本文主要是介绍文心一言 VS 讯飞星火 VS chatgpt (246)-- 算法导论18.1 4题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
四、一棵高度为 h 的 B 树中,可以存储最多多少个关键字?用最小度数 t 的函数表示。如果要写代码,请用go语言。
文心一言:
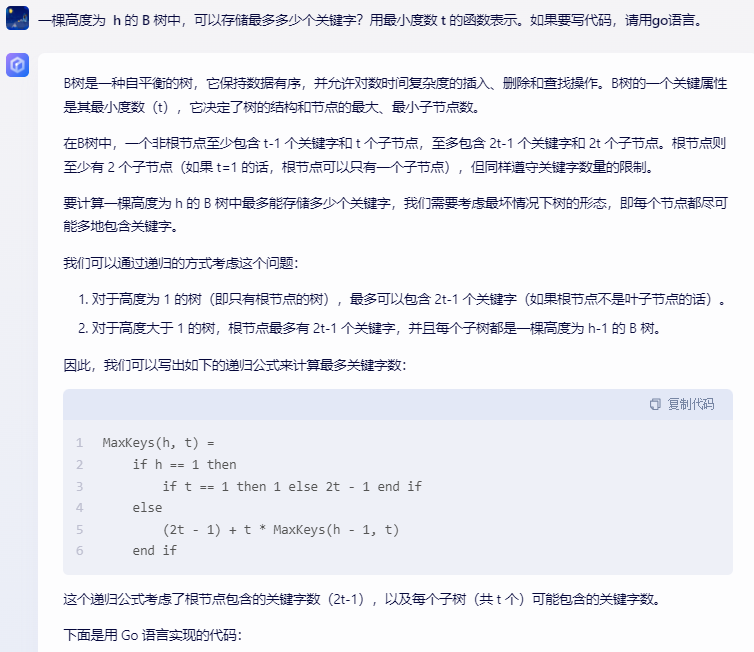
B树是一种自平衡的树,它保持数据有序,并允许对数时间复杂度的插入、删除和查找操作。B树的一个关键属性是其最小度数(t),它决定了树的结构和节点的最大、最小子节点数。
在B树中,一个非根节点至少包含 t-1 个关键字和 t 个子节点,至多包含 2t-1 个关键字和 2t 个子节点。根节点则至少有 2 个子节点(如果 t=1 的话,根节点可以只有一个子节点),但同样遵守关键字数量的限制。
要计算一棵高度为 h 的 B 树中最多能存储多少个关键字,我们需要考虑最坏情况下树的形态,即每个节点都尽可能多地包含关键字。
我们可以通过递归的方式考虑这个问题:
对于高度为 1 的树(即只有根节点的树),最多可以包含 2t-1 个关键字(如果根节点不是叶子节点的话)。
对于高度大于 1 的树,根节点最多有 2t-1 个关键字,并且每个子树都是一棵高度为 h-1 的 B 树。
因此,我们可以写出如下的递归公式来计算最多关键字数:
MaxKeys(h, t) = if h == 1 then if t == 1 then 1 else 2t - 1 end if else (2t - 1) + t * MaxKeys(h - 1, t) end if
这个递归公式考虑了根节点包含的关键字数(2t-1),以及每个子树(共 t 个)可能包含的关键字数。
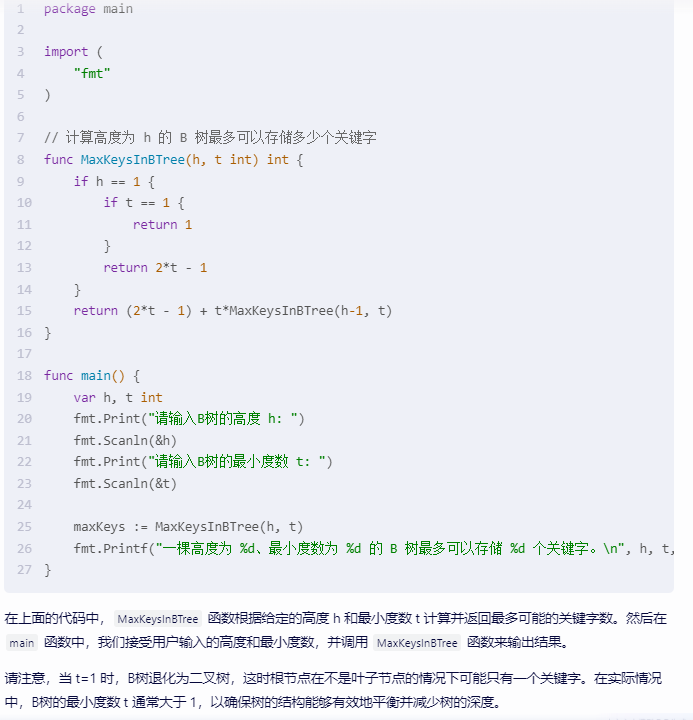
下面是用 Go 语言实现的代码:
package main import ( "fmt"
) // 计算高度为 h 的 B 树最多可以存储多少个关键字
func MaxKeysInBTree(h, t int) int { if h == 1 { if t == 1 { return 1 } return 2*t - 1 } return (2*t - 1) + t*MaxKeysInBTree(h-1, t)
} func main() { var h, t int fmt.Print("请输入B树的高度 h: ") fmt.Scanln(&h) fmt.Print("请输入B树的最小度数 t: ") fmt.Scanln(&t) maxKeys := MaxKeysInBTree(h, t) fmt.Printf("一棵高度为 %d、最小度数为 %d 的 B 树最多可以存储 %d 个关键字。\n", h, t, maxKeys)
}
在上面的代码中,MaxKeysInBTree 函数根据给定的高度 h 和最小度数 t 计算并返回最多可能的关键字数。然后在 main 函数中,我们接受用户输入的高度和最小度数,并调用 MaxKeysInBTree 函数来输出结果。
请注意,当 t=1 时,B树退化为二叉树,这时根节点在不是叶子节点的情况下可能只有一个关键字。在实际情况中,B树的最小度数 t 通常大于 1,以确保树的结构能够有效地平衡并减少树的深度。
讯飞星火:
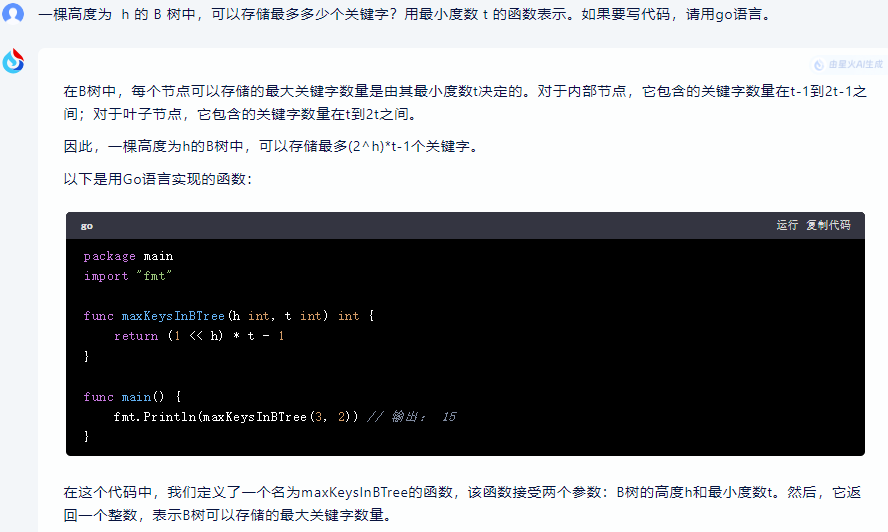
在B树中,每个节点可以存储的最大关键字数量是由其最小度数t决定的。对于内部节点,它包含的关键字数量在t-1到2t-1之间;对于叶子节点,它包含的关键字数量在t到2t之间。
因此,一棵高度为h的B树中,可以存储最多(2^h)*t-1个关键字。
以下是用Go语言实现的函数:
package main
import "fmt"func maxKeysInBTree(h int, t int) int {return (1 << h) * t - 1
}func main() {fmt.Println(maxKeysInBTree(3, 2)) // 输出: 15
}
在这个代码中,我们定义了一个名为maxKeysInBTree的函数,该函数接受两个参数:B树的高度h和最小度数t。然后,它返回一个整数,表示B树可以存储的最大关键字数量。
360智脑:
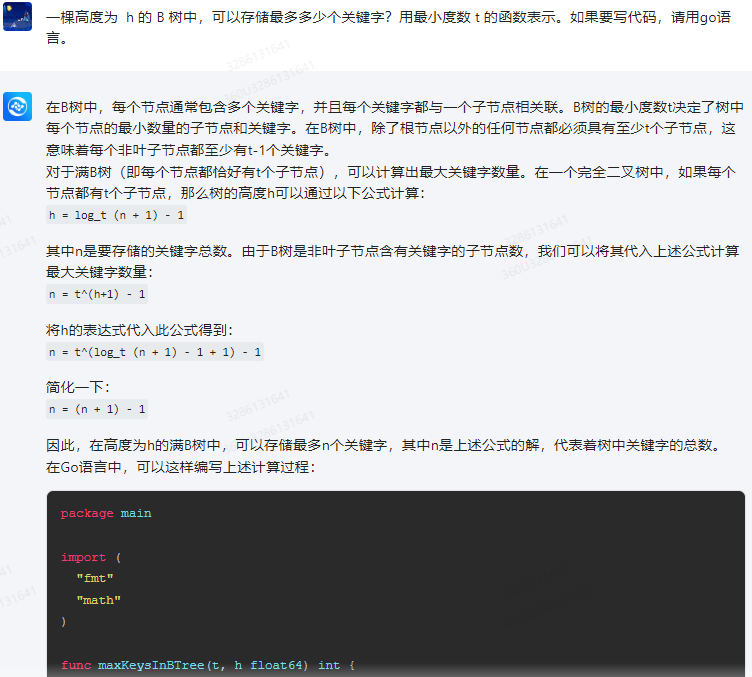
在B树中,每个节点通常包含多个关键字,并且每个关键字都与一个子节点相关联。B树的最小度数t决定了树中每个节点的最小数量的子节点和关键字。在B树中,除了根节点以外的任何节点都必须具有至少t个子节点,这意味着每个非叶子节点都至少有t-1个关键字。
对于满B树(即每个节点都恰好有t个子节点),可以计算出最大关键字数量。在一个完全二叉树中,如果每个节点都有t个子节点,那么树的高度h可以通过以下公式计算:
h = log_t (n + 1) - 1
其中n是要存储的关键字总数。由于B树是非叶子节点含有关键字的子节点数,我们可以将其代入上述公式计算最大关键字数量:
n = t^(h+1) - 1
将h的表达式代入此公式得到:
n = t^(log_t (n + 1) - 1 + 1) - 1
简化一下:
n = (n + 1) - 1
因此,在高度为h的满B树中,可以存储最多n个关键字,其中n是上述公式的解,代表着树中关键字的总数。
在Go语言中,可以这样编写上述计算过程:
package mainimport ("fmt""math"
)func maxKeysInBTree(t, h float64) int {// 计算B树的最大关键字数量n := math.Pow(t, h+1) - 1return int(n)
}func main() {// 假设最小度数t为2t := 2.0// 可以按需设置B树的高度h := 5.0 // 例如,高度为5的B树// 计算最大关键字数量maxKeys := maxKeysInBTree(t, h)fmt.Printf("The maximum number of keys in a height %v B-tree with minimum degree %v is %v\n", h, t, maxKeys)
}这个程序将计算给定最小度数t和高度h的B树中最多可存储的关键字数量。请注意,实际的关键字数量取决于具体的应用场景和数据分布,这个数值提供了一个理论上的最大值。
智谱清言:
B树是一种自平衡的树数据结构,它维持数据的有序性,并且允许搜索、顺序访问、插入和删除的操作都在对数时间内完成。在B树中,每个节点最多可以有t-1个关键字和t个子节点。这里的关键字是指数据值,子节点是指指向其他B树节点的指针。
一棵高度为h的B树中,可以存储的最多关键字数量取决于B树的度数t,即每个节点最多有多少个子节点。树的高度h和度数t的关系可以通过以下公式推导出来:
设一棵高度为h的B树最多可以存储的关键字数量为N。
1.根节点至少有一个子节点,所以至少有t个子节点。
2.根节点也是一个关键字,所以根节点本身贡献了一个关键字。
3.其他每个节点(除了根节点)因为至少有t个子节点,所以它们至少有t-1个关键字。
4.高度为h的树意味着有h层节点(根节点是第0层),其中第0层是根节点,第1层是根节点的子节点,以此类推,第h-1层是叶子节点。
如果一个节点有t个子节点,那么这个节点加上其t个子节点构成的子树中,可以有t-1个关键字加上每个子节点可能构成的另一棵高度为h-1的B树中的关键字。
因此,可以通过以下递归关系来表示:
1.( N = 1 + (t-1) + t*(N_{h-1} + (t-1) + t*(N_{h-2} + … + (t-1) + t*N_0) )
2.其中 ( N_i ) 表示高度为 ( i ) 的B树中最多可以存储的关键字数量。
对于高度为h的B树,我们需要找到最小的t,使得上述公式成立。这个问题可以通过编程来解决,下面是一个用Go语言实现的示例:
package main
import ("fmt"
)
// 计算可以存储的最大关键字数量
func maxKeysInLevel(t, h int) int {if h == 0 {return 1}// 每个节点除了根节点外,都有t-1个关键字,根节点有1个关键字// 每个节点都有t个子节点,这些子节点本身也可以构成B树return (t - 1) + t*maxKeysInLevel(t, h-1)
}
// 找到最小的度数t,使得高度为h的B树可以存储至少m个关键字
func findMinDegree(m, h int) int {t := 1for {if maxKeysInLevel(t, h) >= m {return t}t++}return t
}
func main() {h := 3 // B树的高度m := 10 // 需要存储的关键字数量t := findMinDegree(m, h)fmt.Printf("为了使高度为 %d 的B树存储至少 %d 个关键字,最小的度数t为 %d\n", h, m, t)
}
这个程序首先定义了一个函数 maxKeysInLevel 来计算给定度数t的B树中第i层最多可以存储的关键字数量。然后定义了一个函数 findMinDegree 来找到最小的度数t,使得高度为h的B树可以存储至少m个关键字。最后在 main 函数中调用了这些函数,并打印出了结果。



天工:
B树的关键字存储能力取决于它的分支因子(通常表示为 b),即除了根节点外,每个节点至少有多少个子节点。对于一个高度为 h,分支因子为 b 的 B树,最多可以存储的关键字数 T 可以通过以下公式计算:
T = (b^(h+1) - 1) / (b - 1)
这里,b^(h+1) 表示 b 的 h+1 次方,- 1 和 /(b - 1) 是因为我们从 b 的 h+1 次方的总数中减去根节点的 (b - 1) 个空位,然后除以 (b - 1) 得到实际的节点数。
在 Go 语言中,我们可以按照以下方式编写这个计算:
package mainimport "fmt"// b represents the branching factor of the B-tree
const b = 3 // 以常见的 B+ 树为例,b 通常为 3 或更高func maxKeysInBTree(h int) int {return (int64(b) ^ (int64(h) + 1)) / (int64(b) - 1)
}func main() {h := 3 // 假设树的高度为 3t := maxKeysInBTree(h)fmt.Printf("A B-tree of height %d can store at most: %d keys\n", h, t)
}
请注意,在实际应用中,B树的高度通常不会太高,因为随着高度的增加,树的深度指数增长,这会导致查找效率降低。另外,上述代码中的 b 值是假定的,实际情况中 B树的设计可能不同,需要根据具体情况调整 b 的值。
灵小智:
B树是一种多路搜索树,它的每个节点可以包含多个关键字。对于高度为h的B树,最多可以存储的关键字数量是通过计算每个节点的最大容量得出的。
B树的最小度数t表示每个非根节点至少包含t-1个关键字,最多包含2t-1个关键字。同时,每个非根节点至少有t个子节点,最多有2t个子节点。根节点特例,至少包含1个关键字,最多包含2t-1个关键字。
因此,在给定最小度数t的情况下,一个高度为h的B树可以存储的最多关键字数量为:
(2t-1) + (2t-1) + (2t-1) + … + (2t-1) (共h层)
= h * (2t-1)
如果使用Go语言编写代码来计算根据给定的最小度数t和树的高度h来确定B树可以存储的最多关键字数量,可以按照以下方式实现:
package mainimport "fmt"func calculateMaxKeys(t, h int) int {return h * (2*t - 1)
}func main() {t := 2h := 3maxKeys := calculateMaxKeys(t, h)fmt.Printf("在最小度数为%d的情况下,高度为%d的B树可以存储的最多关键字数量为%d\n", t, h, maxKeys)
}
以上代码将输出:
在最小度数为2的情况下,高度为3的B树可以存储的最多关键字数量为15
希望以上回答对您有所帮助!如果还有其他问题,请随时提问。
chatgpt:
在一棵高度为 h 的 B 树中,可以存储的最多关键字数量可以用最小度数 t 表示为:(2t-1) * (2t^(h-1))。
以下是用 Go 语言实现的示例代码:
package mainimport ("fmt"
)func maxKeysInBTree(h, t int) int {if h == 0 {return 0}return (2*t - 1) * pow(t, h-1)
}func pow(x, n int) int {result := 1for i := 0; i < n; i++ {result *= x}return result
}func main() {h := 3 // B树的高度t := 2 // 最小度数maxKeys := maxKeysInBTree(h, t)fmt.Printf("在一棵高度为 %d 的 B 树中,可以存储的最多关键字数量为 %d\n", h, maxKeys)
}
此代码计算了一棵高度为 h 的 B 树中,使用最小度数 t 可以存储的最大关键字数量,并输出结果。
kimi:
一棵高度为 ( h ) 的 B 树可以存储的关键字数量取决于其最小度数 ( t ) 和树的高度。根据 B 树的定义,每个内部节点(除了根节点)至少有 ( t ) 个关键字和 ( t + 1 ) 个孩子,最多有 ( 2t ) 个关键字和 ( 2t + 1 ) 个孩子。根节点至少有 1 个关键字(除非它是空的)。
对于非根节点,每个节点可以存储的关键字数量范围是 ( [t, 2t] )。对于根节点,它可以有 1 个关键字和 ( [t, 2t] ) 个孩子。
一棵高度为 ( h ) 的 B 树的最多关键字数量可以通过以下方式计算:
- 根节点有 1 个关键字。
- 根节点以下的每一层都有 ( 2t + 1 ) 个节点,每层节点可以存储的关键字数量是 ( [t, 2t] )。
因此,一棵高度为 ( h ) 的 B 树可以存储的最多关键字数量 ( N ) 可以表示为:
[ N = 1 + (2t - 1)(h - 1) ]
这里的 ( h - 1 ) 是因为根节点不计入高度。
下面是用 Go 语言表示上述逻辑的代码:
package mainimport "fmt"// 计算 B 树的最大关键字数量
func maxKeysInBTree(t int, h int) int {if h == 1 {return 1 // 根节点至少有 1 个关键字}return 1 + (2*t - 1) * (h - 1) // 加上根节点的 1 个关键字
}func main() {minDegree := 2 // 最小度数 theight := 3 // B 树的高度 hmaxKeys := maxKeysInBTree(minDegree, height)fmt.Printf("A B-Tree of height %d and minimum degree %d can store at most %d keys.\n", height, minDegree, maxKeys)
}
在这个 Go 语言程序中,maxKeysInBTree 函数计算并返回给定最小度数 ( t ) 和高度 ( h ) 的 B 树可以存储的最大关键字数量。然后在 main 函数中,我们设置了最小度数和高度的值,并调用 maxKeysInBTree 函数来获取并打印出可以存储的最大关键字数量。
混元:
B树的最小度数t表示每个节点至少有t-1个关键字,最多有2t-1个关键字。在高度为h的B树中,可以存储的关键字数量取决于每个节点的关键字数量。
在最理想的情况下,B树的每个节点都有最大的关键字数量,即2t-1。因此,我们可以通过计算每层节点的数量来估算B树中可以存储的关键字数量。
在高度为h的B树中,根节点有1个,第二层有t个,第三层有t2个,以此类推,第i层有t(i-1)个。所以,B树中可以存储的关键字数量为:
t^0 + t^1 + t^2 + ... + t^(h-1)
这是一个等比数列求和,和为:
(t^h - 1) / (t - 1)
乘以每个节点的最大关键字数量,即可得到B树中可以存储的最大关键字数量:
(2t - 1) * (t^h - 1) / (t - 1)
以下是使用Go语言实现的代码:
package mainimport ("fmt""math"
)func maxKeysInBTree(t int, h int) int {return int((2*float64(t) - 1) * (math.Pow(float64(t), float64(h)) - 1) / (float64(t) - 1))
}func main() {t := 3h := 4fmt.Printf("在高度为 %d 的 B 树中,最多可以存储 %d 个关键字。\n", h, maxKeysInBTree(t, h))
}
这段代码定义了一个名为maxKeysInBTree的函数,接受两个整数参数t和h,分别表示B树的最小度数和高度。函数返回一个整数,表示B树中可以存储的最多关键字数量。在main函数中,我们调用maxKeysInBTree函数并打印结果。
这篇关于文心一言 VS 讯飞星火 VS chatgpt (246)-- 算法导论18.1 4题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








