,将通道数降低至256。
尺寸变换情况如下(同一批次的图像会经过padding统一大小):
[ b a t c h _ s i z e , 3 , h e i g h t , w i d t h ] → [ b a t c h _ s i z e , 2048 , h e i g h t / 32 , w i d t h / 32 ] → [ b a t c h _ s i z e , 256 , h e i g h t / 32 , w i d t h / 32 ] [batch \_size,3,height,width]\rightarrow[batch\_size,2048,height/32,width/32]\rightarrow[batch\_size,256,height/32,width/32] [batch_size,3,height,width]→[batch_size,2048,height/32,width/32]→[batch_size,256,height/32,width/32]
2.2 Encoder
Encoder结构如下图左侧所示:

可见,Encoder包括 N N N个这样的组件(原文中有6个),每个组件包括Spatial positional encoding、残差结构(当前输出+之前的输入)、Multi-Head Self-Attention、LayerNorm、FNN(全连接+激活+Dropout+全连接+Dropout)。
值得注意的是:
(1) DETR的位置编码采用了正余弦交替表达各像素点横纵坐标的方式,详情见我关于位置编码的博客(Spatial positional encoding)。
(2) DETR的位置编码仅加在了注意力模块中的Q、K上,这表明计算权重时会使用位置信息,但被传递至下一层的数据中不包含位置信息。原注意力模块的位置编码在Q、K、V上均有体现,详情见我关于注意力的博客(Multi-Head Self-Attention)。
2.3 Decoder
Decoder结构如下图右侧所示:

Decoder重复次数 M M M也是6,其包含的组件主要有位置编码、残差结构、Multi-Head Self-Attention、LayerNorm、Multi-Head Attention、FNN(全连接+激活+Dropout+全连接+Dropout)。
需要注意的有以下几点:
(1) Decoder的输入变为Object queries。Object queries是一个大小为100*256、初始全为0的可学习参数。100表示模型最多预测出100个目标框,256与图像特征通道数一致可保证注意力机制的正常运算。Decoder对应Object queries的输出经Prediction heads后将用于计算损失、预测框坐标、预测类别。
(2) Decoder中的位置编码与Object queries尺寸是一致的。没有使用Spatial positional encoding,而是由nn.Embedding随机初始化,全程保持不变。Decoder中的位置编码作用于Multi-Head Self-Attention前的Q、K和Multi-Head Attention前的Q。
(3) Decoder中有两个注意力模块,先通过Multi-Head Self-Attention,再通过Multi-Head Attention。Multi-Head Self-Attention是对Object queries执行自注意力,Decoder中的位置编码仅作用于Q、K。Multi-Head Attention以Object queries为Q,以Encoder的输出为K和V。Decoder中的位置编码作用于Q,Encoder中的位置编码作用于K。
2.4 Prediction heads
Prediction heads结构如下图右上部分所示:
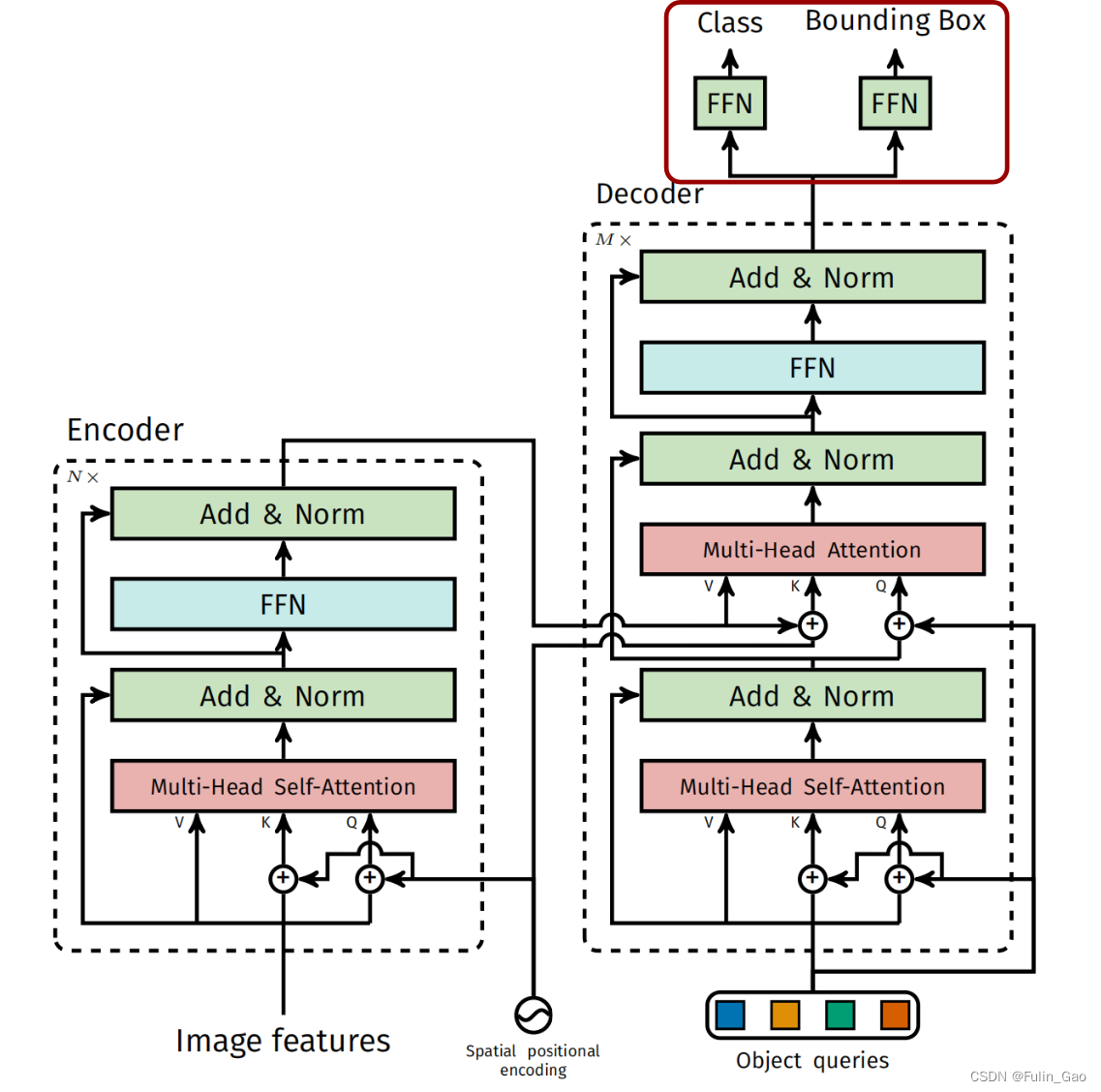
可见,与其他目标检测方法一样,DETR也是对类别和边界框进行预测。
类别预测头的FFN是一层简单的全连接,例如在COCO数据集中为 256 → 92 256\rightarrow 92 256→92(92=类别总数91+背景类1,实际COCO为80个有效类但给了91个类)。
边界框预测头的FFN是一个MLP,包括三层全连接和一层激活: 256 → 256 → 256 → 4 → s i g m o i d 256\rightarrow256\rightarrow256\rightarrow4\rightarrow sigmoid 256→256→256→4→sigmoid(4=左上角坐标2+右下角坐标2)。预测的坐标是归一化的,实际计算时需要映射至原图。
三、训练
如上所述,预测结果共有100个,每个都有对类别和边界框的预测。但是实际一张图像中目标数量通常不足100,DETR通过二分匹配为每个真实目标寻找一个最匹配的预测用于框相关损失的计算。
3.1 二分匹配
DETR使用匈牙利匹配算法,为每个真实目标寻找一个最匹配的预测。想要进行匹配首先要有对每个预测结果的衡量指标,DETR使用了三种指标:
(1) 在真实目标类上的预测概率(分类头输出经SoftMax后获得)。
(2) 所有预测框坐标与所有真实目标框坐标间的曼哈顿距离(残差的绝对值之和,即L1损失)。
(3) 所有预测框与所有真实目标框间的GIOU(一种改进的IoU指标)。
其中,(1)和(3)越大越好,(2)越小越好,所以衡量指标被定义为 − ( 1 ) + ( 2 ) − ( 3 ) -(1)+(2)-(3) −(1)+(2)−(3)。
匈牙利算法能够根据衡量指标为每个真实目标都找的一个最匹配的预测。所以DETR通过二分匹配而非NMS确定用于计算框相关损失的预测。
3.2 损失
损失包括如下三项:
(1) 交叉熵损失。每张图片有100个预测,未被匹配的预测所对应的真实标签被置为背景类91。
(2) L1损失。残差的绝对值之和。
(3) GIOU损失。 1 − G I O U 1-GIOU 1−GIOU。
交叉熵损失针对所有预测,L1损失和GIOU损失仅针对与真实目标匹配的预测。交叉熵损失仅针对类别预测,L1损失和GIOU损失仅针对框预测。
四、测试
测试时无需计算损失,也不需要NMS,直接保留类别预测概率大于阈值的预测即可。
这篇关于【目标检测】DEtection TRansformer (DETR)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






