本文主要是介绍数据库容器化|未来已来,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【导语】“你不是不够好,你只是过时了”这句话用到 IT 行业特别合适,每隔一段时间都会有新的技术出现, 让码农们应接不暇。借着回顾DBA工作中的几个时期,跟大家分享我们对下一代数据库运维架构的理解和目前正在做的工作。
明星 DBA 层出不穷的时期
刚进入阿里时听过一句话一直记到现在,“要像了解自己的老婆一样了解自己管理的数据库”。当年我还没有结婚,对这句话的理解并不深刻。
这应该是@冯春培说的,当年进阿里的面试考官之一,大家都服气的称他为大师。
这句话后面其实隐含了一个背景:相比现在,当时的应用迭代较慢,架构集中,尤其是在数据库层面,用比较流行的叫法是巨石型“monolithic”应用。

在数据库数量、容量和业务需求都没有爆发的情况下,更需要 DBA 做出极致的优化,更强调对数据库内核的掌握,10年前混过 ITPUB 的都知道,当时的 DBA 都是以写出极其复杂的 SQL 和掌握 Lock、Pin、Latch 运行机制为荣的。
还记得,当年每条 SQL 上线都需要 DBA 审阅,这也是 DBA show muscle的最好机会。
巨石型应用突出了DBA 的重要性,那是一个明星 DBA 层出不穷的时期。
DBA 的转型期
后来有机会去了百度,作为一名 DBA ,给我的冲击很大,总结下来有几个不同:
-
数据库以 MySQL 为绝对多数,并且大多数都是由开发自己运维
-
DBA 团队刚刚组建,目标是集中管理集团的所有数据库。当时整个团队不到15人,线上运行的 MySQL 实例1000+
-
没有 SQL Review
1000+实例和15个 DBA,这时我刚结婚,虽然时间不长,但我马上意识到 “要像了解自己的老婆一样了解自己管理的数据库”恐怕是做不到了。
工作的重点不再是学习数据库内核和SQL Review, 而是转而将大量的日常运维工作脚本化,自动化(其实是人肉+半自动)。当时没有Puppet/Ansible,一刀一斧都得自己来,不得已, 又捡回编程的手艺。这个时候, 我从关注少量库的性能 (Load, TPS, QPS),到关注大量库的可用性,主要包括:
-
监控的配置和有效性
-
空间是否足够
-
备库恢复是否正常
-
是否有备份, 备份是否有效
-
硬件是否有故障
没有SQL Review这样奶妈式的贴身服务,如何能解决性能问题呢?总结下来就是:
-
将复杂的SQL拆分成多个简单的 SQL, 将复杂性留给应用
-
做好Scale Out的架构, 性能不够就扩节点
多说几句:
-
Scale Out:要支持Scale Out架构,应用需要做些改造。说一个常见的问题, MySQL集群的各个分片如何高效的,不重复的获取自增序列作为 PK 或者 UK 呢? 在 Oracle Rac 里面,sequence让一切变得简单,DBA 关注的只是如何优化获取 sequence 的效率。但是在百度,我第一次知道原来可以通过 zookeeper 解决这个问题。
-
监控:当时 Noah (百度内部的告警平台) 有个功能, 一旦发现线上运行的服务器负载低于指定阈值时, 将会给相关人发送报警,提示有资源浪费。这个报警追踪了资源的使用情况,有效的防止了资源浪费的问题。
- SQL Review,:从阿里巴巴集团研究员@张瑞(两个面试官中另外一个)发表的题为《面向未来的数据库体系架构的思考》可以看到类似的描述:

我也逐渐意识到对 DBA 的要求发生了变化。从精细化运维到集群化运维,从关注个别库的性能到关注集群的可用性,从依靠个人的能力到借助监控平台和大量的运维脚本。
这是一个转型期,对DBA的要求更综合,更全面,不会当厨子的裁缝做不了好司机。
拥抱虚拟化
2017年,WoquTech 已经成立6年,巨石型 “monolithic”应用依然广泛存在。同时,用户对于数据库运维自动化的要求越来越高,数据库即服务(DBaaS or RDS)的需求越来越强烈,AWS RDS 有个很精炼的总结:

总结一下:
-
所有的日常运维工作自动化
-
高性能,数据零丢失,安全的需求依然是刚需
-
通过弹性扩展追求更高的资源利用率(用我们熟悉的语言就是向运维要效益)
-
不再追求极致的高性能
如何满足这些企业级的功能要求?这并不容易,要对数据库,硬件,虚拟化,分布式存储等技术都要熟悉甚至精通。
以此为目标,WoquTech首先基于虚拟化技术实现了一套私有数据库服务平台,这款产品叫做QFusion,目前迭代至2.0版本。与此同时,我们也面临了一些棘手的问题:
-
计算密度难以提高:虚拟化自身开销较大, 导致计算资源的有效利用率不高,进而导致用户需要更多的硬件
-
存储开销较大:存储在硬件(SSD,Optane),网络(25Gb,Infiniband),协议层面(NVMEoF)的变化巨大,但是虚拟化技术一直支持得不好,开销很大。虽然可以通过穿透技术(passthrough)降低开销,但是又给平台管理带来极大成本。
-
调度算法单一:我们期待调度算法能够感知硬件架构、存储架构以应对不同的高可用架构和备份策略
-
迭代成本高:还是以 OS 的视角建构系统, 导致业务开发的成本较高
奔向容器,未来已来
面对虚拟化技术在实现RDS上的短板,我们一直在探索,资源利用率更高、整合效率更高的RDS实现方式。
所以我们很早就开始了探索容器化的方向。容器和 MySQL 本来就不陌生,阿里很早就将 cgroup 应用到 MySQL 生产环境(Google与阿里的用法非常相似)。Oracle 作为商用数据库的霸主,虽然慢一些,但也在 github.com 上推出12C 企业版 Docker image。
当然,在生产环境使用容器并不容易。以 Docker +Oracle 为例,我们需要解决两个问题 :
-
数据库如何高效的运行在 Docker 里
-
如何管理大规模的Docker
针对第一个问题,我们进行了长期研究和多次测试。期望在使用相同 Oracle 版本,硬件配置,负载模型的情况下,以TPS和QPS为指标,对 Oracle in KVM 和 Oracle in Docker 进行对比。
调试了很长时间以确保 KVM 和 Docker 都能充分发挥自身的优势。IBM在2014年发表的文章《An Updated Performance Comparison of Virtual Machines and Linux Containers》给了我们很多启发。
数据如下:
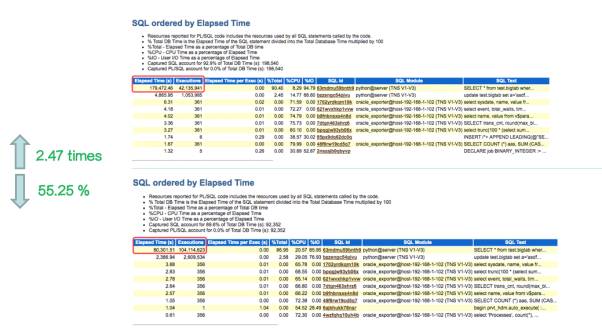
通过 Oracle 的 AWR 报告,可以很清晰的看到,相比KVM,Oracle in Docker 的执行次数提高2.47倍,同时运行时间减少55.25%,也就是说基于Docker,不但可以提升一倍的业务服务质量,还能够提高2.47倍的业务吞吐量,优势非常明显。
针对问题二,如何管理大规模的Docker?就像虚拟化和 OpenStack 的关系。我们需要容器化时代的 “OpenStack”,甚至更多,以调度策略为例:
-
更细粒度的资源调度单位, 更弹性的资源申请方式, 以实现更高的部署密度
-
识别不同级别的存储服务(QoS). 比如, 主库调度到 PCIe Flash节点, 备库调度到SATA SSD节点, 备份调度到Hard Disk节点
-
识别业务需要的非亲缘性. 比如, 在资源都满足的前提下, 主库和备库不能调度到同一物理节点
站在巨人(Google)的肩膀上,我们找到了答案:Kubernetes。
简单说,Kubernetes是自动化容器编排平台(https://kubernetes.io/). 其隶属于 CNCF基金会 (Cloud Native Computing Foundation https://www.cncf.io/), CNCF 背后有强大的 Google 站台.Kubernetes 一经推出,Kubernetes被大家接受的速度远超想象。
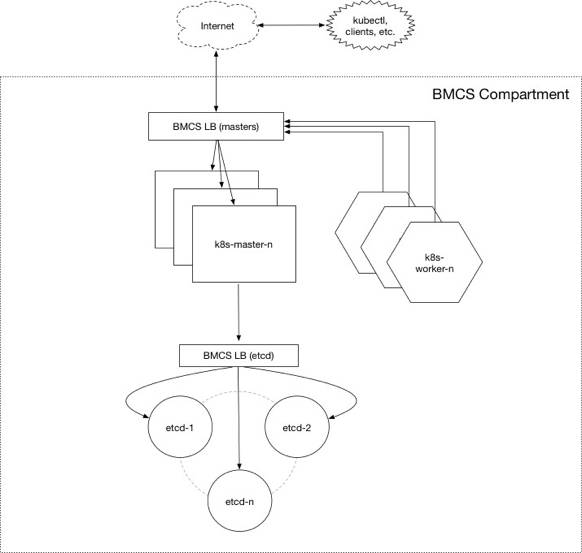
Oracle云服务集成了基于Kubernetes的编排架构

微软云服务 Azure 把自己容器编排引擎从 ACS改成 AKS
通过整合 Docker和Kubernetes研发WoquTech下一代的RDS架构即QFusion 3.0,成为我们的新目标。
目前,Kubernetes对持久化应用的支持还刚刚起步,下图是基于 Kubernetes 构建的持久化服务:
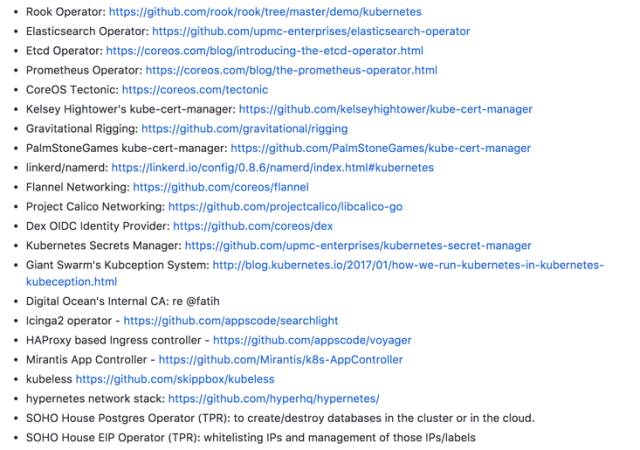
可以看到,暂时还没有Oracle和MySQL的身影,基于 Kubernetes 构建关系型数据库业务的难度也可想而知。
下面将会展示QFusion 3.0的 (全部以 MySQL 为例 ) 几个功能。
实例高可用
实例高可用必不可少,需要说明的是这个功能必须包含数据零丢失。下面将演示这个过程。
我们共模拟了四次故障,例如 kill、重启节点之类,平均下来都可以在35秒内恢复访问(消耗时间与 AWS Aurora 和阿里云 PolarDB 持平):
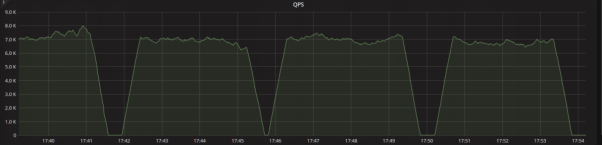
同时模拟应用进行持续的数据更新操作,可以看到数据库服务在几次故障切换后始终可以保证更新有序,做到零数据丢失:
读写分离集群:读库水平扩展
大多数应用都是读多写少,读写分离集群很好的支持了这类业务场景。当读能力不足时,弹性扩展是 DBA 经常遇到的问题,下面将演示读库水平扩展的过程。
通过 YAML 文件, 以申明的方式一键创建读写分离集群:
无关内容已省略
kind: MysqlCluster
masterdbspec:
replicas: "1" -- 主库数量, 读写分离集群中, 该值只能为1
role: Master -- 主库角色
proxyspec:
role: RW -- 数据库中间件类型
slavedbspec:
replicas: "3" -- 读库数量
role: Slave -- 读库角色
strategy: MySQLRWCluster -- 集群类型
通过 sysbench + Proxy 模拟对3个备库的压力:

通过我们的平台一键式添加1个备库, 可以看到读压力较平均的分散到4个备库中:

分库分表集群:集群高可用
这类集群提供了Scale Out 的能力, 相比读写分离集群功能更加强大, 同时也带来了运维的复杂性. 下面将演示集群的一键式创建和集群分片的高可用。
通过 YAML 文件, 以申明的方式一键创建分库分表集群:
无关内容已省略
kind: MysqlCluster
masterdbspec:
replicas: "8" -- 主库数量, 指定该集群的分片数量
role: Master -- 主库角色
proxyspec:
role: Sharding -- 数据库中间件类型
strategy: MySQLShardCluster -- 集群类型
一键创建8分片集群:
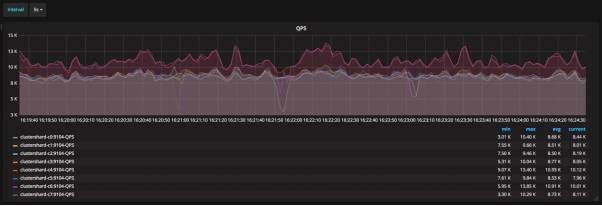
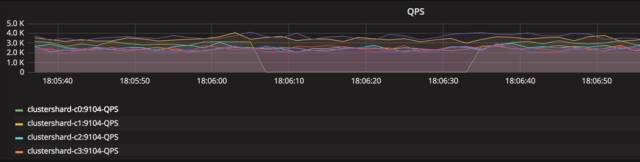
模拟分片0故障,35秒内该分片恢复完毕,提供服务:
分库分表集群:滚动升级功能
集群带来了强大功能的同时提升了运维工作的复杂度。比如,修改数据库配置, 替换新的数据库版本,常见的做法就是DBA 人肉的一个节点一个节点的完成变更工作。下面将演示全自动滚动升级功能。
修改集群所有实例的参数 “innodb_buffer_pool_size”, 滚动升级会:
-
降序从 c7 到 c0
-
依次进行 : 选定节点, 修改参数文件, 重启节点, 待节点恢复服务
-
滚动升级流程会保证即使出现异常, 依然可以”断点续传”, 已升级节点不会重复操作
5.7.5开始,innodb_buffer_pool_size可以通过 set 命令动态调整,不用重启数据库实例。
下面可以看到滚动升级的过程:
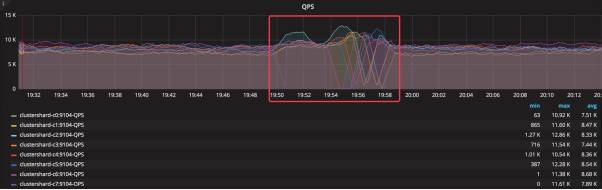
通过版本管理的方式实现集群的滚动升级, 通过集群信息,可以看到:
status:
currentReplicas: 8 -- 当前版本分片数量
currentVersion: clustershard-c-559586746c -- 集群当前版本
updateVersion: clustershard-c-559586746c -- 集群待升级版本
currentVersion等于updateVersion,滚动升级结束。
Docker,Kubernetes,RDS,未来已来。
Everyonce in a while, a revolutionary product comes along that changes everything.这是乔帮主在第一代 iphone 发布会上说的第二句话。
确实,未来已经到来。
作者:熊中哲,沃趣科技联合创始人。
这篇关于数据库容器化|未来已来的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







