本文主要是介绍Pytorch导出FP16 ONNX模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一般Pytorch导出ONNX时默认都是用的FP32,但有时需要导出FP16的ONNX模型,这样在部署时能够方便的将计算以及IO改成FP16,并且ONNX文件体积也会更小。想导出FP16的ONNX模型也比较简单,一般情况下只需要在导出FP32 ONNX的基础上调用下model.half()将模型相关权重转为FP16,然后输入的Tensor也改成FP16即可,具体操作可参考如下示例代码。这里需要注意下,当前Pytorch要导出FP16的ONNX必须将模型以及输入Tensor的device设置成GPU,否则会报很多算子不支持FP16计算的提示。
import torch
from torchvision.models import resnet50def main():export_fp16 = Trueexport_onnx_path = f"resnet50_fp{16 if export_fp16 else 32}.onnx"device = torch.device("cuda:0")model = resnet50()model.eval()model.to(device)if export_fp16:model.half()with torch.inference_mode():dtype = torch.float16 if export_fp16 else torch.float32x = torch.randn(size=(1, 3, 224, 224), dtype=dtype, device=device)torch.onnx.export(model=model,args=(x,),f=export_onnx_path,input_names=["image"],output_names=["output"],dynamic_axes={"image": {2: "width", 3: "height"}},opset_version=17)if __name__ == '__main__':main()通过Netron可视化工具可以看到导出的FP16 ONNX的输入/输出的tensor类型都是float16:
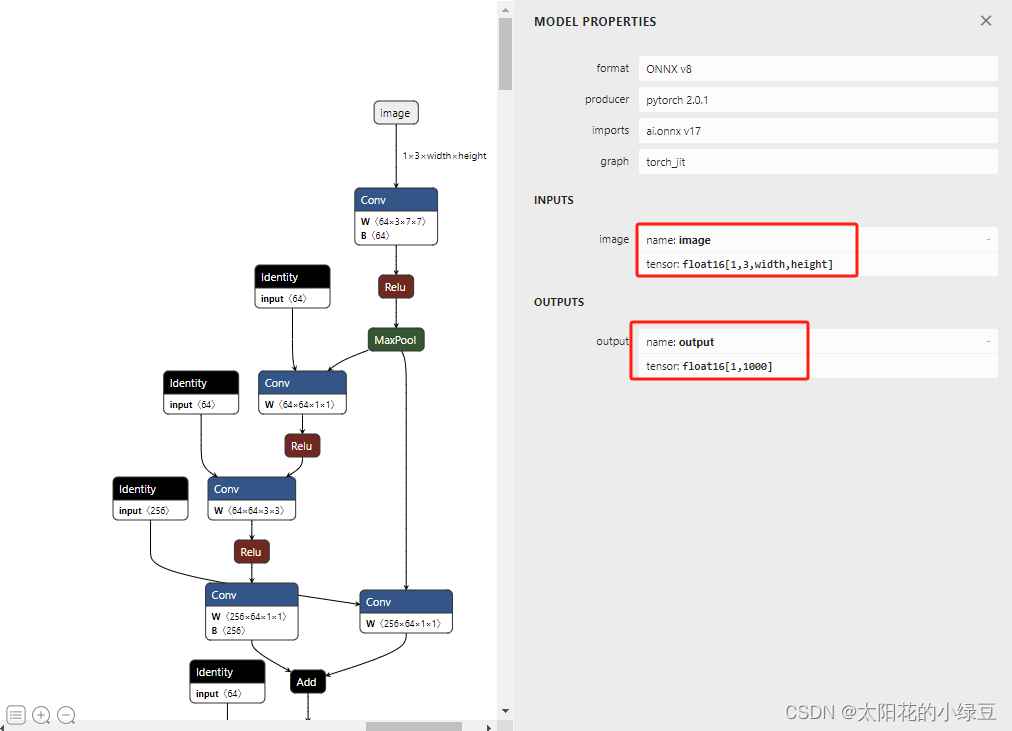
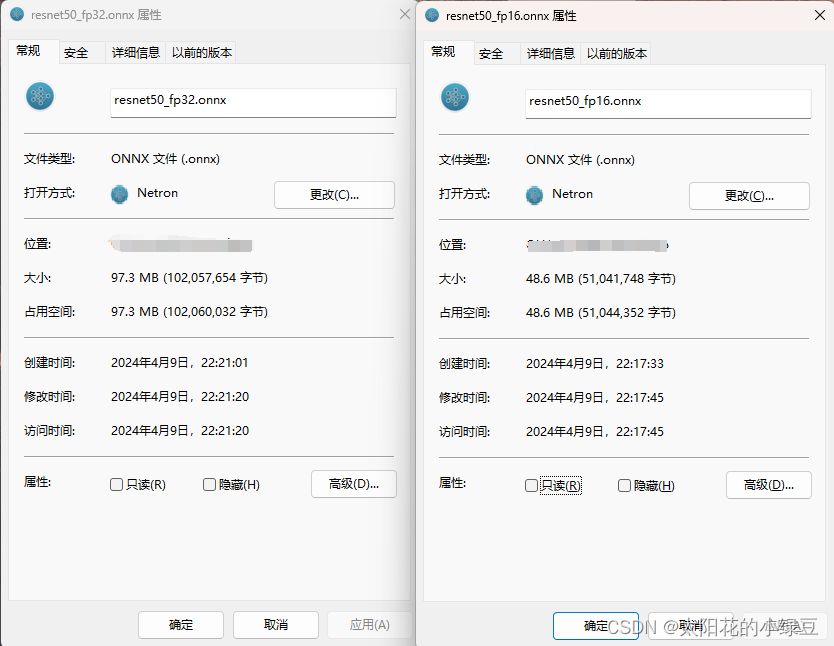
并且通过对比可以看到,FP16的ONNX模型比FP32的文件更小(48.6MB vs 97.3MB)。
大多数情况可以按照上述操作进行正常转换,但也有一些比较头大的场景,因为你永远无法知道拿到的模型会有多奇葩,例如下面示例:
错误导出FP16 ONNX示例
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MyModel(nn.Module):def __init__(self) -> None:super().__init__()self.conv = nn.Conv2d(3, 1, kernel_size=3, stride=2, padding=1)def forward(self, x):x = self.conv(x)kernel = torch.tensor([[0.1, 0.1, 0.1],[0.1, 0.1, 0.1],[0.1, 0.1, 0.1]], dtype=torch.float32, device=x.device).reshape([1, 1, 3, 3])x = F.conv2d(x, weight=kernel, bias=None, stride=1)return xdef main():export_fp16 = Trueexport_onnx_path = f"my_model_fp{16 if export_fp16 else 32}.onnx"device = torch.device("cuda:0")model = MyModel()model.eval()model.to(device)if export_fp16:model.half()with torch.inference_mode():dtype = torch.float16 if export_fp16 else torch.float32x = torch.randn(size=(1, 3, 224, 224), dtype=dtype, device=device)model(x)torch.onnx.export(model=model,args=(x,),f=export_onnx_path,input_names=["image"],output_names=["output"],dynamic_axes={"image": {2: "width", 3: "height"}},opset_version=17)if __name__ == '__main__':main()执行以上代码后会报如下错误信息:
/src/ATen/native/cudnn/Conv_v8.cpp:80.)return F.conv2d(input, weight, bias, self.stride,
Traceback (most recent call last):File "/home/wz/my_projects/py_projects/export_fp16/example.py", line 47, in <module>main()File "/home/wz/my_projects/py_projects/export_fp16/example.py", line 36, in mainmodel(x)File "/home/wz/miniconda3/envs/torch2.0.1/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_implreturn forward_call(*args, **kwargs)File "/home/wz/my_projects/py_projects/export_fp16/example.py", line 17, in forwardx = F.conv2d(x, weight=kernel, bias=None, stride=1)RuntimeError: Input type (torch.cuda.HalfTensor) and weight type (torch.cuda.FloatTensor) should be the same
简单来说就是在推理过程中遇到两种不同类型的数据要计算,torch.cuda.HalfTensor(FP16) 和torch.cuda.FloatTensor(FP32)。遇到这种情况一般常见有两种解法:
- 一种是找到数据类型与我们预期不一致的地方,然后改成我们要想的dtype,例如上面示例是将
kernel的dtype写死成了torch.float32,我们可以改成torch.float16或者写成x.dtype(这种会比较通用,会根据输入的Tensor类型自动切换)。这种方法有个弊端,如果代码里写死dtype的位置很多,改起来会比较头大。 - 另一种是使用
torch.autocast上下文管理器,该上下文管理器能够实现推理过程中自动进行混合精度计算,例如遇到能进行float16/bfloat16计算的场景会自动切换。具体使用方法可以查看官方文档。下面示例代码就是用torch.autocast上下文管理器来做自动转换。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MyModel(nn.Module):def __init__(self) -> None:super().__init__()self.conv = nn.Conv2d(3, 1, kernel_size=3, stride=2, padding=1)def forward(self, x):x = self.conv(x)kernel = torch.tensor([[0.1, 0.1, 0.1],[0.1, 0.1, 0.1],[0.1, 0.1, 0.1]], dtype=torch.float32, device=x.device).reshape([1, 1, 3, 3])x = F.conv2d(x, weight=kernel, bias=None, stride=1)return xdef main():export_fp16 = Trueexport_onnx_path = f"my_model_fp{16 if export_fp16 else 32}.onnx"device = torch.device("cuda:0")model = MyModel()model.eval()model.to(device)if export_fp16:model.half()with torch.autocast(device_type="cuda", dtype=torch.float16):with torch.inference_mode():dtype = torch.float16 if export_fp16 else torch.float32x = torch.randn(size=(1, 3, 224, 224), dtype=dtype, device=device)model(x)torch.onnx.export(model=model,args=(x,),f=export_onnx_path,input_names=["image"],output_names=["output"],dynamic_axes={"image": {2: "width", 3: "height"}},opset_version=17)if __name__ == '__main__':main()使用上述代码能够正常导出ONNX模型,并且使用Netron可视化后可以看到导出的FP16 ONNX模型是符合预期的。
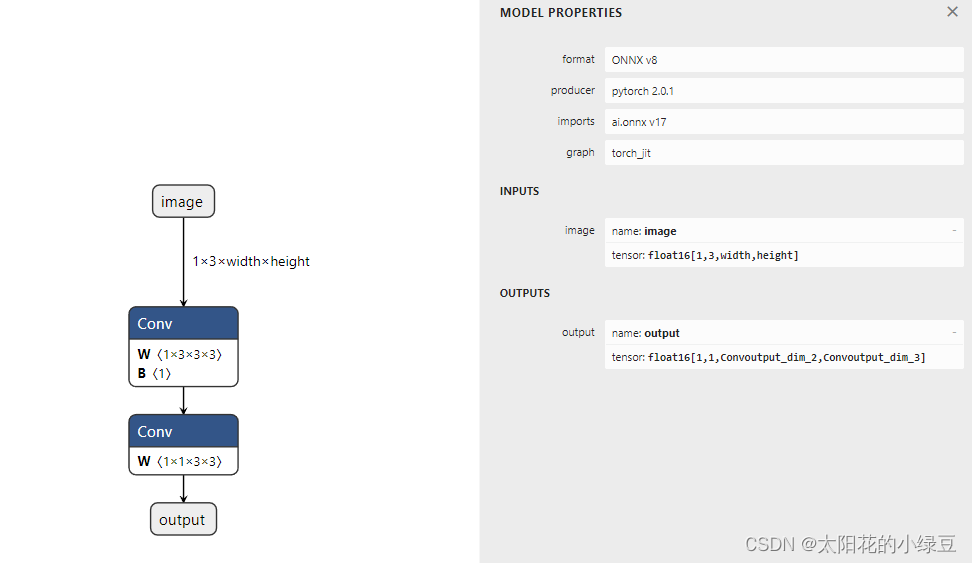
这篇关于Pytorch导出FP16 ONNX模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







