本文主要是介绍AI大模型系列:自然语言处理,从规则到统计的演变,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI大模型系列文章目录
- 文明基石,文字与数字的起源与演变
- 自然语言处理,从规则到统计的演变
自然语言处理,从规则到统计的演变
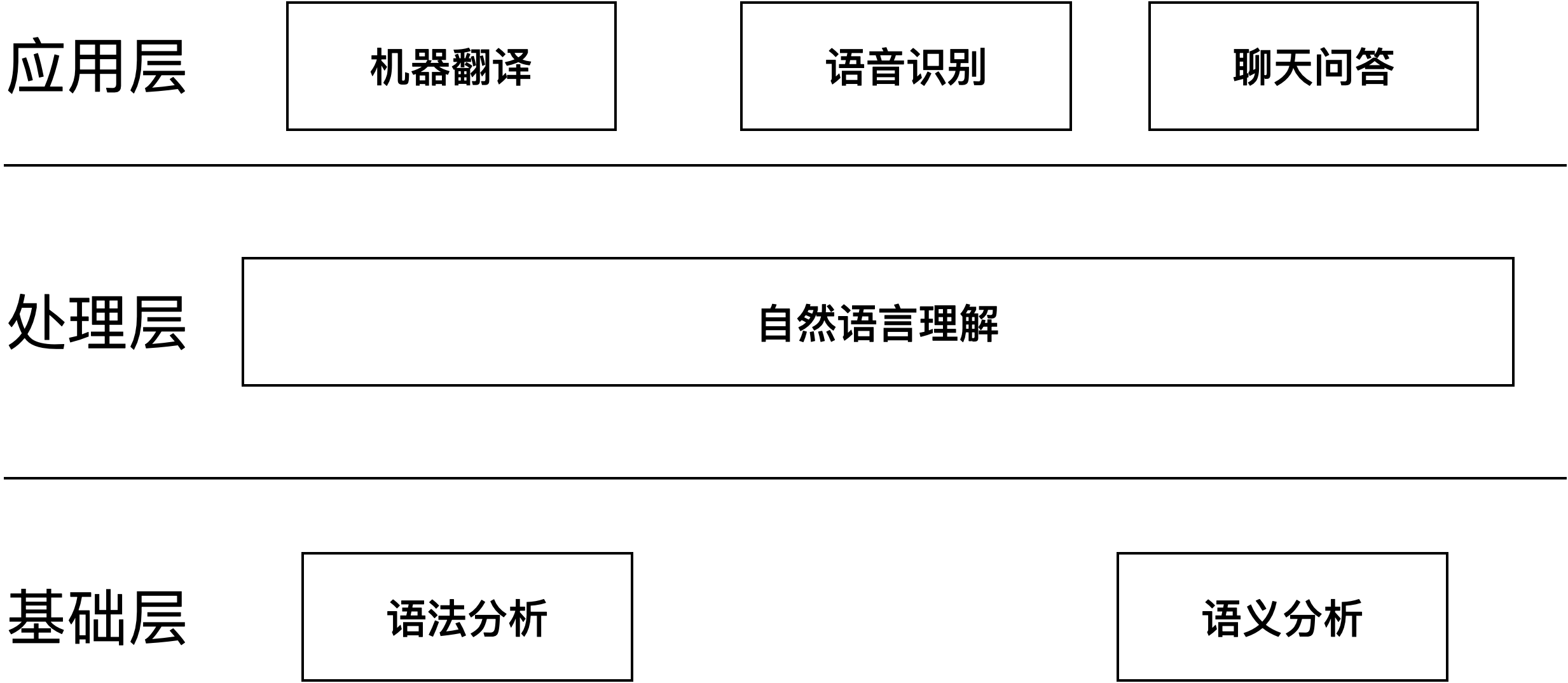
自然语言处理(Natural Language Processing,NLP)是人工智能的一个重要分支,主要研究如何让计算机理解、解释和生成人类语言。从自然语言处理的字面上来看,最重要的是“语言”二字,语言则是通过语法规则将一个个毫无联系的文字、数字和字母串联起来的。
文字的出现是因为咱们祖先为了记录所见所闻和所思所想(传送门),咱们的祖先再将文字、字母和数字进行信道编码就成为了我们日常使用的语言。简单来讲,我们把一个要表达的意思,通过中文的一句话表达出来,就是在头脑中用中文的编码方式对其进行编码,然后得到一串汉字。对方如果懂得中文,在接收到之后就可以在头脑中使用中文的解码方式来解码,进而获得说话人想要表达的信息。
世界上存在的每一种语言都有自己独有的语法规则,从而都拥有自己独有的编解算法,即这就是语言在数学上的本质。
人类还是机器?
1946年,冯·诺伊曼体系的现代计算机出现以后,计算机在很多领域的很多工作做得都比人还好。既然如此,当时的科学家们就提出了计算机能不能懂得自然语言的课题,由此开启了自然语言处理研究的漫漫长路。
最早提出机器智能设想的是,计算机科学之父的阿兰·图灵(Alan Mathison Turing,1912年6月23日—1954年6月7日),没错这是电影《模仿游戏》中的那个阿兰·图灵(传送门)。1950年他在《思想》杂志上发表了一篇题为“计算的机器和智能”的论文,并在论文中提出了一种验证机器是否有智能的方法:让人和机器进行交流,如果人无法判断自己交流的对象是人还是机器,那么就说明这个机器拥有了智能。这个方法被后人称为“图灵测试”,自此拉开了自然语言处理的序幕。
自然语言处理发展虽然经过几十年的发展,但基本上可分为语言语法规则、数学模式统计和深度学习这么几个阶段。
探索
时间回到1950年代到1970年代,当时的学术界对人工智能和自然语言处理的统一认识就是:要让机器完成翻译或者语音识别等只有人类才能做的事情,就必须先让计算机理解自然语言,而要做到这一点就必须让计算机拥有类似人类这样的智能。
之所以会这样的认为,是因为咱们的大脑在解决问题或者学习技能时,首先会寻找与要解决或学习事物类似的事物进行模仿研究,进而完成仿制。正如有人认为怀特兄弟发明飞机仅仅是通过模仿鸟儿飞行,但是殊不知怀特兄弟成功发明飞机靠的不是仿生学而是空气动力学。同样在自然语言处理早期咱们的科学家也就走了弯路,企图使用仿生学来让计算机拥有处理语言的能力。
基于上述共识科学家在分析语句和获取语义上花费了大量的功夫,并在1954年,乔治城大学和IBM合作开发了第一个机器翻译系统,这个机器翻译系统的底层原理就是通过分析语句、获取语义然后使用语法规则来处理语言,并且其运行几乎依赖于手工编写的规则来解析和处理语言。
此阶段虽然有不少的研究成果,但是整体的研究成果乏善可陈。因为世界上语言众多,哪怕只是覆盖一种语言的语法规则的工作量也是巨大的,并且还存在方言、多义性和上下文的问题。自此当时的科学家渐渐地丧失了信心,自然语言发展也进入了蛰伏期。
破局
1970年代基于规则的句法分析走到了尽头,但是自然语言处理的研究并没有因此停滞不前,历史的齿轮再一次转到,佛里德里克·贾里尼克(Frederick Jelinek)和他领导的IBM华生实验室(T.J.Watson)摒弃使用语法规则来解决语音识别问题,开始转而使用基于统计的方法,一下子就将IBM的语音识别率从70%提升到了90%,同时语音识别的规模也从几百单词上升到了几万单词,这就表示语音识别有从实验室走向实际应用的可能,同时也表示在自然语言处理上有了新的研究方向。
虽然贾里尼克使用统计学的方法在自然语言处理上取得了突破,但是碍于当时算力不足和顽固派的阻挠整体发展还是相当的缓慢。虽然在1988年,IBM的彼得·布朗(Peter Brown)等人提出了基于统计的机器翻译方法,同样也碍于算力不足和没有足够强大的模型从而没有得到突破。
1990年代统计方法开始成为自然语言处理的主流方法,并在1990年美国计算语言学会(ACL)成立了。同时在隐马尔可夫模型的加持,推动了自然语言处理研究发展进入了快车道。1993年,第一个基于统计的机器翻译系统IBM Model 1发布。这个时期的自然语言处理系统开始使用大量语料库进行训练,提高系统的准确性和鲁棒性。
隐马尔可夫模型被任务是解决大多数自然语言处理问题最为快速、有效的方法,在成功地解决了复杂的语音识别、机器翻译等问题。最关键的是它并不是一个复杂的数学模型,理解和实现的难度都不大。
2000年-2010年这十年深度学习崛起,并开始在自然语言处理中崭露头角。2001年,神经概率语言模型(Neural Probabilistic Language Model)被提出,为后来的深度学习在自然语言处理中的应用奠定了基础。并经过多年的研究发展,2018年谷歌又一次打出了王炸—BERT(Bidirectional Encoder Representations from Transformers)模型刷新了多个自然语言处理任务的记录。此后自然语言处理领域继续快速发展,各种预训练模型如GPT、RoBERTa、XLNet等不断刷新纪录。
同时,自然语言处理开始与其他领域如计算机视觉、语音识别等结合,形成了多模态学习的趋势。此外,自然语言处理技术开始在工业界得到广泛应用,如智能客服、机器翻译、情感分析等。
这篇关于AI大模型系列:自然语言处理,从规则到统计的演变的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





