本文主要是介绍上市公司-双重差分模型手动匹配绿色企业数据及参考资料,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、数据简介
双重差分模型(DID,Differences-in-Differences)是一种用于估计某个政策或处理效果的经济计量学模型。通过双重差分模型,可以控制一些不易观察的个体特征和时间趋势,以更准确地估计政策的效应。将绿色企业的定义应用于双重差分模型中,可以将处理组(即绿色企业)与控制组(即非绿色企业)进行匹配。
A股上市公司双重差分模型手动匹配绿色企业数据(是绿色企业:green=1;不是绿色企业green=0)。用于识别绿色企业并作为实验组。
借鉴Hu et al.(2021)的做法,将企业主营业务与《绿色产业指导目录》相匹配的方式来识别绿色企业
并且识别样本企业中的重污染企业,文件包含绿色企业识别数据,重污染企业证券代码,非重污染企业证券代码。绿色企业数据为手动匹配,主营业务从年报获得,数据准确,目前有约1800家企业数据。
数据名称:上市公司-双重差分模型手动匹配绿色企业数据
数据数目:1794条
02、包含指标
code、Conme、green
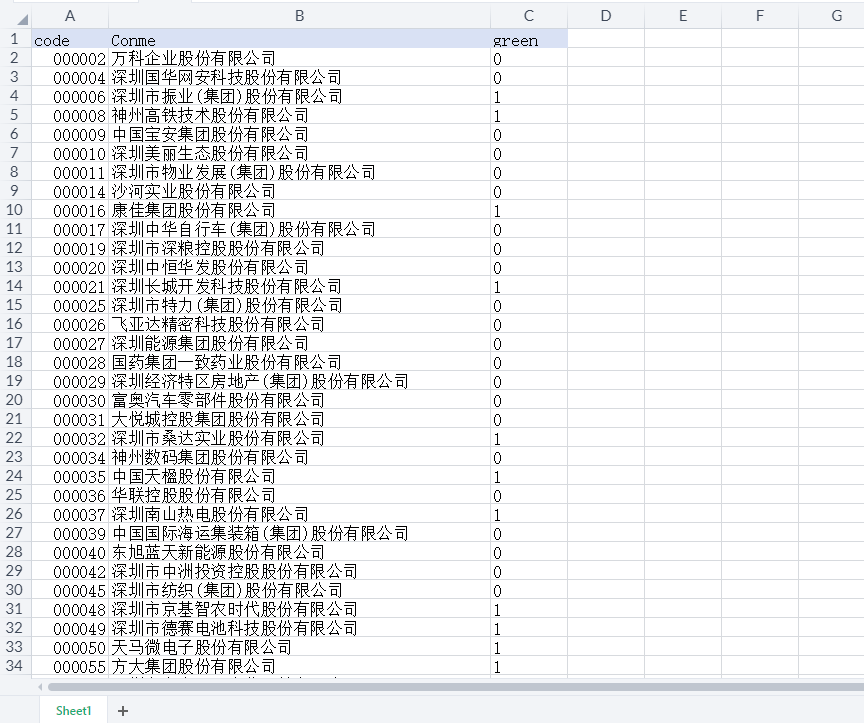
03、数据截图
| code | Conme | green |
| 000002 | 万科企业股份有限公司 | 0 |
| 000004 | 深圳国华网安科技股份有限公司 | 0 |
| 000006 | 深圳市振业(集团)股份有限公司 | 1 |
| 000008 | 神州高铁技术股份有限公司 | 1 |
| 000009 | 中国宝安集团股份有限公司 | 0 |
| 000010 | 深圳美丽生态股份有限公司 | 0 |
| 000011 | 深圳市物业发展(集团)股份有限公司 | 0 |
| 000014 | 沙河实业股份有限公司 | 0 |
| 000016 | 康佳集团股份有限公司 | 1 |
| 000017 | 深圳中华自行车(集团)股份有限公司 | 0 |
| 000019 | 深圳市深粮控股股份有限公司 | 0 |
| 000020 | 深圳中恒华发股份有限公司 | 0 |
| 000021 | 深圳长城开发科技股份有限公司 | 1 |
| 000025 | 深圳市特力(集团)股份有限公司 | 0 |
| 000026 | 飞亚达精密科技股份有限公司 | 0 |
| 000027 | 深圳能源集团股份有限公司 | 0 |
| 000028 | 国药集团一致药业股份有限公司 | 0 |
| 000029 | 深圳经济特区房地产(集团)股份有限公司 | 0 |
| 000030 | 富奥汽车零部件股份有限公司 | 0 |
| 000031 | 大悦城控股集团股份有限公司 | 0 |
| 000032 | 深圳市桑达实业股份有限公司 | 1 |
| 000034 | 神州数码集团股份有限公司 | 0 |
| 000035 | 中国天楹股份有限公司 | 1 |
| 000036 | 华联控股股份有限公司 | 0 |
| 000037 | 深圳南山热电股份有限公司 | 1 |
| 000039 | 中国国际海运集装箱(集团)股份有限公司 | 0 |
| 000040 | 东旭蓝天新能源股份有限公司 | 0 |
| 000042 | 深圳市中洲投资控股股份有限公司 | 0 |
| 000045 | 深圳市纺织(集团)股份有限公司 | 0 |
| 000048 | 深圳市京基智农时代股份有限公司 | 1 |
04、包含内容

05、全部内容下载链接: https://download.csdn.net/download/li514006030/89244528
这篇关于上市公司-双重差分模型手动匹配绿色企业数据及参考资料的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





