本文主要是介绍ICLR 2024 | 鸡生蛋蛋生鸡?再论生成数据能否帮助模型训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源
发布在https://it.weoknow.com
更多资源欢迎关注

随着生成模型(如 ChatGPT、扩散模型)飞速发展,一方面,生成数据质量越来越高,到了以假乱真的程度;另一方面,随着模型越来越大,也使得人类世界的真实数据即将枯竭。
面对这一处境,一个近期的研究热度是,能否利用生成模型生成的假数据来辅助学习?学界对此也产生了许多争论:到底是可以左脚踩右脚(bootsrap)地实现 weak-to-strong 的不断提升,还是像鸡生蛋、蛋生鸡一样,只不过是徒劳无功?
在近期 ICLR 2024 工作中,北大王奕森团队针对这一「数据扩充」(Data Inflation)问题展开了深入研究。
他们针对对比学习(如 SimCLR、DINO、CLIP)这一常见的自监督学习场景,从理论和实验两方面分析了生成数据对于表示学习能力的影响。为了控制变量,他们保证生成模型和表示学习都只能使用同一个(无监督)真实数据集进行训练,避免了扩充数据本身带来的收益。

-
论文题目:Do Generated Data Always Help Contrastive Learning?
-
论文地址:https://arxiv.org/abs/2403.12448
-
代码地址:https://github.com/PKU-ML/adainf
他们发现,在这种情况下,生成数据并不总是对表示学习有帮助,在很多情况下甚至有害。比如,将 DDPM 的数据直接加入 CIFAR-10 训练,反而导致分类准确率下降超过 1%(前人工作 [1] 也有类似发现:用生成数据扩充 ImageNet 后 ResNet-50 的分类准确率下降了 2.69%)。进一步分析表明,有两个关键因素影响了生成数据的收益:
-
真实数据和生成数据的比例。从人的角度来看,生成数据似乎以假乱真,但对于模型训练而言并非如此。他们发现,真实数据与生成数据的混合比例在 10:1 附近时达到最优,也就是说,1 个真实数据的「训练价值」约等于 10 个生成数据。这侧面说明了二者的差异。
-
训练策略的设计。他们发现,在使用生成数据进行训练时,如果维持原有的训练参数,则模型几乎没有提升。相反,如果随着数据集的扩充,而相应降低模型训练所使用的数据增广的强度,则可以获得显著提升。
针对这两个核心观察,本文还从自监督理论出发,解释了他们内在的产生原因,并进而分析了数据量、数据质量与数据增广强度之间的权衡取舍。
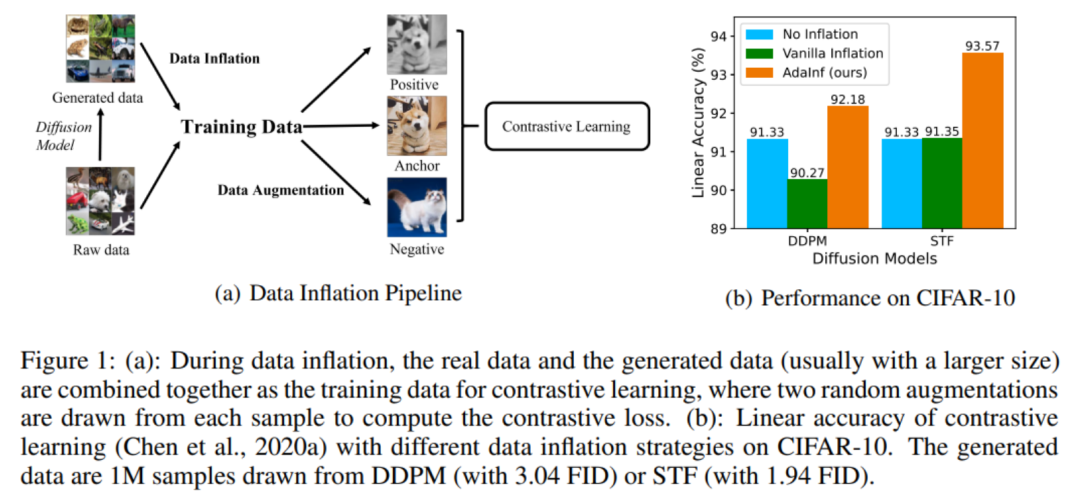
图 1 (a):数据扩充流程 ;(b):不同扩充策略下的对比学习性能。
真实数据比生成数据的「训练价值」
数据扩充最直观的一个影响因素是生成数据的质量问题。下图 2(a)表明,生成数据质量越高,对比学习的下游泛化能力越好,但遗憾的是即使是目前的 SOTA 生成模型 STF,也只让模型的 Linear Accuracy(在特征上应用线性分类器的分类准确率)比此前仅上升 0.02%。由于真实图片包含更丰富、准确的信息,因此扩充后的数据集中真实数据和生成数据的地位不应该相同。本文研究通过在混合时对真实数据复制 N 倍的方式,对真实数据和生成数据进行重加权(Reweighting)。
图 2(b)表明,混合比例在 10:1 时达到最优(weak augmentation)。本文进一步从理论上分析了重加权的作用,在此不做展开。
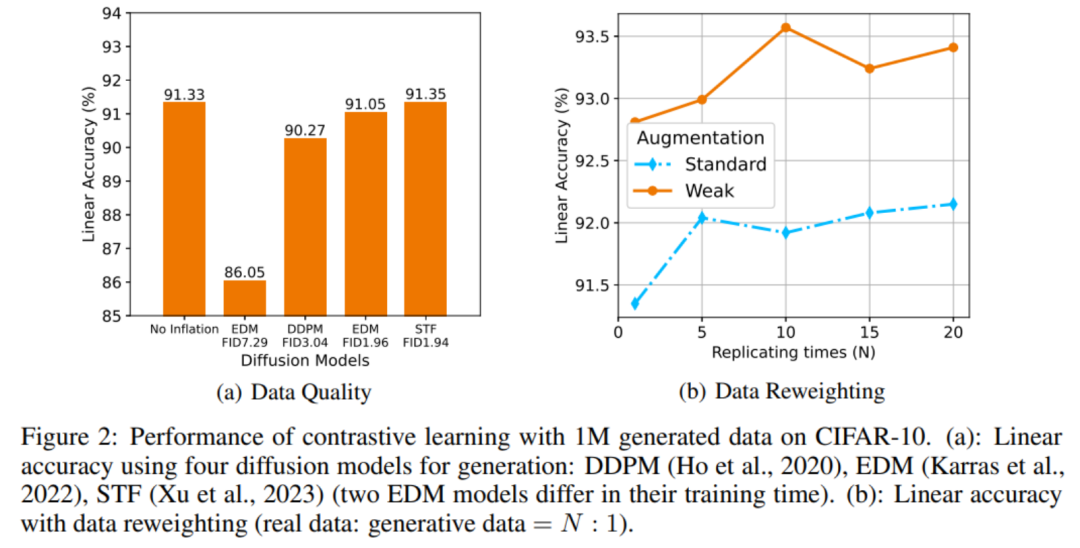
图 2 (a)生成数据质量对对比学习的影响 (b)数据重赋权对对比学习的影响
数据增广与数据扩充,如何权衡?
在对比学习中,数据增强(Data Augmentation)的选取至关重要。通常来说,自监督学习需要使用较强的数据增强(如裁切、掩码等)来学习的数据表示。为了区分,本文将生成数据视为数据扩充(Data Inflation),二者的区别是,数据扩充是扩大原始数据集的大小,而数据增广是对每个原始样本,在训练过程中进行随机增强。
直观上看,数据扩充和数据增广都会提升数据多样性但数据增广可能会改变图像的语义信息(下图 3),因此当数据扩充提供了足够的数据时,便可以减弱数据增广从而减小因图像语义信息的改变带来的误差。
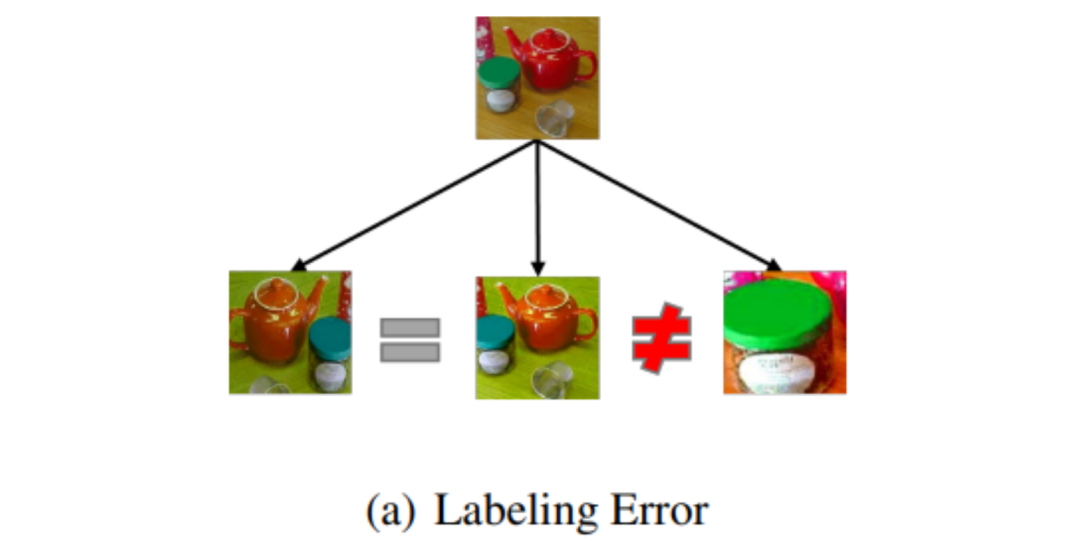
图 3 数据增强可能改变图片的语义信息
文中构造了四个不同规模的数据集:CIFAR-10、Half CIFAR-10(CIFAR-10 的一半)、CIFAR-10+10 万张生成图片、CIFAR-10+100 万张生成图片,通过改变 random resized crop(RRC)来反应不同的数据增广强度。
下图 4 中表明最优数据增广强度随着数据规模的增大而减小(Half CIFAR-10:0.02,CIFAR-10:0.08,CIFAR-10+0.1M:0.20,CIFAR-10+1M:0.30)。因此当进行数据扩充时,数据增广强度需要减弱。也就是说,只有当二者搭配得当,才能充分发挥生成数据的作用。
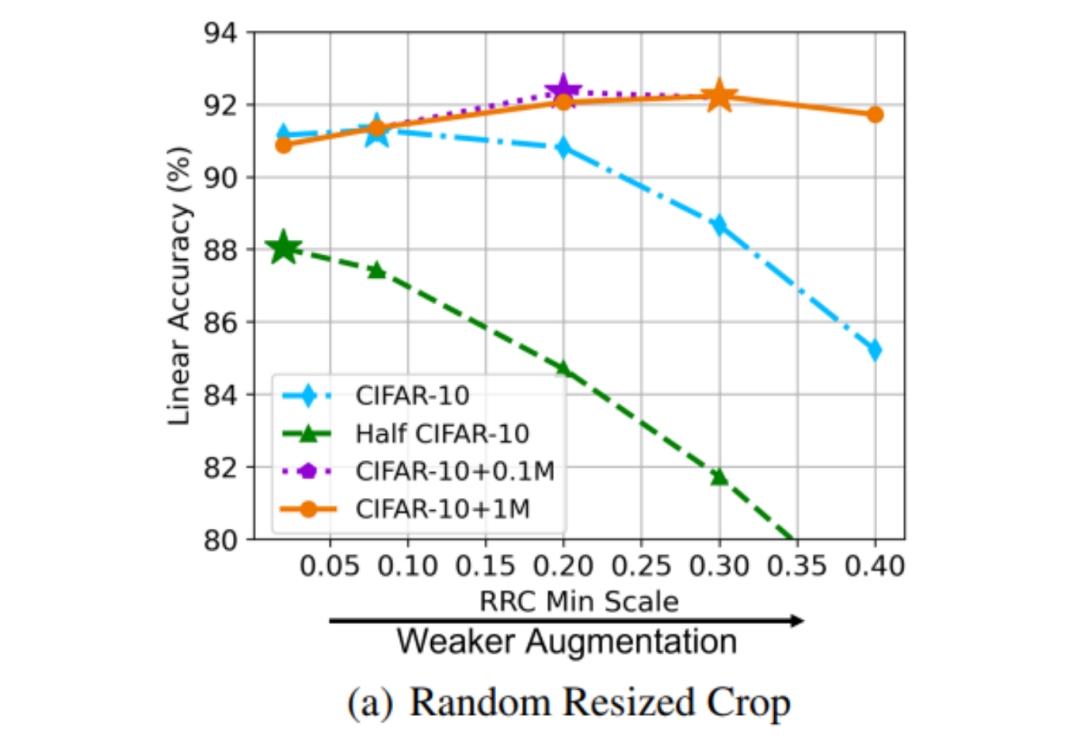
图 4 数据量和数据增广强度的关系
基于增广图的理论理解

数据扩充后的下游泛化误差上界
为了进一步刻画数据扩充和数据增广之间的关系,本文从图的角度来建模对比学习:将数据增强产生的每个样本视为图 上的节点,并定义同一样本产生的数据增广样本之间存在一条边,这样便在样本空间构建了一个图,称为增广图(Augmentation Graph)[2,3]。
这是理解自监督学习的经典理论之一,根据这一建模,对比学习的下游泛化误差上界可表示为
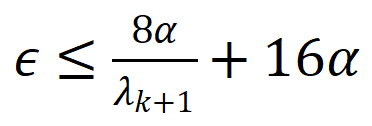
,其中
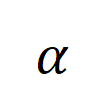
表示由于数据增强造成的标签错误(labeling error),
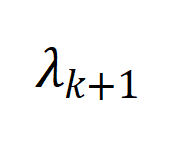
表示增广图拉普拉斯矩阵的第
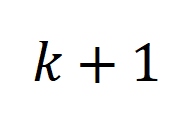
小的特征值,用于反应图的连通性。
数据扩充和数据增广对
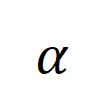
和
的影响:
-
数据扩充:不会改变标签错误
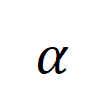
,但可以提升图的连通性(
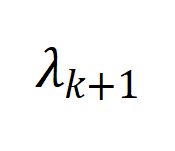
增大)(下图 5 (a))。
-
数据增广:数据增广强度增加,会使得 labeling error
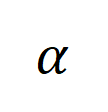
增大(图 5 (b)),但同时使不同样本之间的交叠部分增加,即增广图的连通性增强(
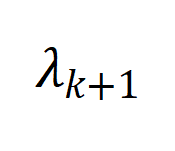
增大)(图 5 (c))。
因此当数据扩充提升数据规模从而提供了足够的图的连通性时,为了进一步减小下游泛化误差,可以减弱数据增广强度从而使得 减小。反之数据规模比较小时,则需要更强的数据增强去获得更好的图的连通性。也就是说,数据扩充和数据增强在对比学习中存在互补作用,当数据扩充后,对应的最优数据增广强度减小(图 5(d))。

图 5 数据扩充和数据增广对 labeling error
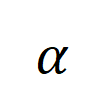
和图
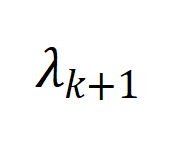
的连通性的影响
基于以上的理解,论文提出自适应的数据扩充 Adaptive Inflation(AdaInf),根据生成数据的质量、大小,动态调整对比学习算法。其中,最重要的两个指导原则是 1)真实数据和生成数据需赋予不同权重,生成数据质量越差权重应该越小;2)数据量增大后,应该减弱数据增广强度,减少数据增强的负面作用。
实验结果
本文主要考虑生成数据的规模远大于真实数据的应用场景。为了在计算能力有限的情况下分析这一场景,作者主要考虑 CIFAR 数据集,因为可以在该数据集上采样大量图片。
以 CIFAR-10 为例,其中包含 5 万真实训练样本,作者利用生成模型(GAN 或扩散模型)为它们添加 100 万生成数据。以 10:1 的比例混合之后,作者将 CIFAR 数据集的总规模扩充到 150 万。为了公平比较,本文保证全训练过程中,生成模型也只能获取 5 万无监督数据。作者采用 SimCLR 作为默认方法并保持默认参数。

表 1 不同模型和不同数据集下的对比学习线性探测性能
本文在图像识别任务上表 1 表明,AdaInf 在不同的对比学习模型和不同数据集上的性能显著好于没有数据扩充(No Inflation)或者直接进行数据扩充(Vanilla Inflation)。仅使用基础的 SimCLR 方法,AdaInf 就可以将 ResNet-18 上的自监督性能从 91.56 提升到 93.42,超越了大部分「魔改」的自监督学习方法,达到 Sota 水平。这进一步验证了「数据为王」的规律,展示了 scaling 的潜力。
消融实验:本文在下表 2 (a)中研究了 AdaInf 的组成部分:生成数据、数据重赋权、数据弱增广。结果表明三者的重要性为数据弱增广 > 数据重赋权 > 生成数据。这反映了数据扩充和数据增广之间的相互作用对于对比学习的影响很大。
应用场景:作者进一步发现, AdaInf 可以很好地应用的数据缺乏的场景下。如表 2 (b)所示,当 CIFAR-10 每个类仅有 500 个样本时,AdaInf 可以获得更明显的提升。
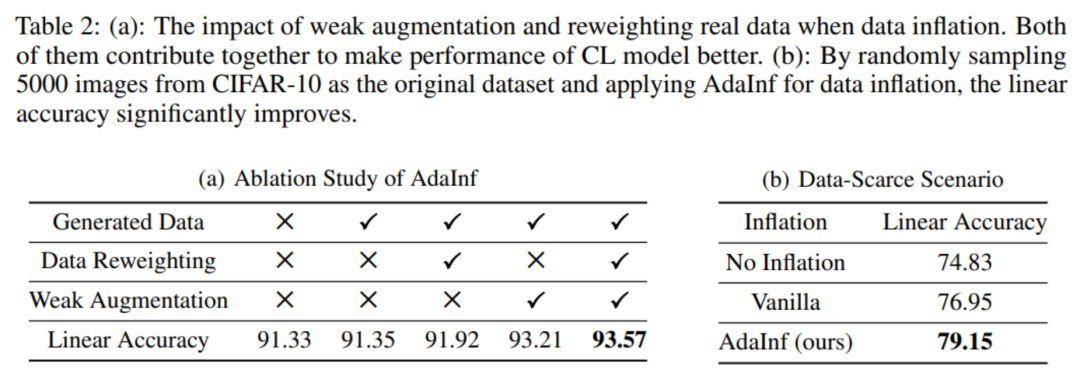
表 2 (a)消融实验 (b)数据匮乏场景下的应用
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源
发布在https://it.weoknow.com
更多资源欢迎关注
这篇关于ICLR 2024 | 鸡生蛋蛋生鸡?再论生成数据能否帮助模型训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






