本文主要是介绍Python爬虫爬取中药材价格数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🎈 博主:一只程序猿子
🎈 博客主页:一只程序猿子 博客主页
🎈 个人介绍:爱好(bushi)编程!
🎈 创作不易:喜欢的话麻烦您点个👍和⭐!
🎈 欢迎访问我的主页(点我直达)
🎈 除此之外您还可以通过个人名片联系我

额滴名片儿
目录
1.介绍
2.网页分析
(1)市场价格数据
(2)药材历史价格数据
3.设计
(1)数据库设计
(2)代码结构
4.源码
5.测试
1.介绍
本文将介绍如何编写Python爬虫,从中药材天地网,爬取中药材的市场价格和某几种中药材的历史价格数据,在下一篇文章中我们将根据这些数据,做一个简单的基于Flask的中药材价格数据分析与可视化系统。
2.网页分析
(1)市场价格数据
其中我们需要获取到的市场价格数据来自如下图片标示的位置:
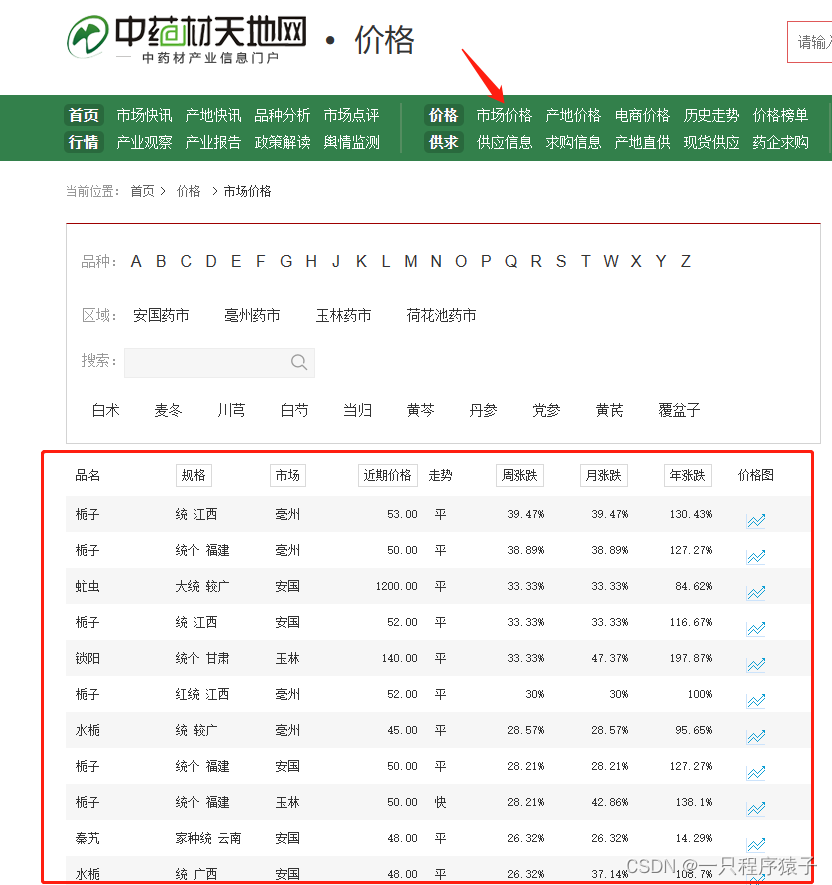
在页面底部有翻页按钮:
 再看看数据在html中的位置:
再看看数据在html中的位置:
首先可以看到表格的表头在文件中的位置。

这是表格数据的位置:
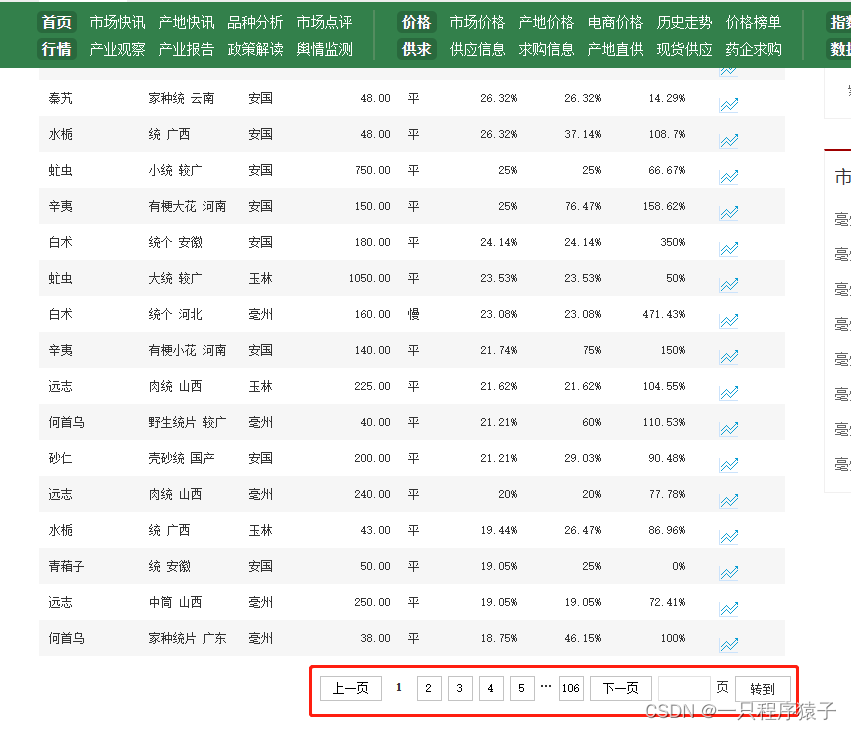
 这是翻页按钮的位置:
这是翻页按钮的位置:
 这里可以很容易发现规律,既翻页是通过修改url的最后一位数字实现的。
这里可以很容易发现规律,既翻页是通过修改url的最后一位数字实现的。
(2)药材历史价格数据
这里我们偷懒,只爬取四种中药材的历史价格数据,分别是白术、麦冬、川芎和白芍。

我们只爬取这四种药材在亳州药市,规格一的历史价格数据。
 现在我们看下数据是怎么获取的 :
现在我们看下数据是怎么获取的 :
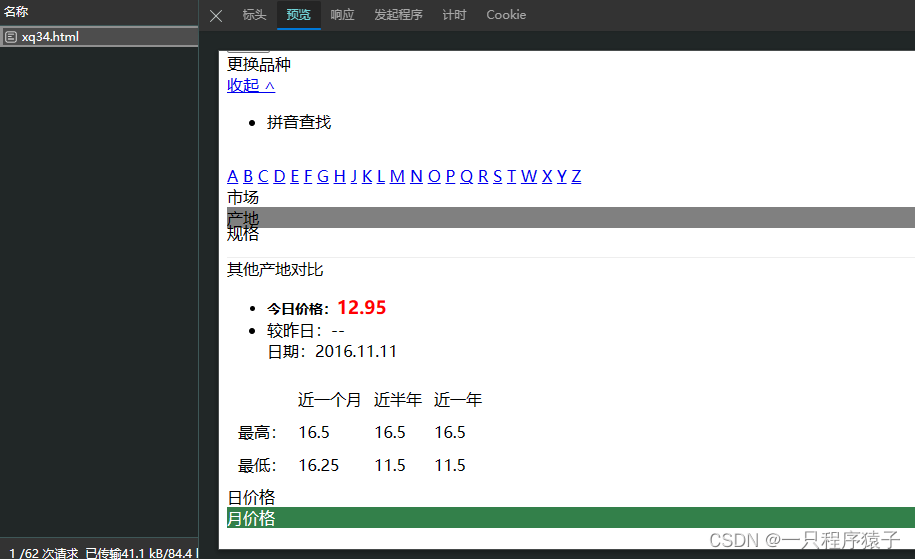
通过开发者工具中的网络,很容易发现这个页面是一个动态页面,数据并不能在html中直接获取。

我们来抓下包看看:
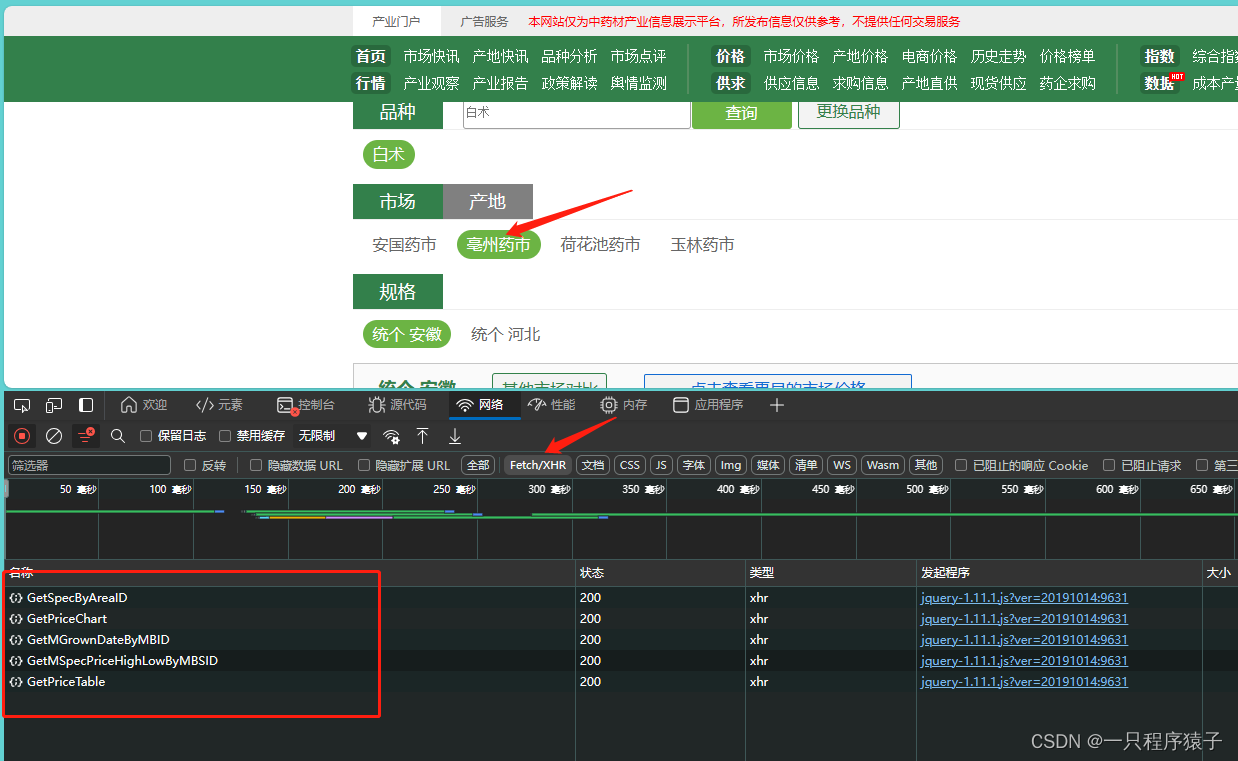 很容易我们找到了我们想要的数据:
很容易我们找到了我们想要的数据:
看一下请求头和需要什么参数: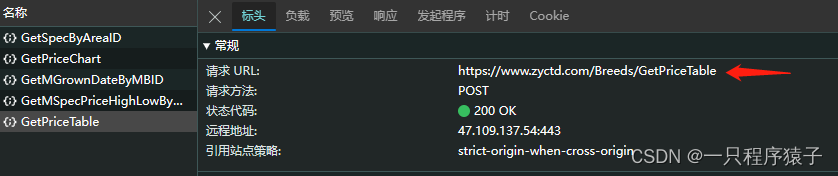

然后可以找到mid从哪获取的:
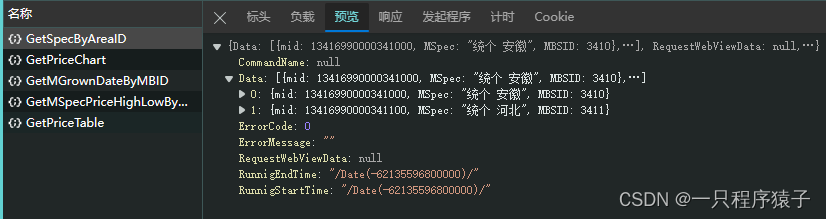
再看一下它的请求头和参数:

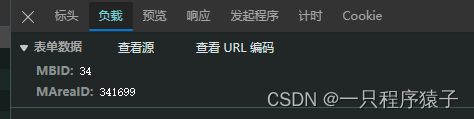
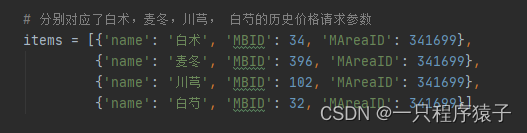
因为我们只爬取四种中药材的历史价格,所以我们手动找到这四种中药材的MBID和MAreaID即可:
3.设计
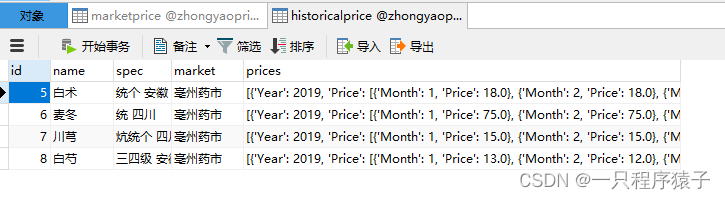
(1)数据库设计
总共设计了两张表,marketprice表用来存储药材的市场价格数据,historicalprice表用来存储四种药材的历史价格数据。
表结构如下:


(2)代码结构

4.源码
db_helper.py:
import pymysql"""数据库操作"""class DBHelper(object):def __init__(self):pymysql.version_info = (1, 4, 13, "final", 0) # 必须有这个不然会报版本不对错误pymysql.install_as_MySQLdb() # 使用pymysql代替mysqldb连接数据库# 建立数据库连接self.conn = pymysql.connect(host="127.0.0.1",port=3306,user="用户名",passwd="密码",db="zhongyaoprice_demo")# 通过 cursor() 创建游标对象,并让查询结果以字典格式输出self.cur = self.conn.cursor(cursor=pymysql.cursors.DictCursor)def __del__(self): # 对象资源被释放时触发,在对象即将被删除时的最后操作# 关闭游标self.cur.close()# 关闭数据库连接self.conn.close()def select_db(self, sql):"""查询"""# 使用 execute() 执行sqlself.cur.execute(sql)# 使用 fetchall() 获取查询结果data = self.cur.fetchall()return datadef execute_db(self, sql):"""更新/插入/删除"""try:# 使用 execute() 执行sqlself.cur.execute(sql)# 提交事务self.conn.commit()except Exception as e:print("操作出现错误:{}".format(e))# 回滚所有更改self.conn.rollback()def execute_db_ex(self, sql, params):"""更新/插入/删除"""try:# 使用 execute() 执行sqlself.cur.execute(sql, params)# 提交事务self.conn.commit()except Exception as e:print("操作出现错误:{}".format(e))# 回滚所有更改self.conn.rollback()def save_market_price(self, zhongyao):"""查找或者保存中药材市场价格"""select_sql_temp = "select * from marketprice where name = '%s' and spec = '%s'" % (zhongyao[0], zhongyao[1])result = self.select_db(select_sql_temp)if result is None or len(result) == 0:self.execute_db_ex("insert into marketprice (name, spec, market, recentprice, tendency, ""weeklyfluctuation, monthlyfluctuation, yearlyfluctuation)"" values (%s,%s,%s,%s,%s,%s,%s,%s) ",(zhongyao[0], zhongyao[1], zhongyao[2], zhongyao[3], zhongyao[4], zhongyao[5],zhongyao[6], zhongyao[7]))print(f'中药材:{zhongyao[0]},规格:{zhongyao[1]} 的市场价格信息保存成功!!!')else:print(f'该规格的中药材:{zhongyao[0]} 的市场价格信息已在数据库存在!!!')def save_historical_price(self, prices_info):"""查找或者保存中药材历史价格"""select_sql_temp = "select * from historicalprice where name = '%s' and spec = '%s'" % (prices_info[0], prices_info[1])result = self.select_db(select_sql_temp)if result is None or len(result) == 0:self.execute_db_ex("insert into historicalprice (name, spec, market, prices)"" values (%s,%s,%s,%s) ",(prices_info[0], prices_info[1], '亳州药市', prices_info[2]))print(f'中药材:{prices_info[0]},规格:{prices_info[1]} 的历史价格信息保存成功!!!')else:print(f'该规格的中药材:{prices_info[0]} 的历史价格信息已在数据库存在!!!')
settings.py:
HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'none','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0','sec-ch-ua': '"Microsoft Edge";v="123", "Not:A-Brand";v="8", "Chromium";v="123"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}COOKIES = {'FromsAuthByDbCookie_zytd_Edwin.PrvGuest': '1c1uuuuuuuuuuaI98Rb8c9916R6R18a8U1da851Rd59Ud4S49c40o5qqnc78ca99o698qac9nadmoll5moad015','Hm_lvt_ba57c22d7489f31017e84ef9304f89ec': '1713054805,1713141612','Hm_lpvt_ba57c22d7489f31017e84ef9304f89ec': '1713143695',
}
spider.py:
if __name__ == '__main__':for i in range(1, 31):url = f'https://www.zyctd.com/jiage/1-0-341699-{i}.html'print(f'开始爬取第 {i} 页!')get_market_price(url)if i < 30:print('休息两秒然后继续')else:print('爬取完毕,再见!')time.sleep(2)# 分别对应了白术,麦冬,川芎, 白芍的历史价格请求参数items = [{'name': '白术', 'MBID': 34, 'MAreaID': 341699},{'name': '麦冬', 'MBID': 396, 'MAreaID': 341699},{'name': '川芎', 'MBID': 102, 'MAreaID': 341699},{'name': '白芍', 'MBID': 32, 'MAreaID': 341699}]get_historical_price(items)篇幅有限,spider.py我只在此展示了部分源码,可以通过文章底部个人名片联系我获取完整代码!
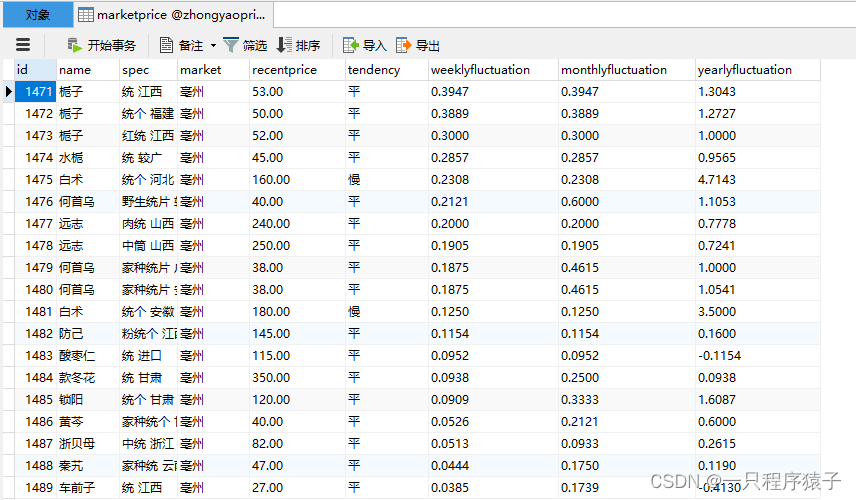
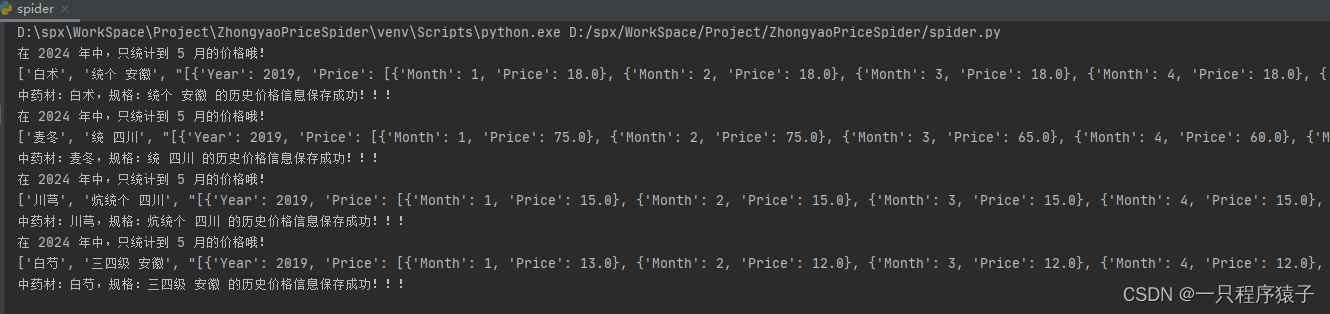
5.测试
运行spider.py:

这篇关于Python爬虫爬取中药材价格数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



