本文主要是介绍向量数据库Chroma初步了解学习记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
一、Chroma是什么?
二、使用步骤
1.安装
2.连接Chroma
内存模式
client模式
Server模式
3.创建数据集
4.写入数据
5.查询数据
6.完整代码
7.更多参考
三、瞅瞅chroma之sqlite
总结
前言
大模型很强大,但是大模型也存在知识的局限性,即大模型的知识受限于大模型训练日期,大模型的知识是有截止日期的,不是实时的;再一个有些数据是私有的,大模型也无从知晓。
那么RAG就有了用武之地。而Rag这块就不得不提到向量数据库。
虽然传统数据库也可以进行数据查询检索,但是传统数据库是基于关键词,是没有语义理解的。而向量数据库可以进行语义理解,本质上其实是将语言文字做了向量化,即语义空间,语义相近的向量信息也接近。
向量数据库目前也有很多产品,入门简单的首推Chroma,今天就介绍下
一、Chroma是什么?
ChromaDB(也称为Chroma)是一个开源的向量数据库,主要用于AI和机器学习场景。它的主要功能是存储和查询向量数据,这些数据通常是通过嵌入(embedding)算法从文本、图像等数据转换而来的。ChromaDB的设计目标是简化大模型应用的构建过程,允许开发者轻松地将知识、事实和技能等文档整合进大型语言模型(LLM)中。
ChromaDB的特点包括:
- 轻量级: 它是一个基于向量检索库实现的轻量级向量数据库。
- 易用性: 提供简单的API,易于集成和使用。
- 功能丰富: 支持存储嵌入及其元数据、嵌入文档和查询、搜索嵌入等功能。
- 集成: 可以直接插入LangChain、LlamaIndex、OpenAI等。
- 多语言支持: 包括Python和JavaScript客户端SDK。
- 开源: 采用Apache 2.0开源许可。
ChromaDB的一些限制包括目前只支持CPU计算,不支持GPU加速,且功能相对简单。不过,它计划未来推出托管产品,提供无服务器存储和检索功能,支持向上和向下扩展,让开发者更易于使用。
二、使用步骤
1.安装
ChromaDB的安装简单,可以通过pip或npm进行安装。在Python中,可以通过运行pip install chromadb来安装ChromaDB。
2.连接Chroma
内存模式
数据存在内存,程序运行完数据也就没了
import chromadb
from chromadb.config import Settingschroma_client = chromadb.Client(Settings(allow_reset=True))# 为了演示,实际不需要每次 reset()
# chroma_client.reset()client模式
直接连接本地数据库文件,类似sqlite(看了下,Chroma底层存储就是基于sqlite,后面可以简单说下)
import chromadb
# chroma_client = chromadb.Client()
chroma_client = chromadb.PersistentClient(path="E:\Data\chroma\mydb.db")Server模式
cmd
chroma run --path E:\Data\chroma\test这个时候会以命令中指定的路径,创建数据库文件,并启动Chroma服务
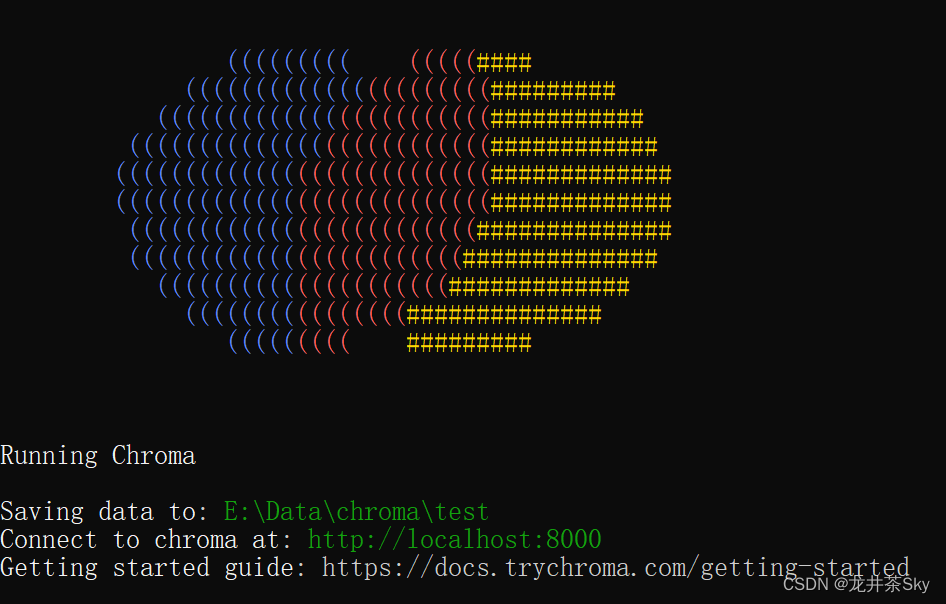
回到代码
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', port=8000)3.创建数据集
collection类似关系型数据库的表
collection = chroma_client.get_or_create_collection(name=collection_name)4.写入数据
collection.add(# embeddings=self.embedding_fn(documents), # 每个文档的向量documents=documents, # 文档的原文ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id)embeddings参数是文档的向量,这里一般需要调用大模型的embedding模型接口
如果不设置,那么会使用内置的embedding模型
5.查询数据
res=collection.query(query_texts=["查询内容"],n_results=5)6.完整代码
import chromadb# collection名称
collection_name="test_01"def init_db_client():"""初始化数据库客户端"""chroma_client = chromadb.HttpClient(host='localhost', port=8000)return chroma_clientdef create_collection(collection_name):"""创建collection"""chroma_client = init_db_client()collection=chroma_client.get_or_create_collection(name=collection_name)return collectiondef add_documents(collection, documents):"""写入数据"""collection.add(# embeddings=self.embedding_fn(documents), # 每个文档的向量documents=documents, # 文档的原文ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id)def db_test():collection = create_collection(collection_name)datas=["小明喜欢吃苹果", "小红喜欢吃榴莲","小明的女朋友是小丽","王老师是一个好老师","小李喜欢吃香蕉","小王的男朋友是大帅哥"]add_documents(collection, datas)# 查询数据res=collection.query(query_texts=["谁是老师"],n_results=5)print(res)db_test()7.更多参考
向量数据库Chroma极简教程 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/665715823?utm_id=0
https://zhuanlan.zhihu.com/p/665715823?utm_id=0
三、瞅瞅chroma之sqlite
看下chroma数据库文件可以发现其数据库实际名称是:chroma.sqlite3
然后我试着用sqlite数据库工具是可以打开这个数据库文件的,有一些固化的表,随便看了下,也是可以找到我写入的数据的。
比如:
collections:新建一个collection这里就有一条记录
embedding_fulltext_search:我写入的数据,这里都有
embedding_fulltext_search_content:同上,不过多了一列id
embedding_fulltext_search_data:这个表数据做编码处理了
embedding_metadata:我写入的数据,这里都有,不过又多了几列
…
总结
以上就是今天要讲的内容,本文主要对chroma向量数据库进行了基本介绍,然后又介绍了chroma的安装、连接、创建数据、写入数据、查询数据等。
这篇关于向量数据库Chroma初步了解学习记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





