本文主要是介绍算法设计课第一周(排序算法的效率分析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验1 排序算法的效率分析
一、【实验目的】
(1)复习排序算法的实现过程;
(2)设计平均与最坏情况下时间复杂度的数据环境并理解相关含义;
(3)初步了解算法时间复杂度的分析方法。
二、【实验内容】
至少选择3种排序算法(建议选择直接插入、快速和二路归并),要求对每种排序算法设计2组数据,其中一组为最坏情况,一组为一般情况(随机),数据规模不能少于10000。
记录不同情况下算法的实际运行时间(#include <time.h> ,clock()函数计时),同时分析算法最坏情况与平均情况的运行次数。
三、实验源代码
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define RANDNUM 10000//随机数的个数void quickSort(int a[], int low, int high)//快速排序
{if (low >= high)return;int left = low, right = high;int p = a[left];while (left < right){//大于p值就不动while (left < right && a[right] >= p){--right;}//把比基准值小的放左边if (a[right] < p){a[left] = a[right];} //小于p值就不动while (left < right && a[left] <= p){++left;}//把比基准值大的放右边if (a[left] > p){a[right] = a[left];} } //插进中间的空位if (left >= right){a[left] = p;//break;}//对左右部分进行递归quickSort(a, low, left-1);quickSort(a, left+1, high);
}void shellsort(int a[],int n)//希尔排序
{int d, i, j; //希尔增量for(d = n/2; d >= 1; d /= 2) //趟{for(i = d+1; i <= n; i++){if(a[i] < a[i-d]){a[0] = a[i]; //a[0]作为temp,保存数据for(j = i-d; j > 0 && a[0] < a[j]; j =j - d)a[j+d] =a[j]; //j+d 相当于 ia[j+d]=a[0]; //放回i中}}}
}void insertSort(int a[], int n)
{int i, j;int temp;for(i = 0; i < n-1; i++){temp = a[i+1];j = i;while(j > -1 && temp < a[j]){a[j+1] = a[j];j--;}a[j+1] = temp;}
}int main()
{int i;double total_t;int iRandNum1[RANDNUM], iRandNum2[RANDNUM], iRandNum3[RANDNUM];//存放随机数clock_t first, second; //记录开始和结束时间(以毫秒为单位)for(i=0; i<RANDNUM; i++){//产生1万个随机数iRandNum1[i] = rand()%RANDNUM;iRandNum2[i] = iRandNum1[i];iRandNum3[i] = iRandNum1[i];}first = clock(); //开始时间//此处加入排序程序quickSort(iRandNum1, 0, RANDNUM - 1);second = clock();//结束时间//显示排序算法所用的时间total_t = (double)(second - first) / CLOCKS_PER_SEC;printf("快速排序所需时间:%lf\n", total_t);first = clock(); //开始时间//此处加入排序程序insertSort(iRandNum2, RANDNUM - 1);second = clock();//结束时间//显示排序算法所用的时间total_t = (double)(second - first) / CLOCKS_PER_SEC;printf("插入排序所需时间:%lf\n", total_t);first = clock(); //开始时间//此处加入排序程序shellsort(iRandNum3, RANDNUM - 1);second = clock();//结束时间//显示排序算法所用的时间total_t = (double)(second - first) / CLOCKS_PER_SEC;printf("希尔排序所需时间:%lf\n", total_t);printf("\n");
}
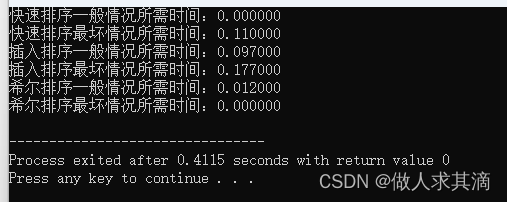
四、实验结果
数据量太少,或者时间太短都有可能输出0.000000
这篇关于算法设计课第一周(排序算法的效率分析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





