本文主要是介绍回溯算法练习day.3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
39.组合总和
链接:. - 力扣(LeetCode)
题目描述:
给你一个 无重复元素 的整数数组
candidates和一个目标整数target,找出candidates中可以使数字和为目标数target的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。对于给定的输入,保证和为
target的不同组合数少于150个。示例 1:
输入:candidates =[2,3,6,7],target =7输出:[[2,2,3],[7]] 解释: 2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。 7 也是一个候选, 7 = 7 。 仅有这两种组合。提示:
1 <= candidates.length <= 302 <= candidates[i] <= 40candidates的所有元素 互不相同1 <= target <= 40
思路:
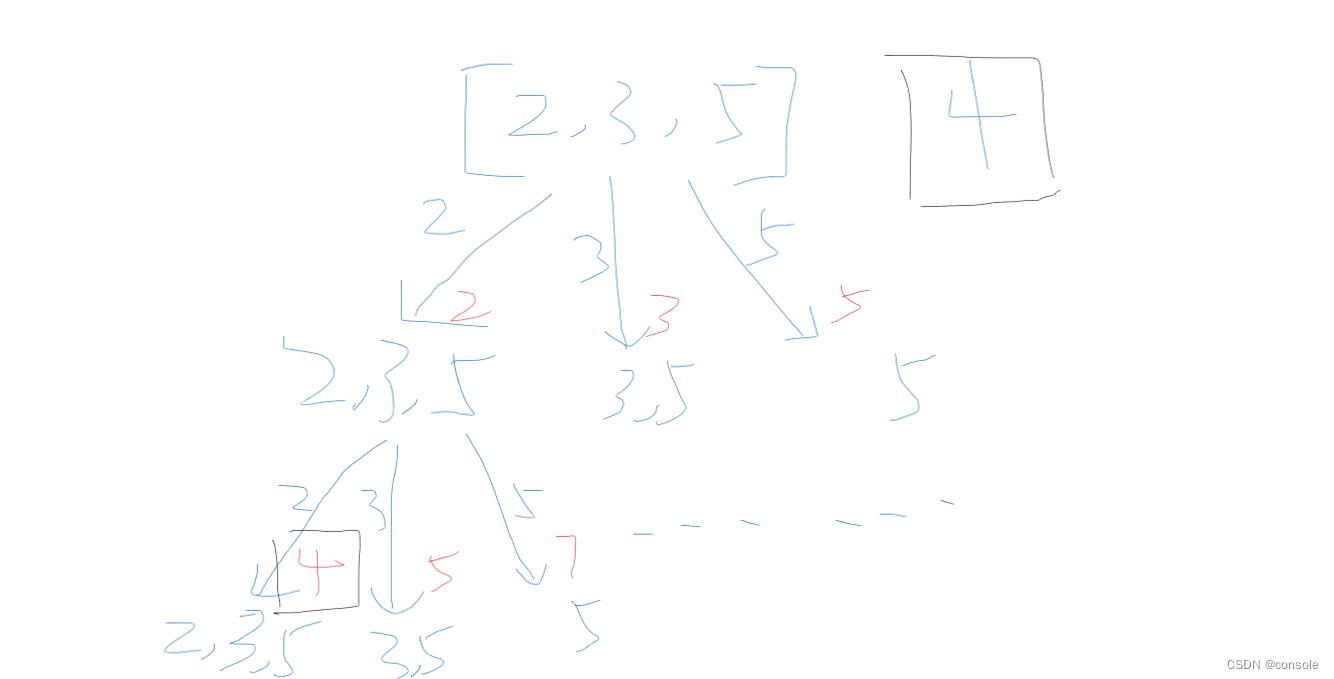
我们以集合[2,3,5]为例子,目标值为4,因为是组合问题,因此选择回溯算法来解决,因为可以选择重复的元素,因为我们可以抽象出如下的树形结构
回溯实现:
1.确定函数参数和返回值,回溯算法返回值一般为空,传入的应该是集合和目标值,统计当前的目标值和,开始遍历的位置
2.确定终止条件,当查找到我们的目标值时,记录值,如果当前值大于目标值则退出
3.确定单层递归逻辑,收集节点元素,更新当前值,递归,回溯
代码如下:
int* path; // 用于存储当前组合的路径 int pathTop; // 记录当前路径的长度 int** result; // 存储所有和等于目标值的组合 int resulttop; // 记录结果数组的长度 // 记录每一个和等于target的path数组长度 int* len; // 记录每个组合的长度void backTracking(int target, int index, int* candidates, int candidatesSize, int sum) {// 若sum大于等于target就应该终止遍历if(sum >= target) {// 若sum等于target,将当前的组合放入result数组中if(sum == target) {// 创建临时数组来存储当前路径int* tempPath = (int*)malloc(sizeof(int) * pathTop);int j;// 复制当前路径到临时数组中for(j = 0; j < pathTop; j++) {tempPath[j] = path[j];}// 将临时数组存入结果数组中result[resulttop] = tempPath;// 记录当前组合的长度len[resulttop++] = pathTop;}return ;}int i;for(i = index; i < candidatesSize; i++) {// 将当前数字加入sumsum += candidates[i];// 将当前数字加入路径path[pathTop++] = candidates[i];// 递归调用backTrackingbackTracking(target, i, candidates, candidatesSize, sum);// 回溯,将当前数字从sum和路径中移除sum -= candidates[i];pathTop--;} }int** combinationSum(int* candidates, int candidatesSize, int target, int* returnSize, int** returnColumnSizes){// 初始化变量path = (int*)malloc(sizeof(int) * 50);result = (int**)malloc(sizeof(int*) * 200);len = (int*)malloc(sizeof(int) * 200);resulttop = pathTop = 0;// 调用回溯函数找到所有组合backTracking(target, 0, candidates, candidatesSize, 0);// 设置返回的数组大小*returnSize = resulttop;*returnColumnSizes = (int*)malloc(sizeof(int) * resulttop);int i;for(i = 0; i < resulttop; i++) {// 将每个组合的长度存入返回数组中(*returnColumnSizes)[i] = len[i];}// 返回结果数组return result; }
40.组合总和II
链接:. - 力扣(LeetCode)
题目描述:
给定一个候选人编号的集合
candidates和一个目标数target,找出candidates中所有可以使数字和为target的组合。
candidates中的每个数字在每个组合中只能使用 一次 。注意:解集不能包含重复的组合。
示例 1:
输入: candidates =[10,1,2,7,6,1,5], target =8, 输出: [ [1,1,6], [1,2,5], [1,7], [2,6] ]提示:
1 <= candidates.length <= 1001 <= candidates[i] <= 501 <= target <= 30
思路:
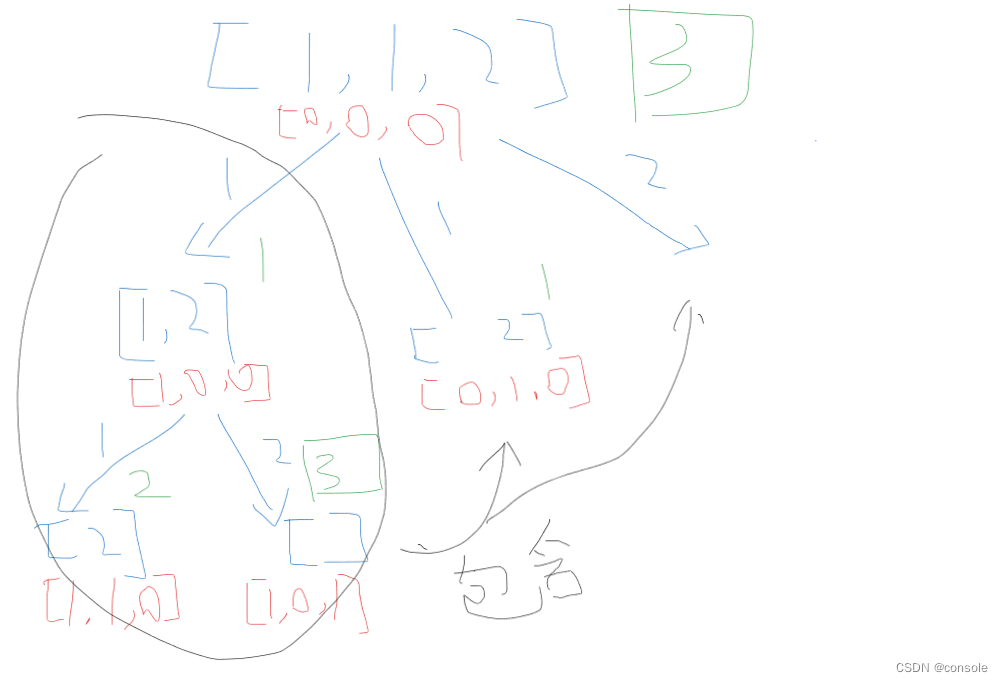
因为题目给的数组里有重复元素,但是在解集中不能有重复的组合,因此我们要实现一个去重操作,我们可以使用一个数组来标记题目给的集合,当集合中的元素没有使用时,我们标记为0,如果使用过则标记为1,因为题目中要求不能使用同一个元素,这里的同一个元素是指下标位置相同的元素,而不是值相同,我们可以抽象为树形结构
在这里我们第一条路径下是从第1个1往后取的,它还会包括后面的路径,因为题目要求组合不能重复,因此后面的两个分支是没有必要的,如果再去搜索就会重复,因此这里去重的关键就是在每一层(横向)中进行去重,出现过的就不需要再去遍历,而纵向是不需要的,因为可以使用
回溯实现:
1.确定函数参数和返回值,回溯一般不需要返回值,参数应该为题目的集合,目标值,当前总和,每层开始遍历位置,使用一个数组标记我们使用过的元素
2.确定终止条件,如果当前值超过目标值,则退出,如果相等,则进行存储
3.确定单层递归,判断当前元素是否与前一个元素相同(排序后的集合)且是否它的标记数组的值为0,相同则进行去重
代码实现:
/*** 返回一个大小为*returnSize的数组的数组。* 数组的大小作为*returnColumnSizes数组返回。* 注意:返回的数组和*columnSizes数组都必须是malloced,假设调用者调用free()。*/int *path; // 路径数组 int pathtop; // 路径数组的顶部索引int **result; // 结果数组 int resulttop; // 结果数组的顶部索引int *len; // 每个结果数组的长度// 比较函数 int cmp(const void *a1, const void *a2) {return *((int *)a1) - *((int *)a2); } // 回溯函数 void backtracking(int *candidates, int candidatesSize, int target, int sum, int startindex) {// 如果当前累计和大于等于目标值if(sum >= target){// 如果当前累计和等于目标值if(sum == target){// 分配临时数组存储当前路径int *temp = malloc(sizeof(int) * pathtop);for(int i = 0; i < pathtop ; i++)temp[i] = path[i];// 将当前路径长度存储到结果数组的长度数组中len[resulttop] = pathtop;// 将当前路径存储到结果数组中result[resulttop++] = temp;}return ;}// 遍历候选数组for(int i = startindex; i < candidatesSize; i++){// 如果当前元素与上一个相同,则跳过,避免重复组合if(i > startindex && candidates[i] == candidates[i-1])continue;// 将当前元素加入路径数组path[pathtop++] = candidates[i];// 更新累计和sum += candidates[i];// 递归调用回溯函数,更新累计和、路径数组的下一个起始索引backtracking(candidates, candidatesSize, target, sum, i+1);// 回溯,将当前元素从路径中移除sum -= candidates[i];pathtop--;} } int** combinationSum2(int* candidates, int candidatesSize, int target, int* returnSize, int** returnColumnSizes) {// 分配内存path = (int *)malloc(sizeof(int) * 50);result = (int **)malloc(sizeof(int *) * 100);len = (int *)malloc(sizeof(int) * 100);// 对候选数组排序qsort(candidates, candidatesSize, sizeof(int), cmp);pathtop = resulttop = 0;// 回溯backtracking(candidates,candidatesSize,target,0,0);// 设置返回的结果数量*returnSize = resulttop;// 分配每个结果数组的大小*returnColumnSizes = (int *)malloc(sizeof(int) * resulttop);for(int i = 0; i < resulttop; i++)(*returnColumnSizes)[i] = len[i];return result; }注意:
qsort函数是C标准库中的一个函数,用于对数组进行排序,其作用是对一个数组进行快速排序,可以按照用户提供的比较函数定义的规则,对数组元素进行排序,即qsort函数的作用是将一个数组按照指定的排序规则进行重新排列,以使得数组中的元素按照指定的顺序排列,排序的顺序可以是升序或者降序,具体取决于用户提供的比较函数,原型如下:void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));
base是待排序数组的起始地址nmemb是数组中元素的个数size是每个元素的大小(以字节为单位)compar是一个函数指针,指向一个比较函数,用于确定元素的顺序代码中的cmp函数是比较函数
它将
a1和a2强制转换为int*类型,然后分别取出其指向的整数值,并将其进行比较。函数的返回值是一个整数,表示两个值的大小关系:如果
a1所指向的值小于a2所指向的值,返回负数(<0)如果
a1所指向的值等于a2所指向的值,返回零(0)如果
a1所指向的值大于a2所指向的值,返回正数(>0)这样定义的比较函数用于
qsort函数时,可以根据返回值的不同,实现升序或降序排列
131.分割回文串
链接:. - 力扣(LeetCode)
题目描述:
给你一个字符串
s,请你将s分割成一些子串,使每个子串都是回文串
。返回
s所有可能的分割方案。示例 1:
输入:s = "aab" 输出:[["a","a","b"],["aa","b"]]示例 2:
输入:s = "a" 输出:[["a"]]提示:
1 <= s.length <= 16s仅由小写英文字母组成
思路:
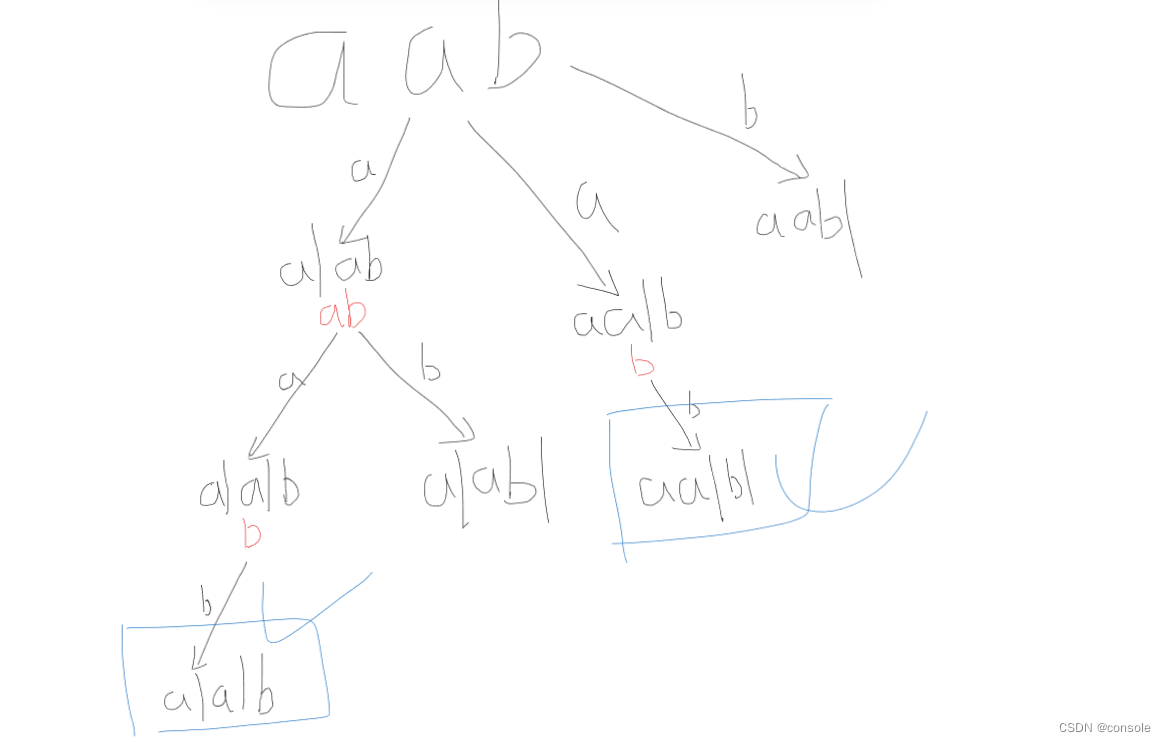
因为是分割问题,因此可以使用回溯算法来解决,因此我们就可以抽象为一个树形结构
在这里就可以看出我们的结果都在叶子节点,就是已经将字符串完全切割之后所得的结果
函数实现:
1.确定参数和返回值,题目提供的字符串,每次开始切割的位置(相当于切割线),返回值一般为空
2.确定终止条件,当切割线到达末尾,则到达叶子节点,收集结果
3.确定单层递归,判断子串是否回文,如果是则收集子串,否则直接跳过,进行递归,回溯
代码如下:
char** path; // 用于存储回文子串的数组 int pathTop; // 记录path数组的当前索引char*** ans; // 存储最终结果的数组 int ansTop = 0; // 记录ans数组的当前索引 int* ansSize; // 记录每个结果的长度的数组void copy() {// 复制path数组到临时数组char** tempPath = (char**)malloc(sizeof(char*) * pathTop);int i;for(i = 0; i < pathTop; i++) {tempPath[i] = path[i];}// 将临时数组加入到结果数组中,并记录其长度ans[ansTop] = tempPath;ansSize[ansTop++] = pathTop; }bool isPalindrome(char* str, int startIndex, int endIndex) {// 检查给定范围内的字符串是否为回文while(endIndex >= startIndex) {if(str[endIndex--] != str[startIndex++])return 0;}return 1; }char* cutString(char* str, int startIndex, int endIndex) {// 截取给定范围内的字符串char* tempString = (char*)malloc(sizeof(char) * (endIndex - startIndex + 2));int i;int index = 0;for(i = startIndex; i <= endIndex; i++)tempString[index++] = str[i];tempString[index] = '\0';return tempString; }void backTracking(char* str, int strLen, int startIndex) {// 回溯函数,用于搜索所有可能的回文分割方案if(startIndex >= strLen) {// 如果已经遍历完字符串,将当前方案加入到结果中copy();return ;}int i;for(i = startIndex; i < strLen; i++) {if(isPalindrome(str, startIndex, i)) {// 如果从startIndex到i的子串是回文,则加入到path数组中path[pathTop++] = cutString(str, startIndex, i);}else {continue;}// 递归搜索剩余部分backTracking(str, strLen, i + 1);// 回溯,尝试其他可能的回文子串pathTop--;} }char*** partition(char* s, int* returnSize, int** returnColumnSizes){// 分割字符串s成回文子串的函数int strLen = strlen(s);path = (char**)malloc(sizeof(char*) * strLen);ans = (char***)malloc(sizeof(char**) * 40000);ansSize = (int*)malloc(sizeof(int) * 40000);ansTop = pathTop = 0;backTracking(s, strLen, 0);*returnSize = ansTop;*returnColumnSizes = (int*)malloc(sizeof(int) * ansTop);int i;for(i = 0; i < ansTop; ++i) {(*returnColumnSizes)[i] = ansSize[i];}return ans; }
这篇关于回溯算法练习day.3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









