本文主要是介绍《R语言与农业数据统计分析及建模》学习——判别分析和主成分分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、判别分析
判别分析又称“分辨法”。使用已知分类的数据训练建立分类规则,然后把这样的规则应用到未知分类的样本中去分类,以识别位置样本所属的分类。
判别分析多用于遥感影像的地物分类;农林害虫预报;气象数据中的天气预报等等。
1、载入数据集
使用R语言自带的iris数据集,进行Fisher线性判别。用MASS包调用相关函数。
# 安装并载入所需MASS包
install.packages("MASS")
library(MASS)# 载入iris数据集
data(iris)
head(iris)
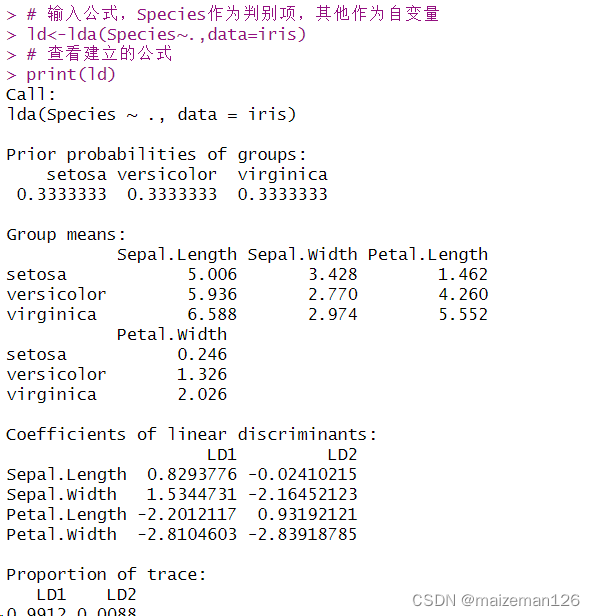
2、输入判别公式
先验概率(prior probability of groups),为不同的类别分配不同的概率估计,用于确定新观测数据属于哪个类别。
各组均值向量(group means),即该组各维度的数据均值作为该组的均值向量。
第一、第二线性判别函数系数(Coefficient of linear discriminants)
两个判别式对区分各总体贡献的大小(proportion of trace)
# 输入公式,Species作为判别项,其他作为自变量
ld<-lda(Species~.,data=iris)
# 查看建立的公式
print(ld)
3、判别分析结果比较
# 对原始数据进行回判分类
p_iris<-predict(ld)
new_class<-p_iris$class
# 查看结果
print(cbind(iris$Species,new_class,p_iris$x))
# 列表比较
table(iris$Species,p_iris$class)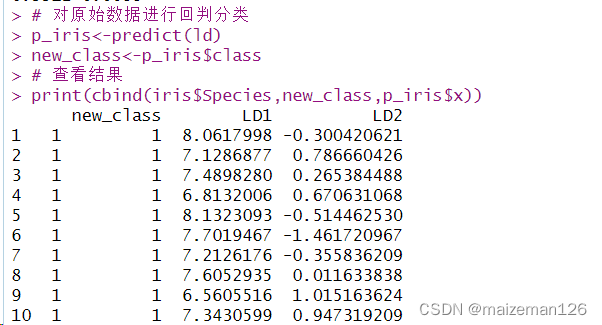

二、主成分分析
主成分分析的一半目的是变量的降维和主成分的解释。
主成分分析通过正交变换将一组核能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫做主成分。
在变换中,保持变量的总方差不变,同时,使第一主成分具有最大方差,第二主成分具有次大方差,依次类推。
1、载入数据集
数据集采用R语言自带iris数据集。还需要两个包:
FactoMineR包:包含主成分分析所需的PCA函数。
factoextra包:进行主成分的可视化
library('FactoMineR')
library('factoextra')
# 载入数据集
data(iris)
# 查看数据
head(iris,3)2、主成分分析
使用FactoMineR包中的PCA()函数。
PCA(X,sacle.unit=T,graph=T)
其中,X表示不包含分类变量的主成分分析数据集;
scale.unit=T代表是分析前对数据进行标准化处理;
graph=F代表不显示图像。
3、提取特征值
使用factoextra包中的get_eigenvalue()函数,提取主成分的特征值/方差贡献率。
# 主成分分析
# iris[,-5],为删除了分类变量的iris数据集
iris_pca<-PCA(iris[,-5],scale.unit=T,graph=F)
# 提取特征值
eig_val<-get_eigenvalue(iris_pca)
print(eig_val) 
4、结果可视化
碎石图绘制函数:factoextra包中的fviz_eig()函数
个体在主成分空间的显示:factoextra包中的fviz_pac_ind()函数
# 可视化
# 碎石图
screen_plot<-fviz_eig(iris_pca)
screen_plot
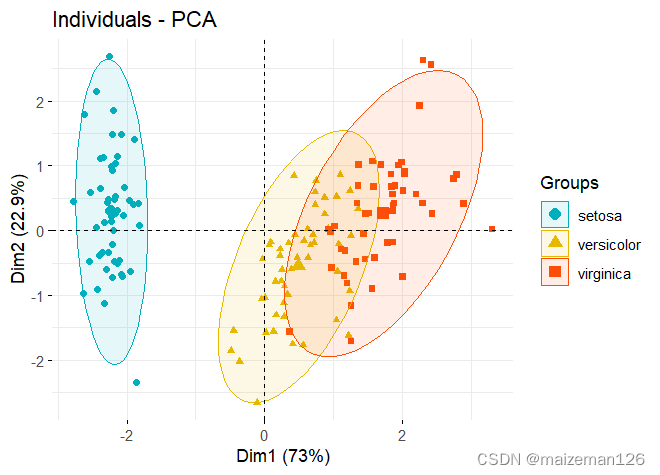
# 个体PCA可视化
ind_plot<-fviz_pca_ind(iris_pca,geom.ind = "point", # 点图col.ind=iris$Species,palette=c("#00AFBB","#E7B800","#FC4E07"), #颜色设置addEllipses = TRUE, # 添加椭圆legend.title="Groups" # 添加标题
)
ind_plot
这篇关于《R语言与农业数据统计分析及建模》学习——判别分析和主成分分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





