本文主要是介绍Apriori算法(频繁集发现以及关联分析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们在网上购物的时候都会收到一些相关产品的推荐,这些被推荐的东西是怎么来的呢?如果我们买了一个鱼竿,那么推荐鱼线,鱼饵什么的是很正常的,毕竟这些产品都是相关性比较大的,收到推荐也不足为奇;但是仅限于此吗?之前不是有个很出名的例子,啤酒和尿布的例子,在没被发现这个规律之前,谁能想到他们两个有一定的联系?所以除过去那些关联性特别明显的东西,还有许多隐藏的有相关性的关系被隐藏在大量的数据之下。所以,从大规模数据集中寻找物品间的隐含关系被称作为关联分析或者关联规则学习。
关联分析也可以用于特征的发现,发现某些事情的共性规则,即同时有哪些特征出现,例如发现毒蘑菇的共同特征。
1.关联分析
关联分析是一种在在大规模数据集中寻找有趣关系的任务。这些关系可以分为两种形式:频繁项集合关联规则。
频繁项集:是经常出现在一块儿的物品的集合;
关联规则:暗示两种物品之间可能存在很强的关系。
表1是一个购物清单
表1
| 交易号码 | 商品 |
| 0 | 豆奶,莴苣 |
| 1 | 莴苣,尿布,葡萄酒,甜菜 |
| 2 | 豆奶,尿布,葡萄酒,橙汁 |
| 3 | 莴苣,豆奶,尿布,葡萄酒 |
| 4 | 莴苣,豆奶,尿布,橙汁 |
频繁项集是指那些经常出现在一起的物品集合,如表1中的{尿布,葡萄酒}就是一个很好的例子,就是说人们经常会把尿布和葡萄酒一起购买。
我们用支持度来衡量这个集合出现的频繁度,它被定义为数据集中宝行该项集的记录所占的比例。从表1中可以得到,{豆奶}的支持度为4/5,有3条包含{豆奶,尿布}的记录,一次{豆奶,尿布}的支持度为3/5,因此我们可以指定一个支持度,从而过滤掉那些支持度小的集合。
可信度或者说是置信度是针对一条诸如{尿布}->{葡萄酒}的关联规则定义的,有很强的方向性,箭头反过来就不一定成立。上面箭头关联规则可定义为:支持度({尿布,葡萄酒})/支持度({尿布}),{尿布,葡萄酒}的支持度为3/5,尿布的支持度为4/5,所以{尿布}->{葡萄酒}的可信度为3/4=0.75。可以这么理解:尿布和葡萄酒同时出现的概率比上尿布单独出现的概率,即在尿布出现的情况下,葡萄酒出现的概率,从而衡量尿布出现的情况下,葡萄酒出现可能性的大小。
2.Apriori原理
在进行频繁集发现的时候,我们需要从小的集合开始,为什么呢?我们看图2:
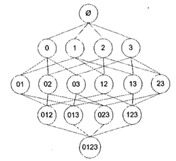 图2
图2
假如我们有4样商品,那么进行不同大小的集合的组合,一共有15种组合方式,那我们就需要进行15次的判断。那么有N种商品,我们就需要2的N次方-1种的组合,那么这种指数级的增长必定会加大运算量,所以我们需要想办法减少判断的组合。
假设我们从小集合开始判断,判断出{3}的支持度比较低,也就是在样本数据中出现3的次数比较少,那么12,13,23…等组合都是包括3的,那么他们的支持度是不会比3大的,也就是说如果小集合的支持度比较小,那么包含小集合的大集合也就不需要判断了,那么这就大大减少了判断的成本,也就降低了计算成本。所以我们就可以运用这个原理来发现频繁集。
3.使用Apriori算法来发现频繁集
Apriori算法使用Apriori原理来发现频繁集。我们需要输入最小支持度和数据集,通过最小支持度对数据集进行过滤,得到频繁集。
我们首先
这篇关于Apriori算法(频繁集发现以及关联分析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






