本文主要是介绍【高频】基于GBDT-FM模型的level-2高频数据实证研究(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【高频】基于GBDT-FM模型的level-2高频数据实证研究(二)
原创 Yud. 2AMquant 2024-04-04 11:30 广东
上一篇中初步提及了Level2数据中常见变量指标的构建方式,以及其带来的价格冲击。此篇将使用GBDT-LM模型对短程价格走势进行简单预测。
ps:此篇创作内容已于2020年10月9日发布在https://zhuanlan.zhihu.com/p/260959965
目录
-
前言
-
模型简介(GBDT-FM)
-
样本选择
-
实证研究
-
结论
-
参考文献
一、前言
订单簿揭示了资产交投的详细过程,在高频交易中,对股票进场和离场点的精确定位可以为长线交易者增厚收益,而越来越多的资管机构通过结合T0策略与alpha策略或者beta策略以增强收益。

市场流动性图(Bervas,2006);图来源:High-Frequency Trading
Aspects of market liquidity(Bervas,2006);图来源:High-Frequency Trading
短期价格走势的预测可以为高频交易者提供一个关于资产价格的粗略预期,可以对盘口未来的供需状况有一个初步的了解。上一篇研究中将定义了大量描述订单簿状态和盘口情况的指标,本文将根据这些指标对资产价格的短期走势进行预测。除了走势预测,一般进行高频交易中还会涉及走势持续的时长、概率(置信度)、信号强度等均是进行高频交易必须考虑的因素,在该系列中将持续从不同维度进行研究。
二、模型简介
机器学习模型在金融领域上最初的应用是预测。本文首先利用GBDT较强的学习能力对变量进行特征转换,随后再使用FM模型对资产的价格进行预测。价格走势的粗略预测是进行高频交易的不可缺少的一步。
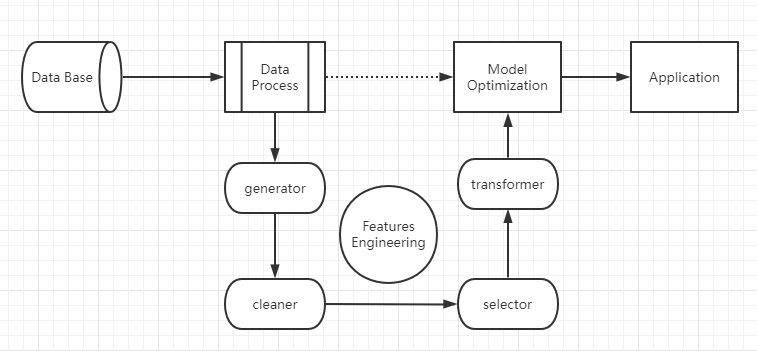
基于机器学习的Level-2数据研究流程
模型介绍
GBDT+LR是Facebook提出的CTR(click through rate)的预测模型,先使用GBDT进行特征转换(features transformation),随后再使用LR(Logistic Regression)训练模型。下文使用的GBDT-FM模型是2014年kaggle竞赛Display Advertising Challenge中第一名使用的机器学习算法;

GBDT+LR混合模型结构
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)
GBDT梯度提升决策树是一种采用预剪枝的迭代型决策树算法,广泛应用于分类、排序和各种机器学习竞赛中,通过学习率learning rate控制纠正前一颗树的强度,一般学习率越高,模型越复杂。同类boosting算法中的Xboosting适用于大规模数据中,adaboost使用FSAM进行优化,而GBDT始终在业界是很经典的集成算法。
GBDT+LR广泛应用与CTR预测,并且具有良好的解释能力,在Kaggle中很受欢迎,因此本文依旧选择GBDT进行特征转换,再基于新特征训练模型,缓解过拟合的问题。
GBM的通用算法:

GBM
FM(Factorization Machine,因子分解机)
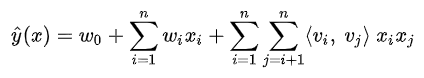
FM
其中x为特征,w为权重,v为表征向量
LR和FM可以处理离散数据,而FM适合处理交叉特征,DNN则可以处理更高阶和一些非线性的特征。有些研究报告使用SVM进行训练,SVM引入核函数的概念学习交叉项特征。SVM和FM的区别在于FM可以处理稀疏矩阵,而SVM泛化能力不足,在交叉项乘积为0时无法更新权重交叉项的权重。
量价之间的交互项影响了未来资产的买卖压力,因此本文使用LR而非LM。由于未进行特征选择会引入噪音,因此进行FM训练之前先进行特征选择。
同样,GBDT-FM广泛用于在电商中CRM的广告推荐中。
三、样本选择
本文所使用数据样本的level-2数据,包括十档交易数据、下单数据和成交数据。特征变量有上一篇中定义的各种买卖失衡指标和各种订单簿形态的描述性变量:订单不平衡、深度不平衡、宽度不平衡、买卖压力指标,各类价差、2-4档加权价、5-10档加权价、2-10档加权价、中间价等加权价格等。
四、实证部分
特征工程(Features Engineering)
本文中的特征工程仅指特征的生成、清洗、选择和转换。一些特定因子机器学习的挖掘项目中的特征工程部分还包括一些因子标准化、中性化等特定的操作。
特征选择(Selector)
使用迭代特征消除(Recursive feature elimination,RFE)进行特征选择,结果如下;可以看出压力指标、和深度和宽度的不平衡指标、价差和成交量对预期价格走势有决定性作用。

RFE;Recursive feature elimination
特征转换(Tranformer)
本文通过带交叉验证的网格搜索对GBDT进行调参,提升模型的泛化能力,根据所得参数后进行特征转换。为避免过拟合,本文定义模型的学习率为0.1。

通过网格搜索和交叉检验,当梯度提升的迭代次数,即弱分类器的个数为100时,决策树最大深度为2时,GBDT模型的效果较好,因此使用learning_rate=0.1,n_estimators = 100,max_depth=2作为参数对特征变量进行转换。
构建模型
下图展示了样本外该只股票某一天的测试结果,囿于篇幅限制,仅展示以下一个tick为预测目标的结果。红色和绿色标记点分别为预测下一个tick涨跌大于0和小于0的时刻,准确率达87.6%。
根据当前盘口的信息仅可以较好分析下一个tick的涨跌,但是当选择日内交易时,需要充分考虑当前订单簿中未成交订单中对未来价格产生影响的冲击与可能性。
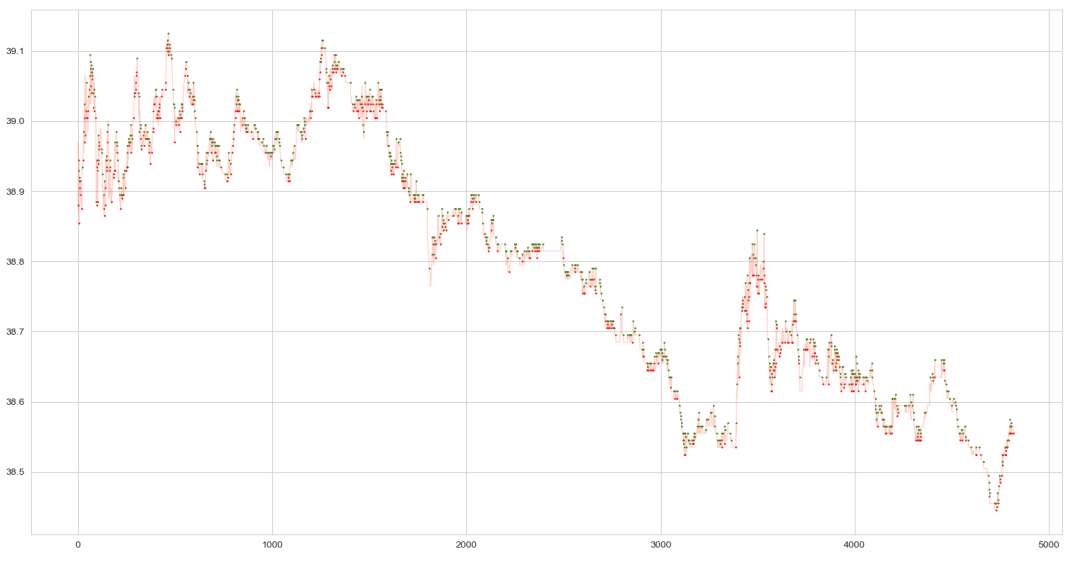
通过观察其他时间段的预测结果,部分预测结果显示,部分标记点密集的区域,价格却未给出明确的走势,在下一段时间出现震荡,意味着市场买卖双方存在博弈,一种解释是订单簿只显示了未成交订单的情况,而市价单对价格的走势更具有决定性作用,其次,通过阅读国外文献,本文认为冰山订单与探针类订单干扰了限价订单簿传递信息的作用,一些交易者为了试探“冰山订单”的存在或出于其他目的,会抛出大量订单然后撤回,这导致了订单簿上的信息并不能完全反应市场的真实需求,最后经分析发现当天的撤单量占总订单量的46%。
意味着在选择进场点和离场时需要结合其他分析指标。
五、结论
1.GBDT-FM对于预测下一个tick的价格走势有较好的预测能力,集成模型GBDT在特征工程中有较好效果
2.由于限价订单簿仅呈现了未成交订单,当选择日内交易时,需要充分考虑当前订单簿中未成交订单中对未来价格产生影响的冲击与可能性。
六、参考文献
1.限价订单市场价格发现动态过程研究
2.Modeling high frequency limit order book dynamics with support vector machines
3.Practical Lessons from Predicting Clicks on Ads at Facebook
4.Factorization Machines
5.Greedy function APPROXIMATION:A Gradient Boosting Machine
这篇关于【高频】基于GBDT-FM模型的level-2高频数据实证研究(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





