本文主要是介绍【python】python新闻文本数据统计和聚类 (源码+文本)【独一无二】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【python】python新闻文本数据统计和聚类 (源码+文本)【独一无二】
目录
- 【python】python新闻文本数据统计和聚类 (源码+文本)【独一无二】
- 一、设计要求
- 二、功能展示
- 2.1. 去除停用词
- 2.2 关键词提取
- 2.3. 聚类群集
- 2.4. 聚类可视化
- 三、代码解析
- 1. 导入库和设置基本信息
- 2. 读取中文停用词
- 3. 文本预处理函数
- 4. 提取文件夹内所有文件的预处理文本
- 5. 使用TF-IDF进行向量化
- 6. 执行KMeans聚类
- 7. 输出每个文件的聚类结果
- 8. 关键词提取
- 9. 展示每个文本的关键词
- 10. 使用PCA进行降维并绘制聚类结果
一、设计要求
新闻文本数据存储于文件“新闻文本”文件夹中
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
使用Python完成如下内容:
(1)使用代码打开给定文件夹中的文本文件进行内容读取,提取摘要内容(AB
标签内容)进行文本预处理(分词、停用词“中文停用词.txt”去除等),并展示结果;(2)提取每个 text 文本的关键词(词频或其他方法)并展示结果;
(3)使用词频或其他方法对每个 txt 进行向量表示,并基于此对文档进行聚类。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
二、功能展示
2.1. 去除停用词
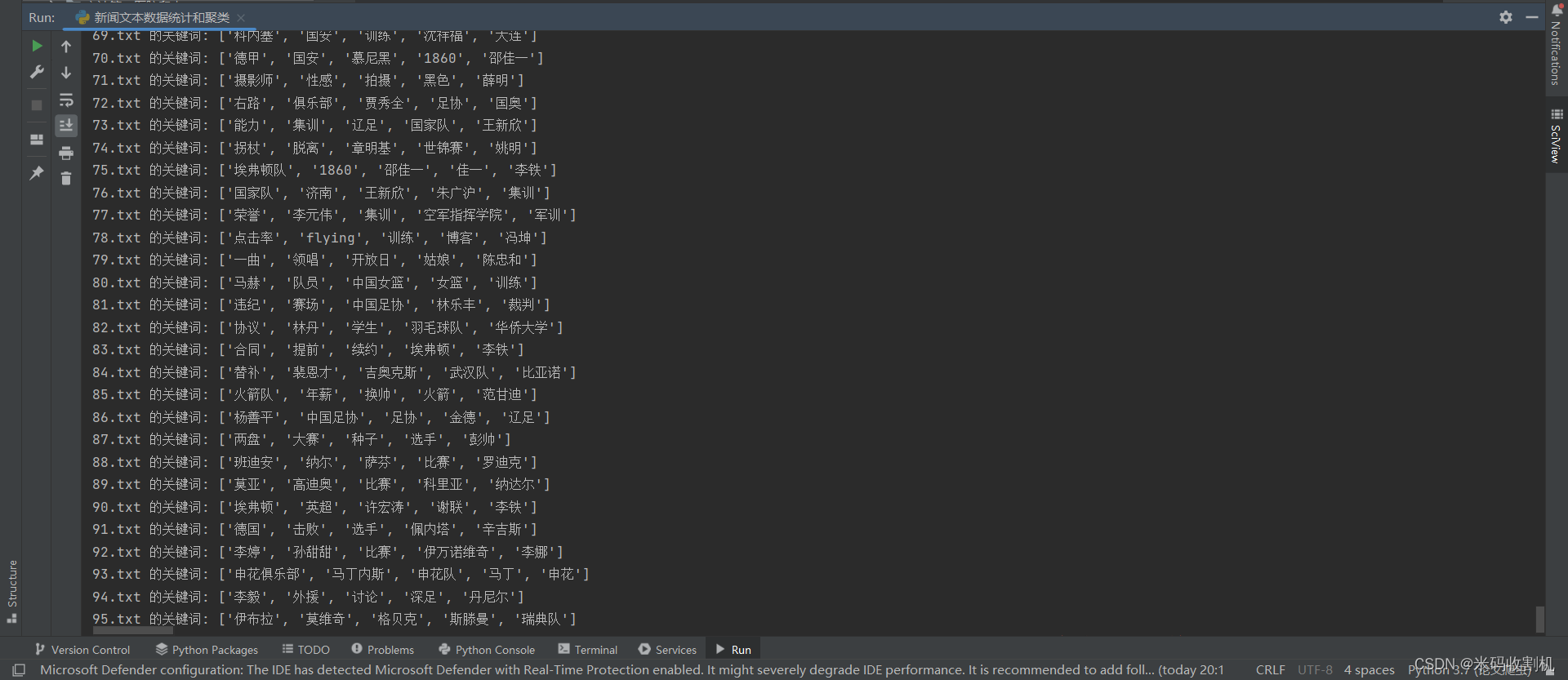
2.2 关键词提取
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
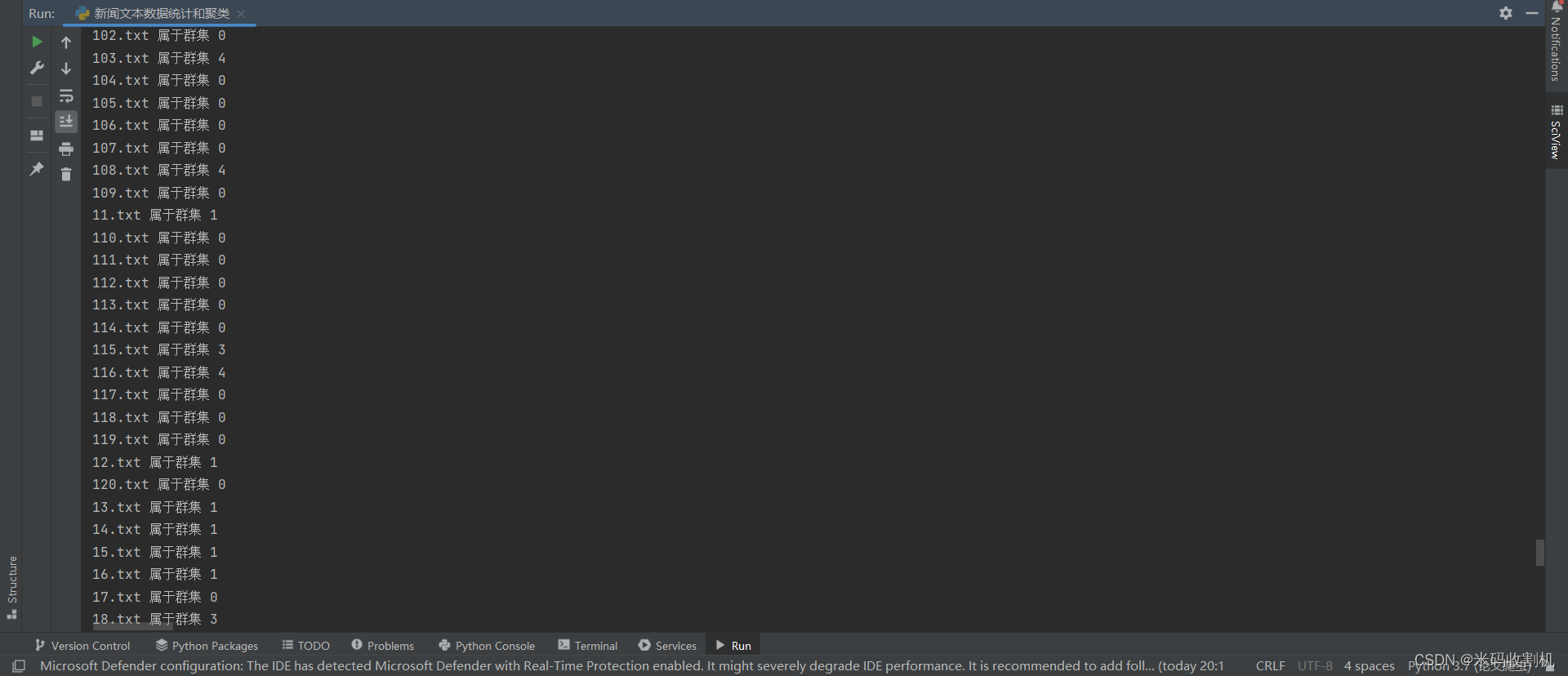
2.3. 聚类群集
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
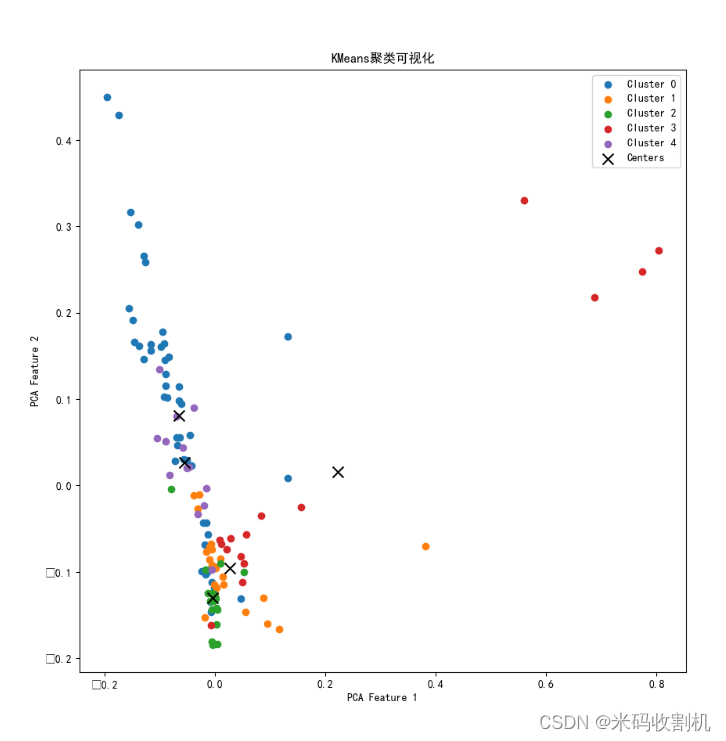
2.4. 聚类可视化
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
三、代码解析
1. 导入库和设置基本信息
import os
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import numpy as npplt.rcParams["font.sans-serif"] = ["SimHei"]folder_path = r'.\新闻文本'
首先,导入了所需的库,并设置了文件夹路径。代码中使用了jieba进行中文分词,TfidfVectorizer进行TF-IDF特征提取,KMeans进行文本聚类,matplotlib进行可视化,以及PCA进行数据降维。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
2. 读取中文停用词
with open('中文停用词.txt', 'r', encoding='utf-8') as f:stop_words = [line.strip() for line in f.readlines()]
这部分代码读取了中文停用词表,并将其存储在stop_words列表中。停用词通常是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉的字词。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
3. 文本预处理函数
def preprocess_text(file_path, stop_words):with open(file_path, 'r', encoding='gbk') as file:text = file.read()# 略....words = [word for word in words if word not in stop_words]return ' '.join(words)
该函数接收文件路径和停用词列表作为参数,读取文件内容,然后使用jieba进行中文分词,最后去除停用词并返回处理后的文本。
4. 提取文件夹内所有文件的预处理文本
texts = []
for file_name in os.listdir(folder_path):if file_name.endswith('.txt'):file_path = os.path.join(folder_path, file_name)try:# 略....except:continue
这部分代码遍历指定文件夹内的所有.txt文件,对每个文件调用预处理函数,并将处理后的文本添加到texts列表中。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
5. 使用TF-IDF进行向量化
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(texts)
这里使用TfidfVectorizer对预处理后的文本进行TF-IDF向量化,将文本转换为TF-IDF特征矩阵。
6. 执行KMeans聚类
num_clusters = 5
km = KMeans(n_clusters=num_clusters)
# 略....
使用KMeans算法对TF-IDF特征矩阵进行聚类,将文本数据分为预设的5个类别(num_clusters=5)。
7. 输出每个文件的聚类结果
clusters = km.labels_.tolist()
for file_name, cluster in zip(file_names, clusters):print(f'{file_name} 属于群集 {cluster}')
这部分代码输出了每个文件所属的聚类结果。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
8. 关键词提取
def extract_keywords(tfidf_matrix, vectorizer, top_n=5):indices = tfidf_matrix.toarray().argsort(axis=1)feature_names = vectorizer.get_feature_names_out()# 略....return keywords_list
这个函数用于从TF-IDF特征矩阵中提取关键词,选取每个文本中TF-IDF分数最高的词作为关键词。
9. 展示每个文本的关键词
keywords = extract_keywords(tfidf_matrix, vectorizer)
for file_name, keyword in zip(file_names, keywords):print(f'{file_name} 的关键词: {keyword}')
这部分代码展示了每个文本的关键词。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
10. 使用PCA进行降维并绘制聚类结果
pca = PCA(n_components=2)
two_dim_data = pca.fit_transform(tfidf_matrix.toarray())
这里使用PCA将TF-IDF特征矩阵降维到2维,以便于可视化展示。
plt.figure(figsize=(10, 10))
for i in range(num_clusters):points = two_dim_data[np.array(clusters) == i]plt.scatter(points[:, 0], points[:, 1], label=f'Cluster {i}')centers = pca.transform(km.cluster_centers_)
plt.scatter(centers[:, 0], centers[:, 1], s=100, c='black', marker='x', label='Centers')plt.title('KMeans聚类可视化')
plt.xlabel('PCA Feature 1')
plt.ylabel('PCA Feature 2')
plt.legend()
plt.show()
这段代码绘制了聚类结果的可视化图像,每个聚类用不同颜色表示,聚类中心用黑色叉号标记。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 新闻文本聚类 ” 获取。👈👈👈
这篇关于【python】python新闻文本数据统计和聚类 (源码+文本)【独一无二】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





