本文主要是介绍ROS2 王牌升级:Fast-DDS 性能直接碾压 zeroMQ 「下」,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以下内容为本人的学习笔记,如需要转载,请声明原文链接 微信公众号「ENG八戒」https://mp.weixin.qq.com/s/aU1l3HV3a9YnwNtC1mTiOA

性能比较
下面就以官网的测试数据为准,让我们一起来看看它们的性能差别到底怎样。
本次比较仅针对 Fast RTPS 和 ZeroMQ 的数据收发延迟和吞吐量两方面,传输模式都采用发布订阅制,而且会统一使用 Fast Buffers 序列化模块处理数据。
测试环境:
系统: Fedora 20 64bit as OS
硬件: Intel Core i3 @3.4GHz,4GB RAM,1Gbps Intel 千兆网络适配器
配置:
| 组件 | Fast RTPS | ZeroMQ |
|---|---|---|
| 版本 | 1.0 | 4.0.5 |
| 序列化 | Fast Buffers 0.3.0 | Fast Buffers 0.3.0 |
| 模式 | 基于UDP 的单播和多播,自动发现 | 发布订阅模式 |
Fast RTPS 和 ZeroMQ 有什么区别
Fast RTPS 的实时发布订阅模式是基于 UDP 协议实现,比较灵活而轻量,同时可靠性的实现是基于单播和多播时添加 ACK/NACK。
ZeroMQ 底层基于 TCP 协议实现,相对会消耗更多资源。
| 组件 | Fast RTPS | ZeroMQ |
|---|---|---|
| 传输 | 基于 UDP 协议实现,比较灵活而轻量,同时可靠性的实现是基于单播和多播时添加 ACK/NACK | 基于 TCP 协议实现,不支持多播 |
| 协议头 | RTPS 的协议头被设计得更加通用而灵活,包含比如关键主题、分发顺序等,所以协议头比较大 | 协议头比较小,不够灵活 |
| 节点发现 | 内置端点发现机制,Qos 兼容的情况下,只需指定主题名和主题数据类型,就可以自动匹配发布者和订阅者 | 不具备自动发现端点机制,实现通信前需要手动设置发布者和订阅者的 IP |
延迟对比
所谓的延迟就是消息从一端顺利到达另一端所花费的时间。
一般在分组网络里,延迟有两种的测量方法,单向延迟和往返延迟。单向延迟测量的是发送时间,而往返延迟测量的是发送和接收回复的总时间。
由于往返延迟可通过仅在一端测量完成,是常用测量方法。
一对一传输:
一对一传输的情况下,单向消息延迟的计算,开始于发布端对消息序列化,然后发送到订阅端,订阅端接收消息并逆序列化完成为止的时间。而往返消息延迟的计算,开始于发布端对消息序列化,然后发送到订阅端,订阅端接收并返回消息,发布端接收到返回消息完成为止的时间。
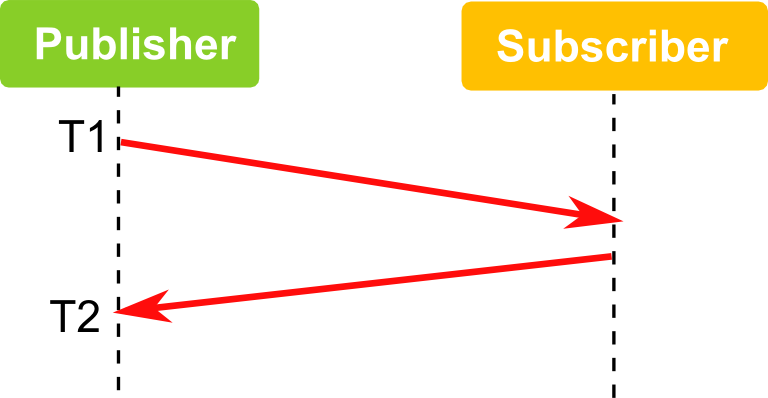
比如下面的图中,往返时间是 T2-T1,对应发布订阅模式中延迟时间将是 (T2-T1)/2。
看看 Fast RTPS 和 ZeroMQ 消息的延迟测试结果比较:
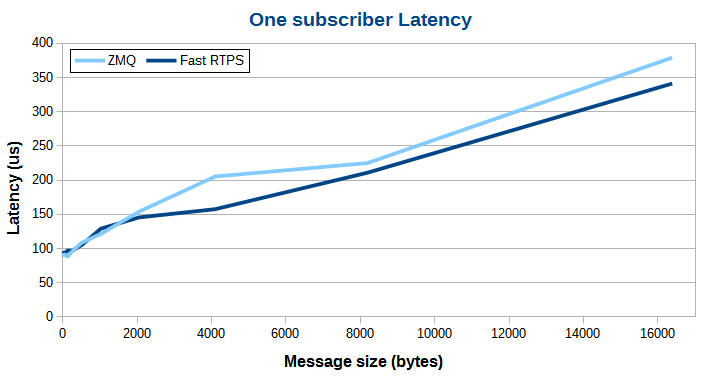
总体来看,Fast RTPS 和 ZeroMQ 传输延迟曲线都呈现线性,但是 Fast RTPS 斜率更低。可以看到,在数据量比较小时,ZeroMQ 的传输延迟更好一些。但随着数据量的增加,Fast RTPS 延迟增长变慢,最终明显好于 ZeroMQ,数据量越大差距越大,
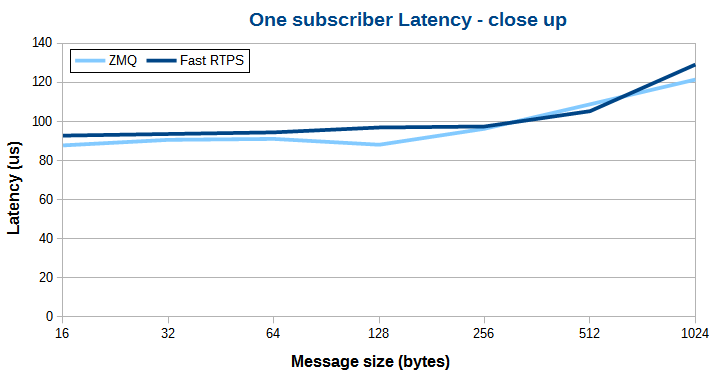
放大来看,当传输的数据量介乎 16 到 128 字节区间内时,ZeroMQ 的延时明显要更好,这归功于 ZeroMQ 的协议头比较小的原因。随着传输数据量的增加,协议头在整个数据包中的比例越来越小,对传输延迟的影响也越来越小,最终协议头小的优势失效。
一对多传输:
有多个订阅者的情况下,延迟测试和单个订阅者的测试类似,但多个订阅者接收到信息后只有一个订阅者会回复消息。往返时间是 T2-T1,对应发布订阅模式中延迟时间将是 (T2-T1)/2。
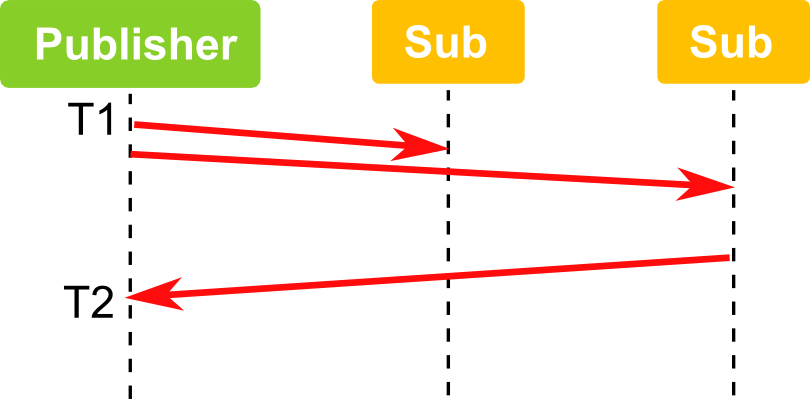
看看 Fast RTPS 和 ZeroMQ 消息的延迟测试结果比较:
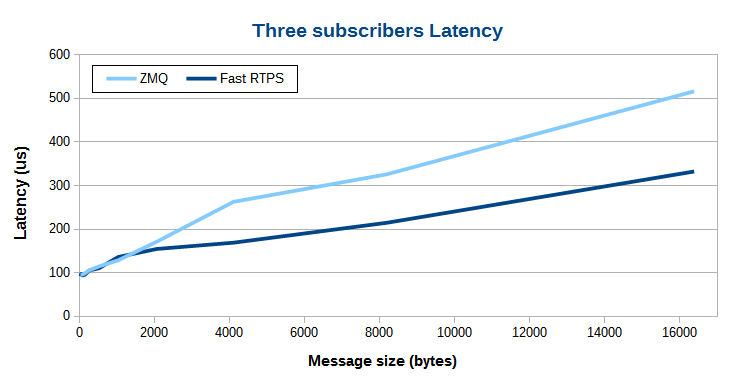
当传输数据量比较小时,Fast RTPS 和 ZeroMQ 延迟非常接近。数据量增大后,Fast RTPS 多播的优势越发明显,比如传输的数据量达到 16 KBytes 时,Fast RTPS 比 ZeroMQ 要快 200 us。
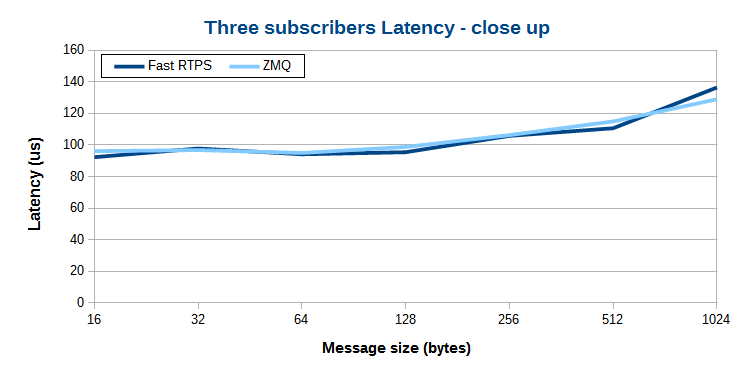
即使数据量较小,但由于 ZeroMQ 不支持多播,为了向多个订阅者发送数据,就必须多次发送,势必增大延迟。消息订阅者越多,ZeroMQ 的传输延迟越大。Fast RTPS 由于具备多播的能力,所以延迟增加比较慢。
吞吐量对比
在网络通信中,数据吞吐量一般指的是信道数据成功传输的速率,单位是字节每秒。
测量数据吞吐量的方法很多,比较常用的就是发送一个大文件或者多个小文件,假设文件总大小为 size,监测文件传送到接收端的时间为 T,那么最后吞吐量的计算结果是 size / T。
测试对比的时候,RTPS 在一定时间内发送多组消息,但是吞吐量不是一个固定值而是一个范围,既然是范围就有最大值,为了找到这个最大值,需要不断尝试不同的消息量 D,找到能实现发布者发送管道最大化同时订阅者接收没有丢包的值。测试过程可看下图:
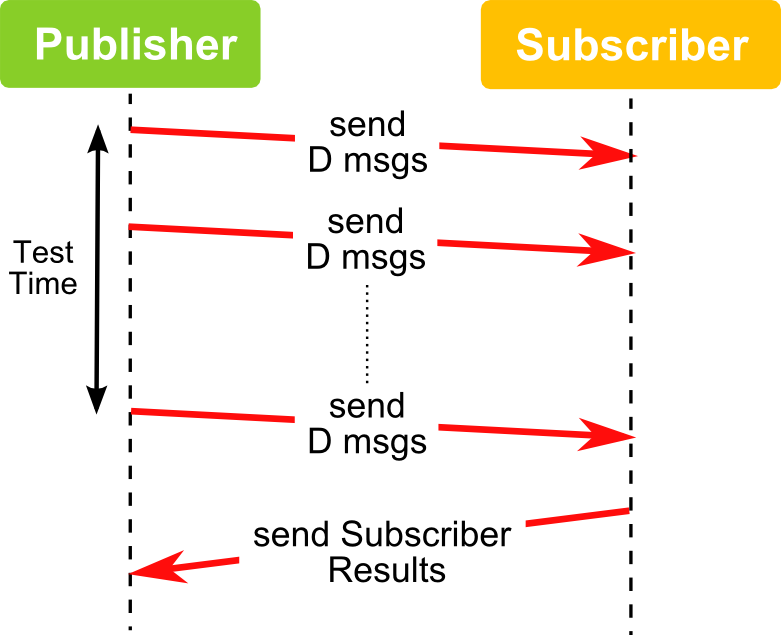
测试吞吐量同样既可以在发送端测试,也可以在接收端测试。两种测试方式在没有丢包的情况下是基本一致的,细微的差别来自于测试的时间有差异。如果存在丢包,吞吐量测试结果就依赖于在哪一端测试。为了统一测试规则,我们假设接收端没有丢包,吞吐量监测放在发送端。
再来看看 ZeroMQ 和 Fast RTPS 的数据吞吐量测试结果对比:

可以看到,ZeroMQ 在小数据量传输时数据吞吐量更高,这是由于 TCP 协议是经过吞吐量优化的流协议,会自动将多个小包合并成一包发送。而 Fast RTPS 如果需要实现类似的操作,需要额外使用主题的类型数组。
另外,相对地 ZeroMQ 需要比较大的数据量才能达到最大吞吐量,而 Fast RTPS 则能更快达到最大吞吐量,大概在 1000 字节的消息大小时超过 ZeroMQ。
总结
全文已结束,看到这里,你是否对 Fast RTPS 有了初步认识?终于明白为什么 ROS2 采用它作为底层通信的默认实现了吧?如果你有什么想法,可以直接在后台回复我,八戒恭候多时!
最后,非常感激各位朋友的点 「赞」 和点击 「在看」,谢谢!
这篇关于ROS2 王牌升级:Fast-DDS 性能直接碾压 zeroMQ 「下」的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







