本文主要是介绍使用深度学习集成模型进行乳腺癌组织病理学图像分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于预训练的VGG16和VGG19架构训练了四种不同的模型(即完全训练的 VGG16、微调的 VGG16、完全训练的 VGG19 和微调的 VGG19 模型)。最初,我们对所有单独的模型进行了5倍交叉验证操作。然后,我们采用集成策略,取预测概率的平均值,发现微调的 VGG16 和微调的 VGG19 的集成表现出有竞争力的分类性能,尤其是在癌症类别上。
交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。
乳房X线摄影、超声成像和磁共振成像(MRI),这些非侵入性成像方法可能无法有效地确定癌变区域。为此,通常采用活检技术来更全面地分析乳腺癌组织的恶性程度。活检过程包括收集组织样本,将其安装在显微镜载玻片上,并对这些载玻片进行染色,以便更好地观察细胞核和细胞质。然后病理学家对这些载玻片进行显微镜分析,以最终确定乳腺癌的诊断。
传统的计算机诊断方法,从基于规则的系统到机器学习技术,可能无法有效地挑战乳腺癌组织病理学图像中的类内变异和类间一致性。此外,这些方法主要依赖于尺度不变特征变换、速度鲁棒特征和局部二值模式等特征提取方法,这些方法都基于监督信息,并且在分类过程中容易出现有偏差的结果乳腺癌组织病理学图像。
局部二值模式是一种用于描述图像中纹理特征的方法。它可以通过比较像素点与其邻域像素点的灰度值,来判断该像素点所属的纹理类型。通过对图像中所有像素点进行局部二值模式计算,可以生成用于分类和检索的特征向量。
首先,我们创建了乳腺癌患者的整个幻灯片图像(WSI)的私有数据集。从WSI图像中提取由非癌和癌类别组成的图像块。值得注意的是,我们的主要目标是优先对癌症类别进行正确分类,微调的VGG16和VGG19方法的集合在非癌症和癌症组织病理学图像的分类中提供了卓越的性能。
相关工作
许多研究利用基于手工特征的方法对与乳腺癌相关的组织病理学图像进行分类。Kowal等人专注于细胞核分割,从500张乳腺癌细针活检图像的分割细胞核中提取了42个形态、拓扑和纹理特征。然后,利用这些特征来训练三个不同的分类器,以便将这些图像分类为良性和恶性类别。
Filipczuk 等人也对细胞核分割表现出兴趣,并从 737 个乳腺癌细胞学图像的分割细胞核中提取了 25 个基于形状和基于纹理的特征。基于这些特征,训练四种不同的机器学习分类器,即KNN(K近邻)、NB(朴素贝叶斯)、DT(决策树)和SVM(支持向量机)来对这些细胞学图像进行分类分为良性和恶性病例。
传统的机器学习方法在分析乳腺癌组织学图像方面取得了令人满意的性能,但其性能主要依赖于训练特征的选择。
材料和方法
预处理
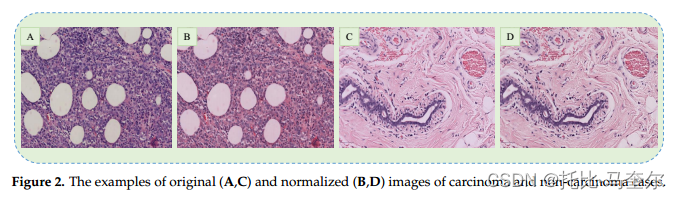
本文使用的数据集包含 H & E 染色的乳腺癌组织病理学图像,该图像广泛用于协助病理学家对组织切片进行显微评估。然而,很难在所有载玻片上保持相同的染色浓度,这导致所获取的图像之间存在颜色差异。这些对比度差异可能会对 CNN 模型的训练过程产生不利影响,因此通常应用颜色归一化。
- 颜色归一化是一种常见的图像预处理技术,其目的是将图像中的颜色值映射到统一的范围,以减少不同图像之间的颜色差异,从而提高计算机视觉算法的性能。
- 图像的直方图指的是图像内灰度值的统计特性与图像灰度值之间的函数,直方图统计图像内各个灰度级出现的次数
原始和标准化癌症图像的示例:
训练标准
对于个体模型和整体模型,我们选择 80% 的图像进行训练,其余 20% 用于测试目的,其中癌症和非癌症图像的比例相同。675 张图像用于训练,其余 170 张图像保留用于测试模型。我们对训练图像使用了 5 倍交叉验证,这意味着使用 540 个图像用于训练,135 个图像用于验证目的。同样,我们在训练和验证中拥有相同比例的非癌症和癌症图像。
数据增强
图像数据增强是一种通过在训练过程中生成修改图像来扩展数据集的技术。通过使用 Keras 深度学习库提供的 ImageDataGenerator,生成具有实时数据增强的批量张量图像数据。
首先,将一批输入图像提供给ImageDataGenerator,然后通过一系列随机平移、旋转等来转换该批次中的每个图像。
我们指定的“旋转范围 = 40”的旋转对应于之间的随机旋转角度[−40, 40] 度。我们还设置“宽度和高度移动范围 = 0.2”,它指定图像随机移动的总宽度分数的上限,宽度向左或向右移动,高度向上或向下移动。
值得注意的是,旋转操作可能会将某些像素旋转出图像帧,并在帧内留下必须填充的空白像素。我们使用“反射模式”来填充这些空像素。反射填充会从图像的边缘开始,按照边缘像素的模式,将像素复制到空白区域。例如,如果图像边缘是垂直的,那么反射填充将复制边缘像素的垂直模式来填充空白区域。这种填充方式可以在一定程度上保持图像的连续性和一致性,避免因为空像素的存在而影响图像的视觉效果。
VGG架构
当数据集与自然图像数据集相比相对较小时,预训练模型通常有助于更好的初始化和收敛。
VGG强化的观念:CNN必须具有深层网络才能使视觉数据的分层表示发挥作用。
VGG16模型的完整框架:五个卷积块组成,每个块都有多个卷积层(带有relu激活)以及一个最大池化层。使用的是步幅和填充都为1的3*3卷积核,以及步幅为2的2*2最大池化层。
VGG19模型的基本框架:基本架构与 VGG16 相同,除了三个额外的卷积层。

VGG16和VGG19分别使用256个节点和128个节点的密集层(每个神经元都会接收来自上一层所有神经元的输入,并根据这些输入和自身的权重计算出输出。这些输出然后会被传递到下一层);最后一层则由二元交叉熵损失函数组成:
集成方法
由微调 VGG16 和微调 VGG19 模型的集成组成,训练图像占全部图像的80%,其中再进行5倍交叉验证,其中的四份用于训练,一份用于模型验证或评估。这些图像都是相互排斥的,而且非癌和癌症的图像百分比相同。
在每个数据子集中,根据损失函数的最小值保存最佳模型的权重。同时为两个模型保存5倍交叉验证的权重。最后,利用测试图像(20%)以概率的形式作出最终预测。两个类别的平均概率是通过取5倍交叉验证的VGG16模型和5倍交叉验证的VGG16模型获得的10个概率值的平均值得出的。考虑两个模型的平均概率,然后将图像分类为非癌或癌。
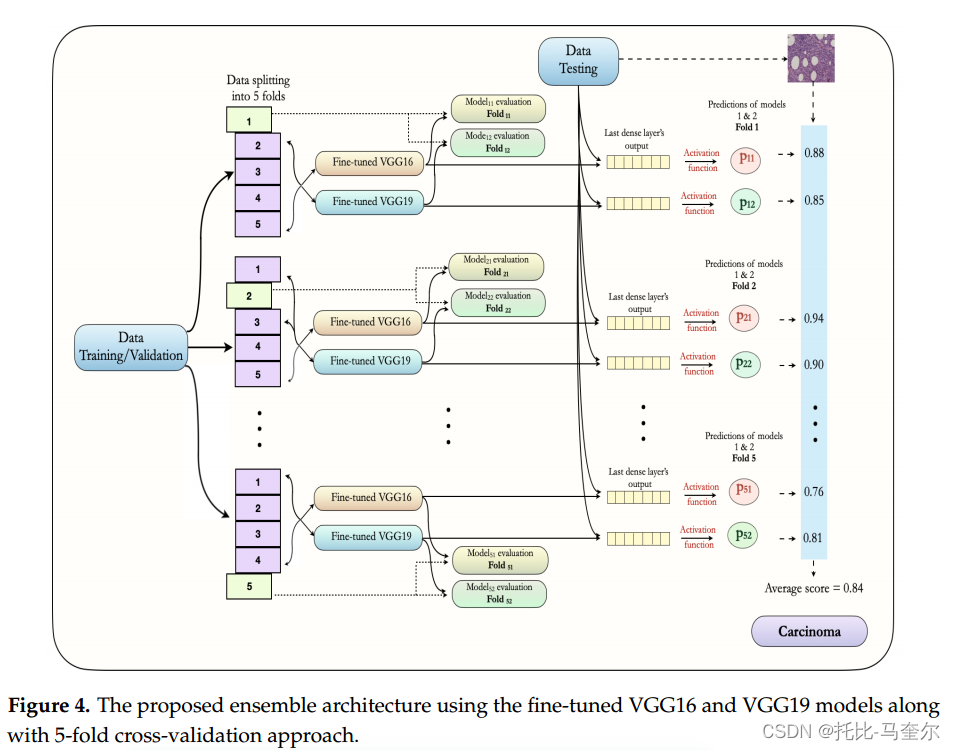
实验装置
超参数调优
神经网络具有自动学习输入和输出之间复杂连接的强大特性。然而,其中的一些连接可能是采样噪声的结果,它们可以是在训练过程中占主导地位,但不可能存在于真实的测试数据集中。这个问题会导致过拟合问题,从而降低深度学习模型的预测性能。
选择最佳超参数的方法:首先,我们选择二元交叉熵作为二元分类问题的损失函数。然后,在训练过程中使用Adam(自适应矩阵估计)算法,以执行200个epoch的优化。在模型训练期间,我们的主要目标是最小化训练损失和验证损失之间的泛化差距,并发现 32 的批量大小与 0.0001 的学习率配合良好。此外,我们使用 0.3 的 dropout 来防止模型在训练过程中过度拟合。通过使用 5 倍交叉验证方法,根据最小验证损失保存了五个最佳模型的权重。最后,我们使用这些权重对测试数据集进行类别预测。
这篇关于使用深度学习集成模型进行乳腺癌组织病理学图像分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






